 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAWX: A Hardware-Aware FrameWork for Fast and Scalable ApproXimation of DNNs
Feb 18, 2026This work presents HAWX, a hardware-aware scalable exploration framework that employs multi-level sensitivity scoring at different DNN abstraction levels (operator, filter, layer, and model) to guide selective integration of heterogeneous AxC blocks. Supported by predictive models for accuracy, power, and area, HAWX accelerates the evaluation of candidate configurations, achieving over 23* speedup in a layer-level search with two candidate approximate blocks and more than (3*106)* speedup at the filter-level search only for LeNet-5, while maintaining accuracy comparable to exhaustive search. Experiments across state-of-the-art DNN benchmarks such as VGG-11, ResNet-18, and EfficientNetLite demonstrate that the efficiency benefits of HAWX scale exponentially with network size. The HAWX hardware-aware search algorithm supports both spatial and temporal accelerator architectures, leveraging either off-the-shelf approximate components or customized designs.
Edge-MultiAI: Multi-Tenancy of Latency-Sensitive Deep Learning Applications on Edge
Nov 14, 2022



Smart IoT-based systems often desire continuous execution of multiple latency-sensitive Deep Learning (DL) applications. The edge servers serve as the cornerstone of such IoT-based systems, however, their resource limitations hamper the continuous execution of multiple (multi-tenant) DL applications. The challenge is that, DL applications function based on bulky "neural network (NN) models" that cannot be simultaneously maintained in the limited memory space of the edge. Accordingly, the main contribution of this research is to overcome the memory contention challenge, thereby, meeting the latency constraints of the DL applications without compromising their inference accuracy. We propose an efficient NN model management framework, called Edge-MultiAI, that ushers the NN models of the DL applications into the edge memory such that the degree of multi-tenancy and the number of warm-starts are maximized. Edge-MultiAI leverages NN model compression techniques, such as model quantization, and dynamically loads NN models for DL applications to stimulate multi-tenancy on the edge server. We also devise a model management heuristic for Edge-MultiAI, called iWS-BFE, that functions based on the Bayesian theory to predict the inference requests for multi-tenant applications, and uses it to choose the appropriate NN models for loading, hence, increasing the number of warm-start inferences. We evaluate the efficacy and robustness of Edge-MultiAI under various configurations. The results reveal that Edge-MultiAI can stimulate the degree of multi-tenancy on the edge by at least 2X and increase the number of warm-starts by around 60% without any major loss on the inference accuracy of the applications.
FELARE: Fair Scheduling of Machine Learning Applications on Heterogeneous Edge Systems
Jun 09, 2022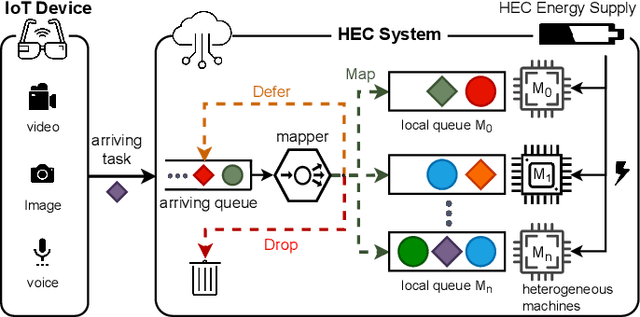
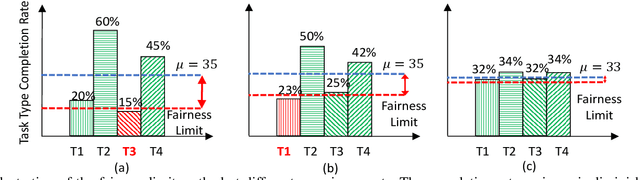
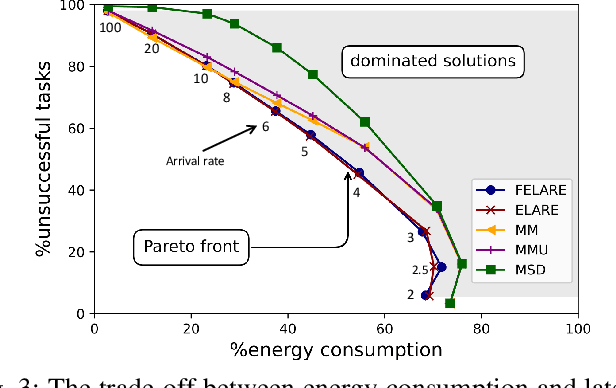
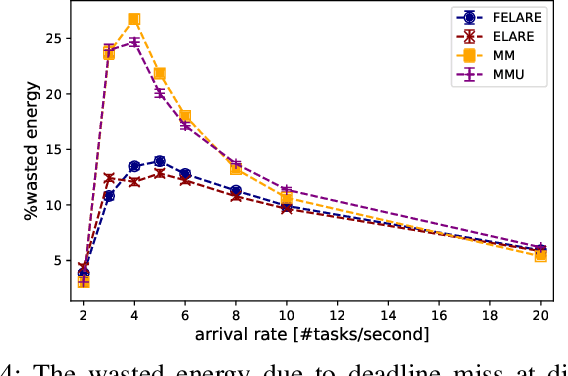
Edge computing enables smart IoT-based systems via concurrent and continuous execution of latency-sensitive machine learning (ML) applications. These edge-based machine learning systems are often battery-powered (i.e., energy-limited). They use heterogeneous resources with diverse computing performance (e.g., CPU, GPU, and/or FPGAs) to fulfill the latency constraints of ML applications. The challenge is to allocate user requests for different ML applications on the Heterogeneous Edge Computing Systems (HEC) with respect to both the energy and latency constraints of these systems. To this end, we study and analyze resource allocation solutions that can increase the on-time task completion rate while considering the energy constraint. Importantly, we investigate edge-friendly (lightweight) multi-objective mapping heuristics that do not become biased toward a particular application type to achieve the objectives; instead, the heuristics consider "fairness" across the concurrent ML applications in their mapping decisions. Performance evaluations demonstrate that the proposed heuristic outperforms widely-used heuristics in heterogeneous systems in terms of the latency and energy objectives, particularly, at low to moderate request arrival rates. We observed 8.9% improvement in on-time task completion rate and 12.6% in energy-saving without imposing any significant overhead on the edge system.