 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Algorithms for Hierarchical Inference in Deep Learning applications at the Edge
Paper and Code
Apr 03, 2023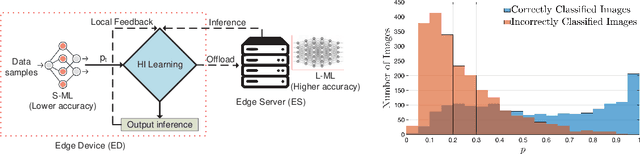


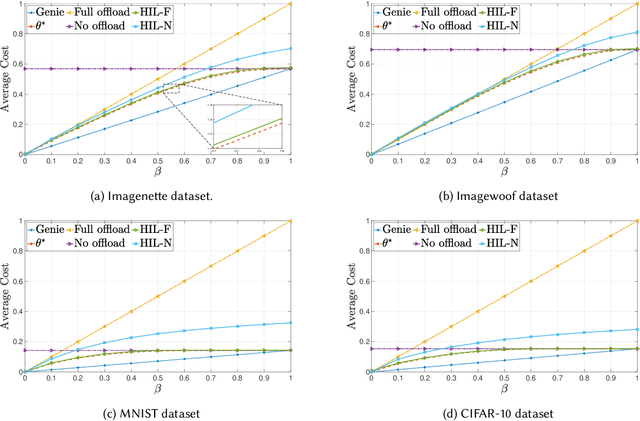
We consider a resource-constrained Edge Device (ED) embedded with a small-size ML model (S-ML) for a generic classification application, and an Edge Server (ES) that hosts a large-size ML model (L-ML). Since the inference accuracy of S-ML is lower than that of the L-ML, offloading all the data samples to the ES results in high inference accuracy, but it defeats the purpose of embedding S-ML on the ED and deprives the benefits of reduced latency, bandwidth savings, and energy efficiency of doing local inference. To get the best out of both worlds, i.e., the benefits of doing inference on the ED and the benefits of doing inference on ES, we explore the idea of Hierarchical Inference (HI), wherein S-ML inference is only accepted when it is correct, otherwise the data sample is offloaded for L-ML inference. However, the ideal implementation of HI is infeasible as the correctness of the S-ML inference is not known to the ED. We thus propose an online meta-learning framework to predict the correctness of the S-ML inference. The resulting online learning problem turns out to be a Prediction with Expert Advice (PEA) problem with continuous expert space. We consider the full feedback scenario, where the ED receives feedback on the correctness of the S-ML once it accepts the inference, and the no-local feedback scenario, where the ED does not receive the ground truth for the classification, and propose the HIL-F and HIL-N algorithms and prove a regret bound that is sublinear with the number of data samples. We evaluate and benchmark the performance of the proposed algorithms for image classification applications using four datasets, namely, Imagenette, Imagewoof, MNIST, and CIFAR-10.