 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Imitation Learning of Team Behavior from Heterogeneous Demonstrations
Feb 24, 2025Successful collaboration requires team members to stay aligned, especially in complex sequential tasks. Team members must dynamically coordinate which subtasks to perform and in what order. However, real-world constraints like partial observability and limited communication bandwidth often lead to suboptimal collaboration. Even among expert teams, the same task can be executed in multiple ways. To develop multi-agent systems and human-AI teams for such tasks, we are interested in data-driven learning of multimodal team behaviors. Multi-Agent Imitation Learning (MAIL) provides a promising framework for data-driven learning of team behavior from demonstrations, but existing methods struggle with heterogeneous demonstrations, as they assume that all demonstrations originate from a single team policy. Hence, in this work, we introduce DTIL: a hierarchical MAIL algorithm designed to learn multimodal team behaviors in complex sequential tasks. DTIL represents each team member with a hierarchical policy and learns these policies from heterogeneous team demonstrations in a factored manner. By employing a distribution-matching approach, DTIL mitigates compounding errors and scales effectively to long horizons and continuous state representations. Experimental results show that DTIL outperforms MAIL baselines and accurately models team behavior across a variety of collaborative scenarios.
Socratic: Enhancing Human Teamwork via AI-enabled Coaching
Feb 24, 2025Coaches are vital for effective collaboration, but cost and resource constraints often limit their availability during real-world tasks. This limitation poses serious challenges in life-critical domains that rely on effective teamwork, such as healthcare and disaster response. To address this gap, we propose and realize an innovative application of AI: task-time team coaching. Specifically, we introduce Socratic, a novel AI system that complements human coaches by providing real-time guidance during task execution. Socratic monitors team behavior, detects misalignments in team members' shared understanding, and delivers automated interventions to improve team performance. We validated Socratic through two human subject experiments involving dyadic collaboration. The results demonstrate that the system significantly enhances team performance with minimal interventions. Participants also perceived Socratic as helpful and trustworthy, supporting its potential for adoption. Our findings also suggest promising directions both for AI research and its practical applications to enhance human teamwork.
IDIL: Imitation Learning of Intent-Driven Expert Behavior
Apr 25, 2024When faced with accomplishing a task, human experts exhibit intentional behavior. Their unique intents shape their plans and decisions, resulting in experts demonstrating diverse behaviors to accomplish the same task. Due to the uncertainties encountered in the real world and their bounded rationality, experts sometimes adjust their intents, which in turn influences their behaviors during task execution. This paper introduces IDIL, a novel imitation learning algorithm to mimic these diverse intent-driven behaviors of experts. Iteratively, our approach estimates expert intent from heterogeneous demonstrations and then uses it to learn an intent-aware model of their behavior. Unlike contemporary approaches, IDIL is capable of addressing sequential tasks with high-dimensional state representations, while sidestepping the complexities and drawbacks associated with adversarial training (a mainstay of related techniques). Our empirical results suggest that the models generated by IDIL either match or surpass those produced by recent imitation learning benchmarks in metrics of task performance. Moreover, as it creates a generative model, IDIL demonstrates superior performance in intent inference metrics, crucial for human-agent interactions, and aptly captures a broad spectrum of expert behaviors.
ExPECA: An Experimental Platform for Trustworthy Edge Computing Applications
Nov 02, 2023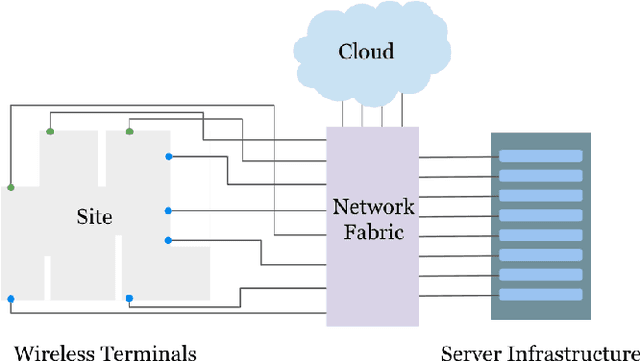

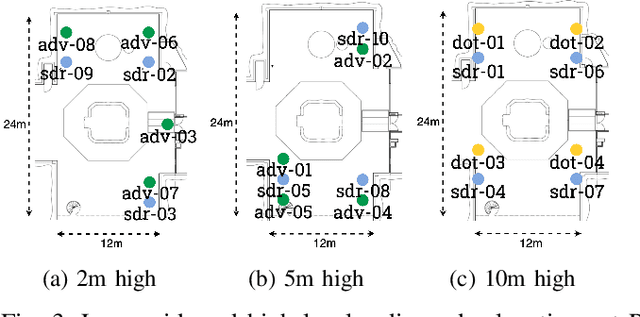

This paper presents ExPECA, an edge computing and wireless communication research testbed designed to tackle two pressing challenges: comprehensive end-to-end experimentation and high levels of experimental reproducibility. Leveraging OpenStack-based Chameleon Infrastructure (CHI) framework for its proven flexibility and ease of operation, ExPECA is located in a unique, isolated underground facility, providing a highly controlled setting for wireless experiments. The testbed is engineered to facilitate integrated studies of both communication and computation, offering a diverse array of Software-Defined Radios (SDR) and Commercial Off-The-Shelf (COTS) wireless and wired links, as well as containerized computational environments. We exemplify the experimental possibilities of the testbed using OpenRTiST, a latency-sensitive, bandwidth-intensive application, and analyze its performance. Lastly, we highlight an array of research domains and experimental setups that stand to gain from ExPECA's features, including closed-loop applications and time-sensitive networking.
Automated Task-Time Interventions to Improve Teamwork using Imitation Learning
Mar 02, 2023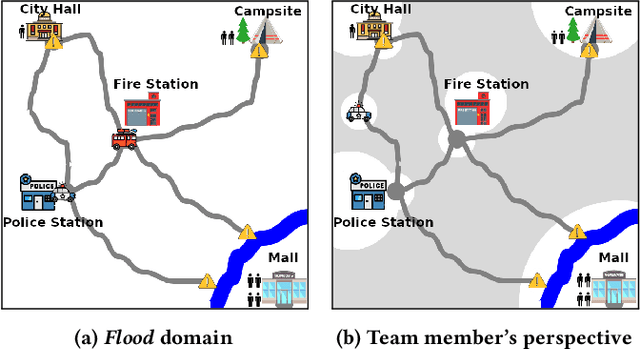
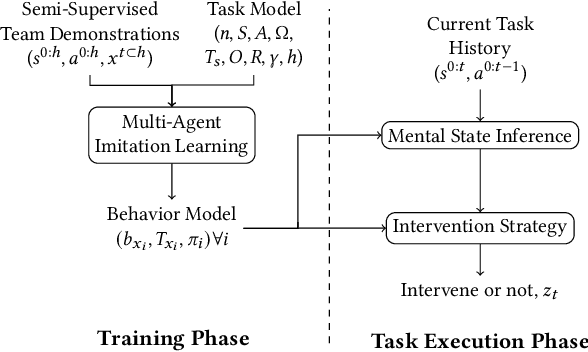
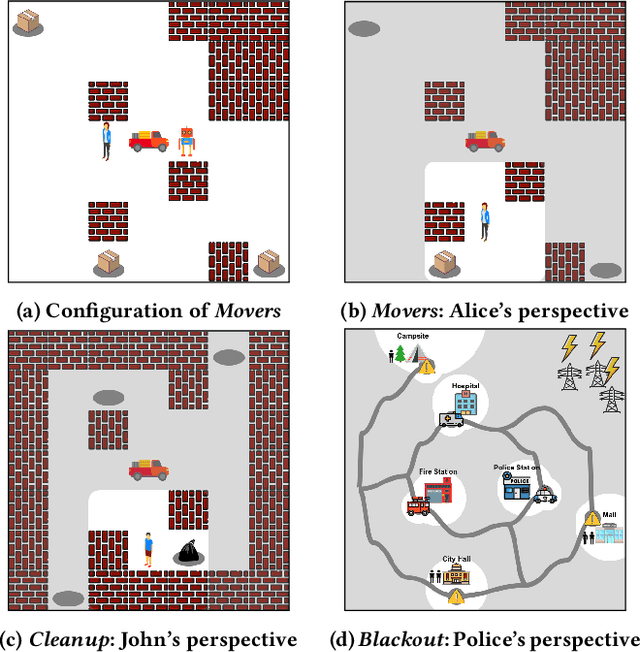
Effective human-human and human-autonomy teamwork is critical but often challenging to perfect. The challenge is particularly relevant in time-critical domains, such as healthcare and disaster response, where the time pressures can make coordination increasingly difficult to achieve and the consequences of imperfect coordination can be severe. To improve teamwork in these and other domains, we present TIC: an automated intervention approach for improving coordination between team members. Using BTIL, a multi-agent imitation learning algorithm, our approach first learns a generative model of team behavior from past task execution data. Next, it utilizes the learned generative model and team's task objective (shared reward) to algorithmically generate execution-time interventions. We evaluate our approach in synthetic multi-agent teaming scenarios, where team members make decentralized decisions without full observability of the environment. The experiments demonstrate that the automated interventions can successfully improve team performance and shed light on the design of autonomous agents for improving teamwork.
Semi-Supervised Imitation Learning of Team Policies from Suboptimal Demonstrations
May 11, 2022
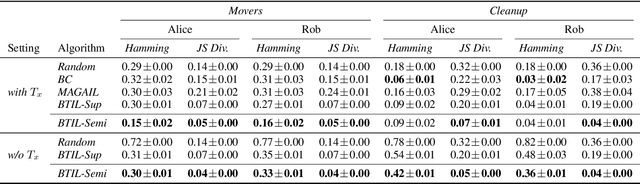
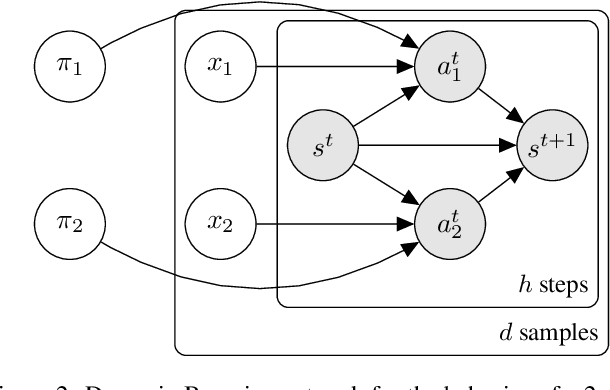
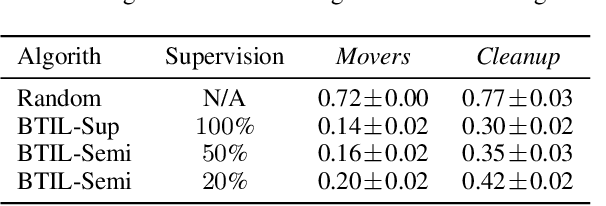
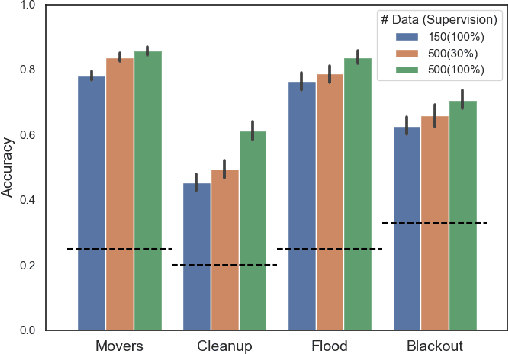
We present Bayesian Team Imitation Learner (BTIL), an imitation learning algorithm to model behavior of teams performing sequential tasks in Markovian domains. In contrast to existing multi-agent imitation learning techniques, BTIL explicitly models and infers the time-varying mental states of team members, thereby enabling learning of decentralized team policies from demonstrations of suboptimal teamwork. Further, to allow for sample- and label-efficient policy learning from small datasets, BTIL employs a Bayesian perspective and is capable of learning from semi-supervised demonstrations. We demonstrate and benchmark the performance of BTIL on synthetic multi-agent tasks as well as a novel dataset of human-agent teamwork. Our experiments show that BTIL can successfully learn team policies from demonstrations despite the influence of team members' (time-varying and potentially misaligned) mental states on their behavior.
Towards an AI Coach to Infer Team Mental Model Alignment in Healthcare
Feb 17, 2021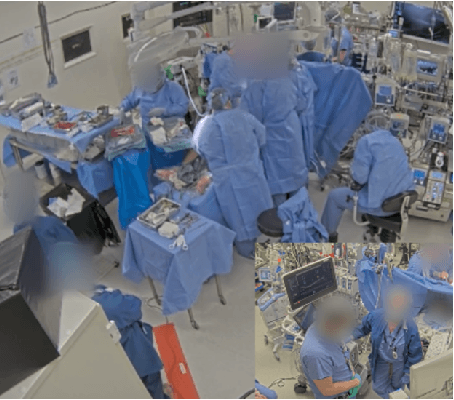
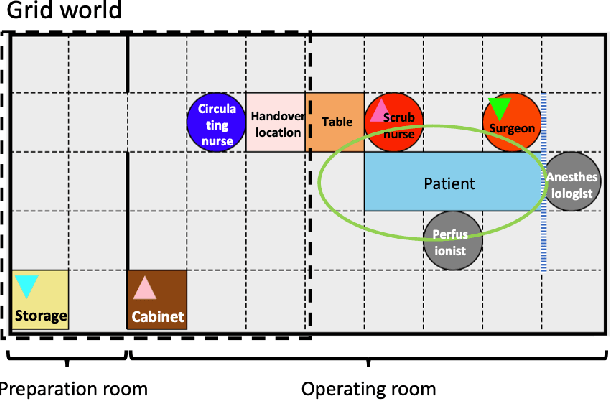
Shared mental models are critical to team success; however, in practice, team members may have misaligned models due to a variety of factors. In safety-critical domains (e.g., aviation, healthcare), lack of shared mental models can lead to preventable errors and harm. Towards the goal of mitigating such preventable errors, here, we present a Bayesian approach to infer misalignment in team members' mental models during complex healthcare task execution. As an exemplary application, we demonstrate our approach using two simulated team-based scenarios, derived from actual teamwork in cardiac surgery. In these simulated experiments, our approach inferred model misalignment with over 75% recall, thereby providing a building block for enabling computer-assisted interventions to augment human cognition in the operating room and improve teamwork.
VOTE400: A Speech Dataset to Study Voice Interface for Elderly-Care
Jan 20, 2021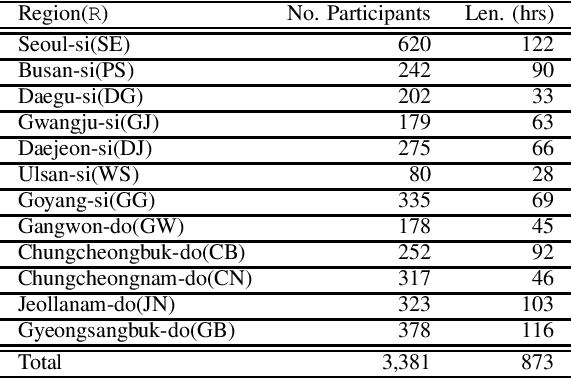
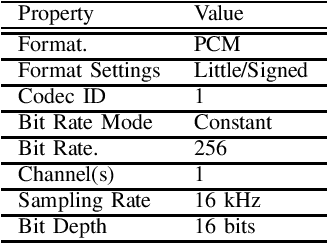
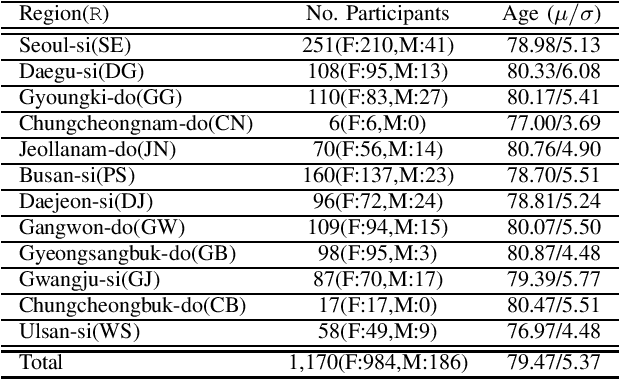
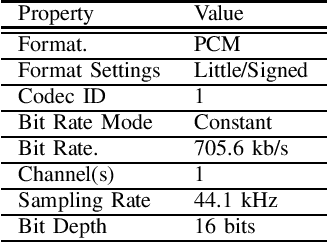
This paper introduces a large-scale Korean speech dataset, called VOTE400, that can be used for analyzing and recognizing voices of the elderly people. The dataset includes about 300 hours of continuous dialog speech and 100 hours of read speech, both recorded by the elderly people aged 65 years or over. A preliminary experiment showed that speech recognition system trained with VOTE400 can outperform conventional systems in speech recognition of elderly people's voice. This work is a multi-organizational effort led by ETRI and MINDs Lab Inc. for the purpose of advancing the speech recognition performance of the elderly-care robots.