 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference Offloading for Cost-Sensitive Binary Classification at the Edge
Sep 19, 2025We focus on a binary classification problem in an edge intelligence system where false negatives are more costly than false positives. The system has a compact, locally deployed model, which is supplemented by a larger, remote model, which is accessible via the network by incurring an offloading cost. For each sample, our system first uses the locally deployed model for inference. Based on the output of the local model, the sample may be offloaded to the remote model. This work aims to understand the fundamental trade-off between classification accuracy and these offloading costs within such a hierarchical inference (HI) system. To optimize this system, we propose an online learning framework that continuously adapts a pair of thresholds on the local model's confidence scores. These thresholds determine the prediction of the local model and whether a sample is classified locally or offloaded to the remote model. We present a closed-form solution for the setting where the local model is calibrated. For the more general case of uncalibrated models, we introduce H2T2, an online two-threshold hierarchical inference policy, and prove it achieves sublinear regret. H2T2 is model-agnostic, requires no training, and learns in the inference phase using limited feedback. Simulations on real-world datasets show that H2T2 consistently outperforms naive and single-threshold HI policies, sometimes even surpassing offline optima. The policy also demonstrates robustness to distribution shifts and adapts effectively to mismatched classifiers.
ExPECA: An Experimental Platform for Trustworthy Edge Computing Applications
Nov 02, 2023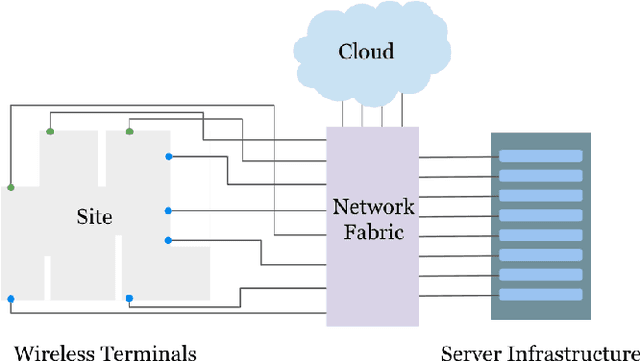

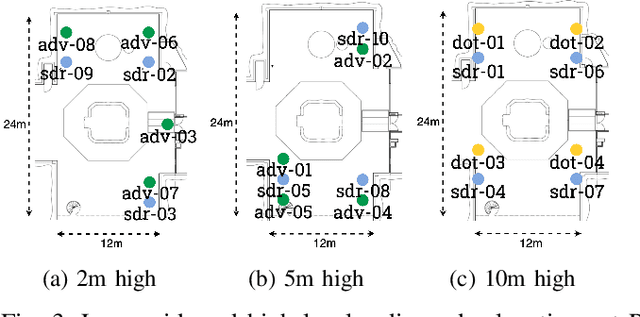

This paper presents ExPECA, an edge computing and wireless communication research testbed designed to tackle two pressing challenges: comprehensive end-to-end experimentation and high levels of experimental reproducibility. Leveraging OpenStack-based Chameleon Infrastructure (CHI) framework for its proven flexibility and ease of operation, ExPECA is located in a unique, isolated underground facility, providing a highly controlled setting for wireless experiments. The testbed is engineered to facilitate integrated studies of both communication and computation, offering a diverse array of Software-Defined Radios (SDR) and Commercial Off-The-Shelf (COTS) wireless and wired links, as well as containerized computational environments. We exemplify the experimental possibilities of the testbed using OpenRTiST, a latency-sensitive, bandwidth-intensive application, and analyze its performance. Lastly, we highlight an array of research domains and experimental setups that stand to gain from ExPECA's features, including closed-loop applications and time-sensitive networking.
The Case for Hierarchical Deep Learning Inference at the Network Edge
Apr 23, 2023



Resource-constrained Edge Devices (EDs), e.g., IoT sensors and microcontroller units, are expected to make intelligent decisions using Deep Learning (DL) inference at the edge of the network. Toward this end, there is a significant research effort in developing tinyML models - Deep Learning (DL) models with reduced computation and memory storage requirements - that can be embedded on these devices. However, tinyML models have lower inference accuracy. On a different front, DNN partitioning and inference offloading techniques were studied for distributed DL inference between EDs and Edge Servers (ESs). In this paper, we explore Hierarchical Inference (HI), a novel approach proposed by Vishnu et al. 2023, arXiv:2304.00891v1 , for performing distributed DL inference at the edge. Under HI, for each data sample, an ED first uses a local algorithm (e.g., a tinyML model) for inference. Depending on the application, if the inference provided by the local algorithm is incorrect or further assistance is required from large DL models on edge or cloud, only then the ED offloads the data sample. At the outset, HI seems infeasible as the ED, in general, cannot know if the local inference is sufficient or not. Nevertheless, we present the feasibility of implementing HI for machine fault detection and image classification applications. We demonstrate its benefits using quantitative analysis and argue that using HI will result in low latency, bandwidth savings, and energy savings in edge AI systems.
Online Algorithms for Hierarchical Inference in Deep Learning applications at the Edge
Apr 03, 2023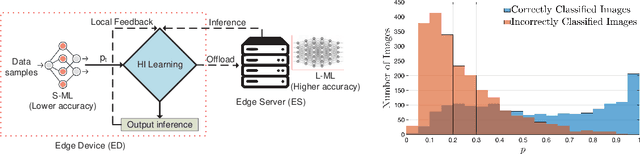


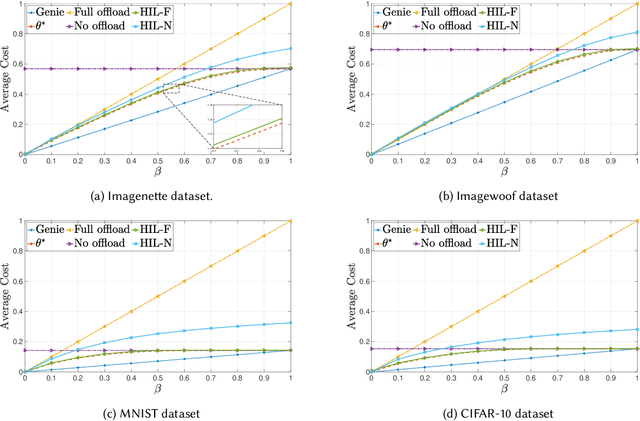
We consider a resource-constrained Edge Device (ED) embedded with a small-size ML model (S-ML) for a generic classification application, and an Edge Server (ES) that hosts a large-size ML model (L-ML). Since the inference accuracy of S-ML is lower than that of the L-ML, offloading all the data samples to the ES results in high inference accuracy, but it defeats the purpose of embedding S-ML on the ED and deprives the benefits of reduced latency, bandwidth savings, and energy efficiency of doing local inference. To get the best out of both worlds, i.e., the benefits of doing inference on the ED and the benefits of doing inference on ES, we explore the idea of Hierarchical Inference (HI), wherein S-ML inference is only accepted when it is correct, otherwise the data sample is offloaded for L-ML inference. However, the ideal implementation of HI is infeasible as the correctness of the S-ML inference is not known to the ED. We thus propose an online meta-learning framework to predict the correctness of the S-ML inference. The resulting online learning problem turns out to be a Prediction with Expert Advice (PEA) problem with continuous expert space. We consider the full feedback scenario, where the ED receives feedback on the correctness of the S-ML once it accepts the inference, and the no-local feedback scenario, where the ED does not receive the ground truth for the classification, and propose the HIL-F and HIL-N algorithms and prove a regret bound that is sublinear with the number of data samples. We evaluate and benchmark the performance of the proposed algorithms for image classification applications using four datasets, namely, Imagenette, Imagewoof, MNIST, and CIFAR-10.