 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay for Hints, Not Answers: LLM Shepherding for Cost-Efficient Inference
Jan 29, 2026Large Language Models (LLMs) deliver state-of-the-art performance on complex reasoning tasks, but their inference costs limit deployment at scale. Small Language Models (SLMs) offer dramatic cost savings yet lag substantially in accuracy. Existing approaches - routing and cascading - treat the LLM as an all-or-nothing resource: either the query bypasses the LLM entirely, or the LLM generates a complete response at full cost. We introduce LLM Shepherding, a framework that requests only a short prefix (a hint) from the LLM and provides it to SLM. This simple mechanism is surprisingly effective for math and coding tasks: even hints comprising 10-30% of the full LLM response improve SLM accuracy significantly. Shepherding generalizes both routing and cascading, and it achieves lower cost under oracle decision-making. We develop a two-stage predictor that jointly determines whether a hint is needed and how many tokens to request. On the widely-used mathematical reasoning (GSM8K, CNK12) and code generation (HumanEval, MBPP) benchmarks, Shepherding reduces costs by 42-94% relative to LLM-only inference. Compared to state-of-the-art routing and cascading baselines, shepherding delivers up to 2.8x cost reduction while matching accuracy. To our knowledge, this is the first work to exploit token-level budget control for SLM-LLM collaboration.
Inference Offloading for Cost-Sensitive Binary Classification at the Edge
Sep 19, 2025



We focus on a binary classification problem in an edge intelligence system where false negatives are more costly than false positives. The system has a compact, locally deployed model, which is supplemented by a larger, remote model, which is accessible via the network by incurring an offloading cost. For each sample, our system first uses the locally deployed model for inference. Based on the output of the local model, the sample may be offloaded to the remote model. This work aims to understand the fundamental trade-off between classification accuracy and these offloading costs within such a hierarchical inference (HI) system. To optimize this system, we propose an online learning framework that continuously adapts a pair of thresholds on the local model's confidence scores. These thresholds determine the prediction of the local model and whether a sample is classified locally or offloaded to the remote model. We present a closed-form solution for the setting where the local model is calibrated. For the more general case of uncalibrated models, we introduce H2T2, an online two-threshold hierarchical inference policy, and prove it achieves sublinear regret. H2T2 is model-agnostic, requires no training, and learns in the inference phase using limited feedback. Simulations on real-world datasets show that H2T2 consistently outperforms naive and single-threshold HI policies, sometimes even surpassing offline optima. The policy also demonstrates robustness to distribution shifts and adapts effectively to mismatched classifiers.
Low-Regret and Low-Complexity Learning for Hierarchical Inference
Aug 12, 2025This work focuses on Hierarchical Inference (HI) in edge intelligence systems, where a compact Local-ML model on an end-device works in conjunction with a high-accuracy Remote-ML model on an edge-server. HI aims to reduce latency, improve accuracy, and lower bandwidth usage by first using the Local-ML model for inference and offloading to the Remote-ML only when the local inference is likely incorrect. A critical challenge in HI is estimating the likelihood of the local inference being incorrect, especially when data distributions and offloading costs change over time -- a problem we term Hierarchical Inference Learning (HIL). We introduce a novel approach to HIL by modeling the probability of correct inference by the Local-ML as an increasing function of the model's confidence measure, a structure motivated by empirical observations but previously unexploited. We propose two policies, HI-LCB and HI-LCB-lite, based on the Upper Confidence Bound (UCB) framework. We demonstrate that both policies achieve order-optimal regret of $O(\log T)$, a significant improvement over existing HIL policies with $O(T^{2/3})$ regret guarantees. Notably, HI-LCB-lite has an $O(1)$ per-sample computational complexity, making it well-suited for deployment on devices with severe resource limitations. Simulations using real-world datasets confirm that our policies outperform existing state-of-the-art HIL methods.
Towards Efficient Multi-LLM Inference: Characterization and Analysis of LLM Routing and Hierarchical Techniques
Jun 06, 2025Recent progress in Language Models (LMs) has dramatically advanced the field of natural language processing (NLP), excelling at tasks like text generation, summarization, and question answering. However, their inference remains computationally expensive and energy intensive, especially in settings with limited hardware, power, or bandwidth. This makes it difficult to deploy LMs in mobile, edge, or cost sensitive environments. To address these challenges, recent approaches have introduced multi LLM intelligent model selection strategies that dynamically allocate computational resources based on query complexity -- using lightweight models for simpler queries and escalating to larger models only when necessary. This survey explores two complementary strategies for efficient LLM inference: (i) routing, which selects the most suitable model based on the query, and (ii) cascading or hierarchical inference (HI), which escalates queries through a sequence of models until a confident response is found. Both approaches aim to reduce computation by using lightweight models for simpler tasks while offloading only when needed. We provide a comparative analysis of these techniques across key performance metrics, discuss benchmarking efforts, and outline open challenges. Finally, we outline future research directions to enable faster response times, adaptive model selection based on task complexity, and scalable deployment across heterogeneous environments, making LLM based systems more efficient and accessible for real world applications.
Minimizing Age of Detection for a Markov Source over a Lossy Channel
Mar 04, 2025Monitoring a process/phenomenon of specific interest is prevalent in Cyber-Physical Systems (CPS), remote healthcare, smart buildings, intelligent transport, industry 4.0, etc. A key building block of the monitoring system is a sensor sampling the process and communicating the status updates to a monitor for detecting events of interest. Measuring the freshness of the status updates is essential for the timely detection of events, and it has received significant research interest in recent times. In this paper, we propose a new freshness metric, Age of Detection (AoD), for monitoring the state transitions of a Discrete Time Markov Chain (DTMC) source over a lossy wireless channel. We consider the pull model where the sensor samples DTMC state whenever the monitor requests a status update. We formulate a Constrained Markov Decision Problem (CMDP) for optimising the AoD subject to a constraint on the average sampling frequency and solve it using the Lagrangian MDP formulation and Relative Value Iteration (RVI) algorithm. Our numerical results show interesting trade-offs between AoD, sampling frequency, and transmission success probability. Further, the AoD minimizing policy provides a lower estimation error than the Age of Information (AoI) minimizing policy, thus demonstrating the utility of AoD for monitoring DTMC sources.
The Case for Hierarchical Deep Learning Inference at the Network Edge
Apr 23, 2023



Resource-constrained Edge Devices (EDs), e.g., IoT sensors and microcontroller units, are expected to make intelligent decisions using Deep Learning (DL) inference at the edge of the network. Toward this end, there is a significant research effort in developing tinyML models - Deep Learning (DL) models with reduced computation and memory storage requirements - that can be embedded on these devices. However, tinyML models have lower inference accuracy. On a different front, DNN partitioning and inference offloading techniques were studied for distributed DL inference between EDs and Edge Servers (ESs). In this paper, we explore Hierarchical Inference (HI), a novel approach proposed by Vishnu et al. 2023, arXiv:2304.00891v1 , for performing distributed DL inference at the edge. Under HI, for each data sample, an ED first uses a local algorithm (e.g., a tinyML model) for inference. Depending on the application, if the inference provided by the local algorithm is incorrect or further assistance is required from large DL models on edge or cloud, only then the ED offloads the data sample. At the outset, HI seems infeasible as the ED, in general, cannot know if the local inference is sufficient or not. Nevertheless, we present the feasibility of implementing HI for machine fault detection and image classification applications. We demonstrate its benefits using quantitative analysis and argue that using HI will result in low latency, bandwidth savings, and energy savings in edge AI systems.
Online Algorithms for Hierarchical Inference in Deep Learning applications at the Edge
Apr 03, 2023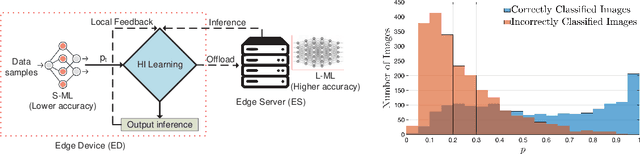


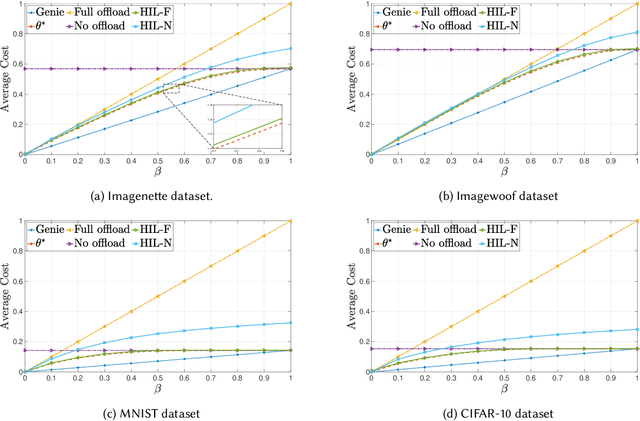
We consider a resource-constrained Edge Device (ED) embedded with a small-size ML model (S-ML) for a generic classification application, and an Edge Server (ES) that hosts a large-size ML model (L-ML). Since the inference accuracy of S-ML is lower than that of the L-ML, offloading all the data samples to the ES results in high inference accuracy, but it defeats the purpose of embedding S-ML on the ED and deprives the benefits of reduced latency, bandwidth savings, and energy efficiency of doing local inference. To get the best out of both worlds, i.e., the benefits of doing inference on the ED and the benefits of doing inference on ES, we explore the idea of Hierarchical Inference (HI), wherein S-ML inference is only accepted when it is correct, otherwise the data sample is offloaded for L-ML inference. However, the ideal implementation of HI is infeasible as the correctness of the S-ML inference is not known to the ED. We thus propose an online meta-learning framework to predict the correctness of the S-ML inference. The resulting online learning problem turns out to be a Prediction with Expert Advice (PEA) problem with continuous expert space. We consider the full feedback scenario, where the ED receives feedback on the correctness of the S-ML once it accepts the inference, and the no-local feedback scenario, where the ED does not receive the ground truth for the classification, and propose the HIL-F and HIL-N algorithms and prove a regret bound that is sublinear with the number of data samples. We evaluate and benchmark the performance of the proposed algorithms for image classification applications using four datasets, namely, Imagenette, Imagewoof, MNIST, and CIFAR-10.
Edge-MultiAI: Multi-Tenancy of Latency-Sensitive Deep Learning Applications on Edge
Nov 14, 2022



Smart IoT-based systems often desire continuous execution of multiple latency-sensitive Deep Learning (DL) applications. The edge servers serve as the cornerstone of such IoT-based systems, however, their resource limitations hamper the continuous execution of multiple (multi-tenant) DL applications. The challenge is that, DL applications function based on bulky "neural network (NN) models" that cannot be simultaneously maintained in the limited memory space of the edge. Accordingly, the main contribution of this research is to overcome the memory contention challenge, thereby, meeting the latency constraints of the DL applications without compromising their inference accuracy. We propose an efficient NN model management framework, called Edge-MultiAI, that ushers the NN models of the DL applications into the edge memory such that the degree of multi-tenancy and the number of warm-starts are maximized. Edge-MultiAI leverages NN model compression techniques, such as model quantization, and dynamically loads NN models for DL applications to stimulate multi-tenancy on the edge server. We also devise a model management heuristic for Edge-MultiAI, called iWS-BFE, that functions based on the Bayesian theory to predict the inference requests for multi-tenant applications, and uses it to choose the appropriate NN models for loading, hence, increasing the number of warm-start inferences. We evaluate the efficacy and robustness of Edge-MultiAI under various configurations. The results reveal that Edge-MultiAI can stimulate the degree of multi-tenancy on the edge by at least 2X and increase the number of warm-starts by around 60% without any major loss on the inference accuracy of the applications.
Offloading Algorithms for Maximizing Inference Accuracy on Edge Device Under a Time Constraint
Dec 21, 2021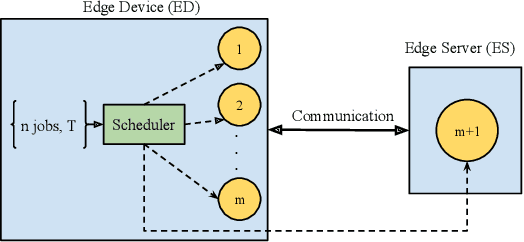
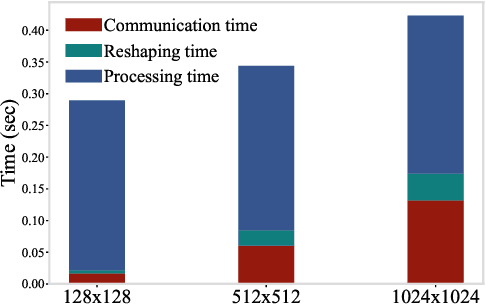
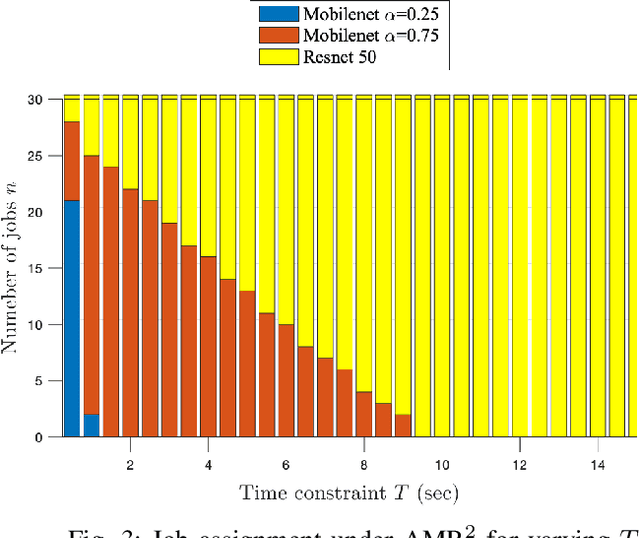
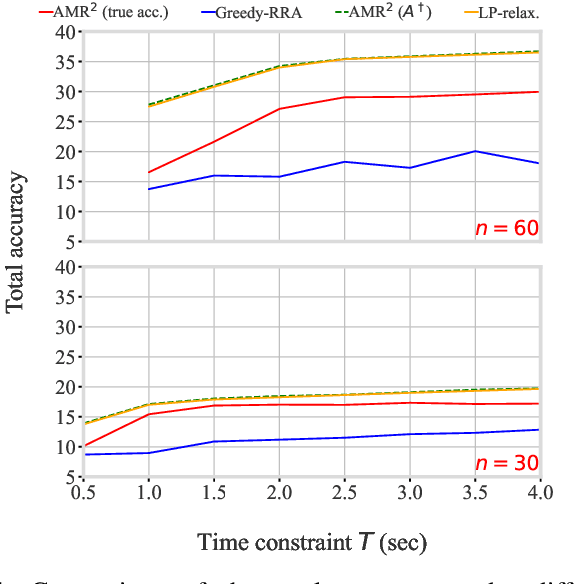
With the emergence of edge computing, the problem of offloading jobs between an Edge Device (ED) and an Edge Server (ES) received significant attention in the past. Motivated by the fact that an increasing number of applications are using Machine Learning (ML) inference, we study the problem of offloading inference jobs by considering the following novel aspects: 1) in contrast to a typical computational job, the processing time of an inference job depends on the size of the ML model, and 2) recently proposed Deep Neural Networks (DNNs) for resource-constrained devices provide the choice of scaling the model size. We formulate an assignment problem with the aim of maximizing the total inference accuracy of n data samples available at the ED, subject to a time constraint T on the makespan. We propose an approximation algorithm AMR2, and prove that it results in a makespan at most 2T, and achieves a total accuracy that is lower by a small constant from optimal total accuracy. As proof of concept, we implemented AMR2 on a Raspberry Pi, equipped with MobileNet, and is connected to a server equipped with ResNet, and studied the total accuracy and makespan performance of AMR2 for image classification application.