 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossless Token Merging Even Without Fine-Tuning in Vision Transformers
May 21, 2025Although Vision Transformers (ViTs) have become the standard architecture in computer vision, their massive sizes lead to significant computational overhead. Token compression techniques have attracted considerable attention to address this issue, but they often suffer from severe information loss, requiring extensive additional training to achieve practical performance. In this paper, we propose Adaptive Token Merging (ATM), a novel method that ensures lossless token merging, eliminating the need for fine-tuning while maintaining competitive performance. ATM adaptively reduces tokens across layers and batches by carefully adjusting layer-specific similarity thresholds, thereby preventing the undesirable merging of less similar tokens with respect to each layer. Furthermore, ATM introduces a novel token matching technique that considers not only similarity but also merging sizes, particularly for the final layers, to minimize the information loss incurred from each merging operation. We empirically validate our method across a wide range of pretrained models, demonstrating that ATM not only outperforms all existing training-free methods but also surpasses most training-intensive approaches, even without additional training. Remarkably, training-free ATM achieves over a 30% reduction in FLOPs for the DeiT-T and DeiT-S models without any drop in their original accuracy.
PGB: One-Shot Pruning for BERT via Weight Grouping and Permutation
Feb 06, 2025Large pretrained language models such as BERT suffer from slow inference and high memory usage, due to their huge size. Recent approaches to compressing BERT rely on iterative pruning and knowledge distillation, which, however, are often too complicated and computationally intensive. This paper proposes a novel semi-structured one-shot pruning method for BERT, called $\textit{Permutation and Grouping for BERT}$ (PGB), which achieves high compression efficiency and sparsity while preserving accuracy. To this end, PGB identifies important groups of individual weights by permutation and prunes all other weights as a structure in both multi-head attention and feed-forward layers. Furthermore, if no important group is formed in a particular layer, PGB drops the entire layer to produce an even more compact model. Our experimental results on BERT$_{\text{BASE}}$ demonstrate that PGB outperforms the state-of-the-art structured pruning methods in terms of computational cost and accuracy preservation.
Nonverbal Social Behavior Generation for Social Robots Using End-to-End Learning
Nov 02, 2022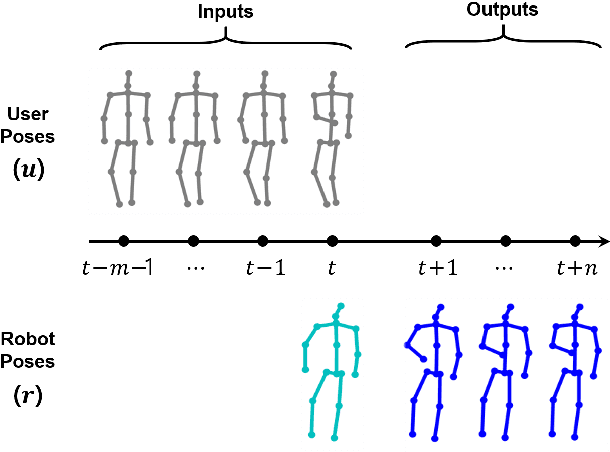

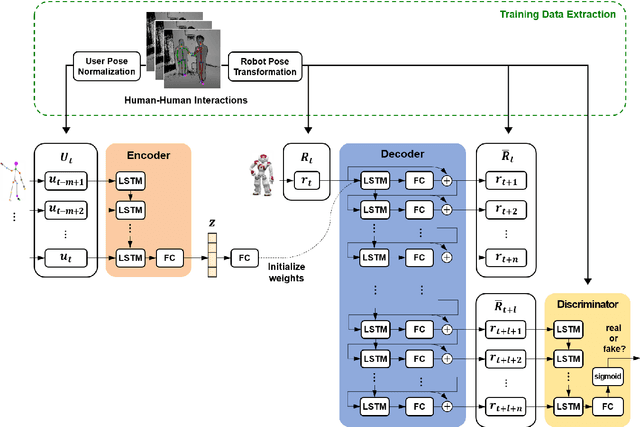

To provide effective and enjoyable human-robot interaction, it is important for social robots to exhibit nonverbal behaviors, such as a handshake or a hug. However, the traditional approach of reproducing pre-coded motions allows users to easily predict the reaction of the robot, giving the impression that the robot is a machine rather than a real agent. Therefore, we propose a neural network architecture based on the Seq2Seq model that learns social behaviors from human-human interactions in an end-to-end manner. We adopted a generative adversarial network to prevent invalid pose sequences from occurring when generating long-term behavior. To verify the proposed method, experiments were performed using the humanoid robot Pepper in a simulated environment. Because it is difficult to determine success or failure in social behavior generation, we propose new metrics to calculate the difference between the generated behavior and the ground-truth behavior. We used these metrics to show how different network architectural choices affect the performance of behavior generation, and we compared the performance of learning multiple behaviors and that of learning a single behavior. We expect that our proposed method can be used not only with home service robots, but also for guide robots, delivery robots, educational robots, and virtual robots, enabling the users to enjoy and effectively interact with the robots.
VOTE400: A Speech Dataset to Study Voice Interface for Elderly-Care
Jan 20, 2021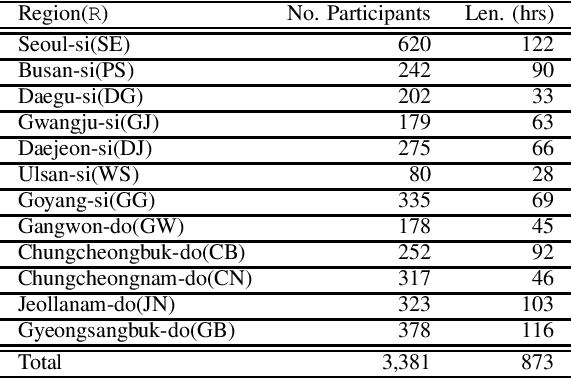
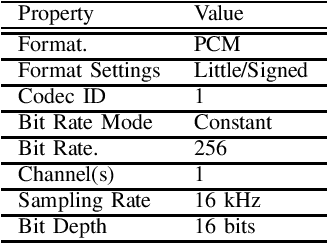
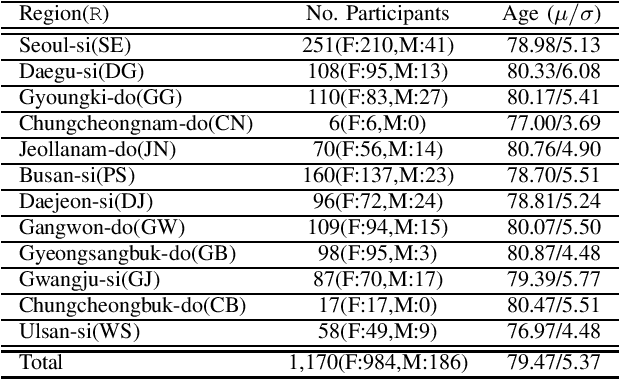
This paper introduces a large-scale Korean speech dataset, called VOTE400, that can be used for analyzing and recognizing voices of the elderly people. The dataset includes about 300 hours of continuous dialog speech and 100 hours of read speech, both recorded by the elderly people aged 65 years or over. A preliminary experiment showed that speech recognition system trained with VOTE400 can outperform conventional systems in speech recognition of elderly people's voice. This work is a multi-organizational effort led by ETRI and MINDs Lab Inc. for the purpose of advancing the speech recognition performance of the elderly-care robots.
Speech Gesture Generation from the Trimodal Context of Text, Audio, and Speaker Identity
Sep 04, 2020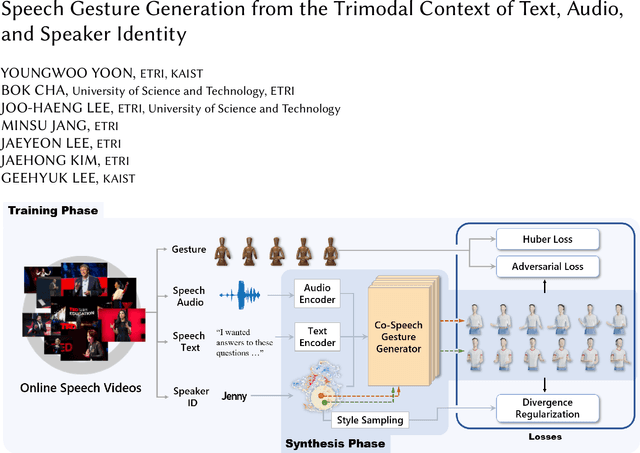
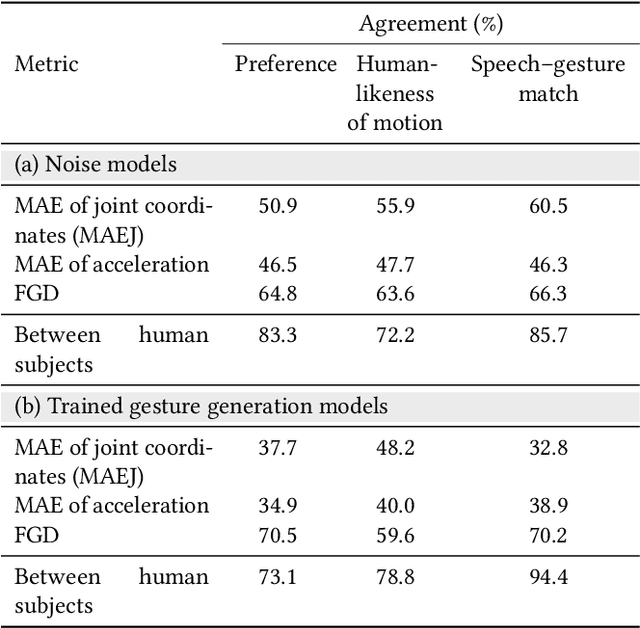
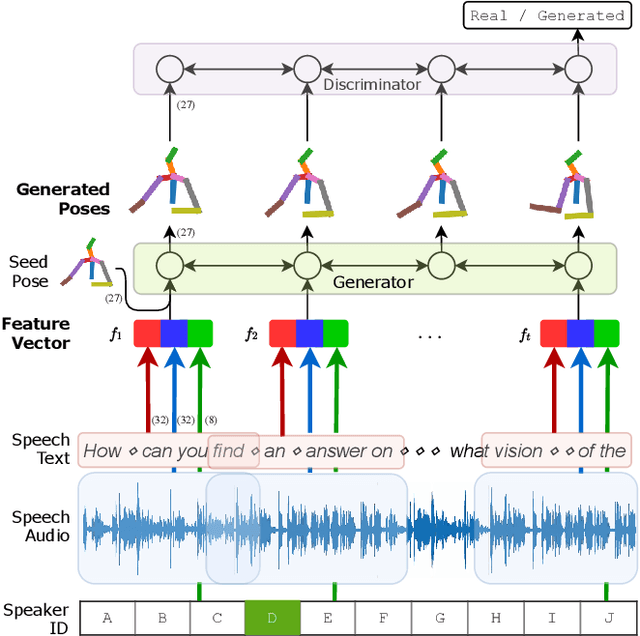

For human-like agents, including virtual avatars and social robots, making proper gestures while speaking is crucial in human--agent interaction. Co-speech gestures enhance interaction experiences and make the agents look alive. However, it is difficult to generate human-like gestures due to the lack of understanding of how people gesture. Data-driven approaches attempt to learn gesticulation skills from human demonstrations, but the ambiguous and individual nature of gestures hinders learning. In this paper, we present an automatic gesture generation model that uses the multimodal context of speech text, audio, and speaker identity to reliably generate gestures. By incorporating a multimodal context and an adversarial training scheme, the proposed model outputs gestures that are human-like and that match with speech content and rhythm. We also introduce a new quantitative evaluation metric for gesture generation models. Experiments with the introduced metric and subjective human evaluation showed that the proposed gesture generation model is better than existing end-to-end generation models. We further confirm that our model is able to work with synthesized audio in a scenario where contexts are constrained, and show that different gesture styles can be generated for the same speech by specifying different speaker identities in the style embedding space that is learned from videos of various speakers. All the code and data is available at https://github.com/ai4r/Gesture-Generation-from-Trimodal-Context.
AIR-Act2Act: Human-human interaction dataset for teaching non-verbal social behaviors to robots
Sep 04, 2020

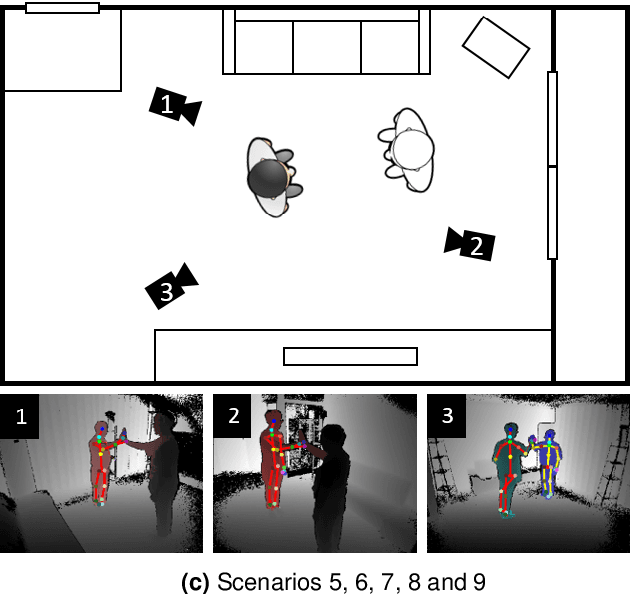
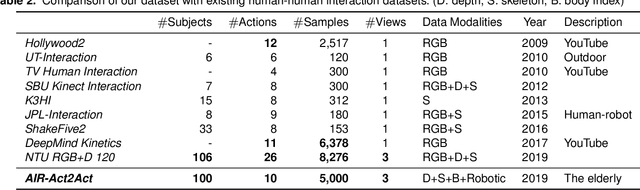
To better interact with users, a social robot should understand the users' behavior, infer the intention, and respond appropriately. Machine learning is one way of implementing robot intelligence. It provides the ability to automatically learn and improve from experience instead of explicitly telling the robot what to do. Social skills can also be learned through watching human-human interaction videos. However, human-human interaction datasets are relatively scarce to learn interactions that occur in various situations. Moreover, we aim to use service robots in the elderly-care domain; however, there has been no interaction dataset collected for this domain. For this reason, we introduce a human-human interaction dataset for teaching non-verbal social behaviors to robots. It is the only interaction dataset that elderly people have participated in as performers. We recruited 100 elderly people and two college students to perform 10 interactions in an indoor environment. The entire dataset has 5,000 interaction samples, each of which contains depth maps, body indexes and 3D skeletal data that are captured with three Microsoft Kinect v2 cameras. In addition, we provide the joint angles of a humanoid NAO robot which are converted from the human behavior that robots need to learn. The dataset and useful python scripts are available for download at https://github.com/ai4r/AIR-Act2Act. It can be used to not only teach social skills to robots but also benchmark action recognition algorithms.
ETRI-Activity3D: A Large-Scale RGB-D Dataset for Robots to Recognize Daily Activities of the Elderly
Mar 11, 2020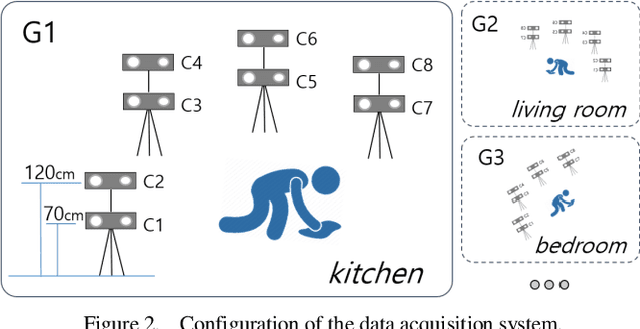
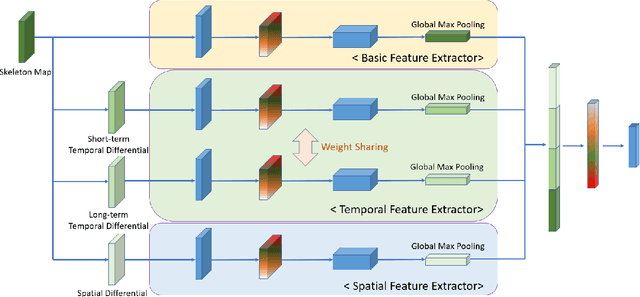
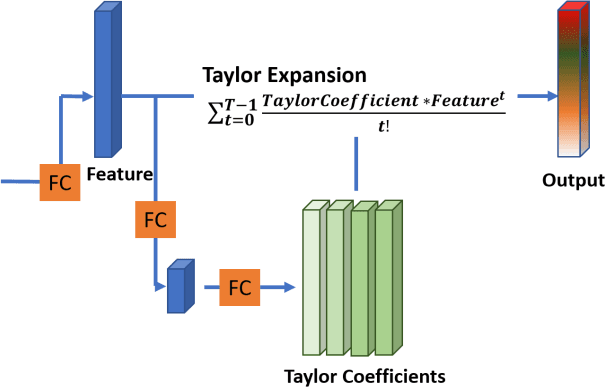
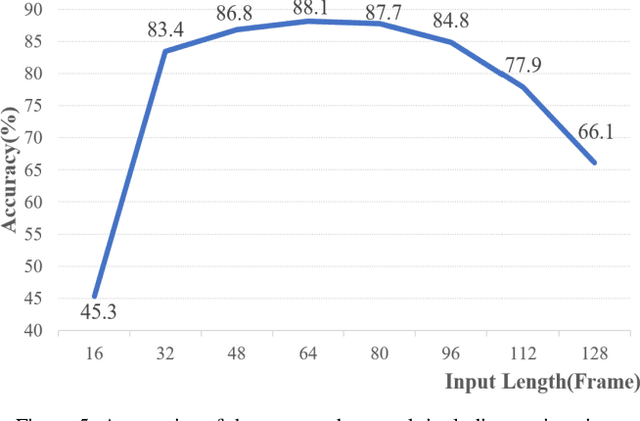
Deep learning, based on which many modern algorithms operate, is well known to be data-hungry. In particular, the datasets appropriate for the intended application are difficult to obtain. To cope with this situation, we introduce a new dataset called ETRI-Activity3D, focusing on the daily activities of the elderly in robot-view. The major characteristics of the new dataset are as follows: 1) practical action categories that are selected from the close observation of the daily lives of the elderly; 2) realistic data collection, which reflects the robot's working environment and service situations; and 3) a large-scale dataset that overcomes the limitations of the current 3D activity analysis benchmark datasets. The proposed dataset contains 112,620 samples including RGB videos, depth maps, and skeleton sequences. During the data acquisition, 100 subjects were asked to perform 55 daily activities. Additionally, we propose a novel network called four-stream adaptive CNN (FSA-CNN). The proposed FSA-CNN has three main properties: robustness to spatio-temporal variations, input-adaptive activation function, and extension of the conventional two-stream approach. In the experiment section, we confirmed the superiority of the proposed FSA-CNN using NTU RGB+D and ETRI-Activity3D. Further, the domain difference between both groups of age was verified experimentally. Finally, the extension of FSA-CNN to deal with the multimodal data was investigated.
Balancing Domain Gap for Object Instance Detection
Sep 26, 2019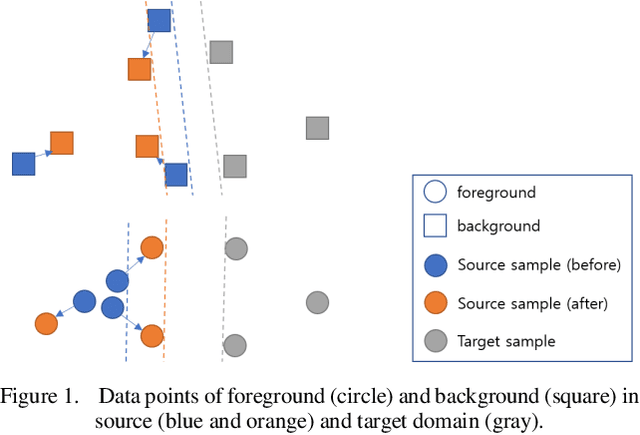
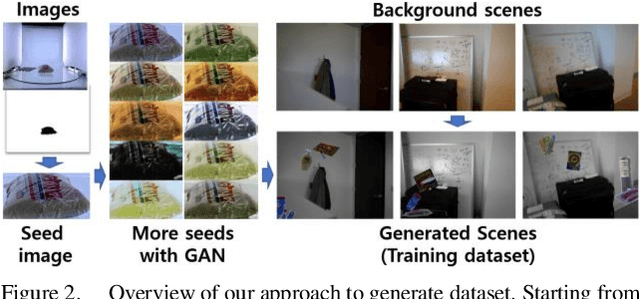


Object instance detection in cluttered indoor environment is a core functionality for service robots. We can readily build a detection system by following recent successful strategy of deep convolutional neural networks, if we have a large annotated dataset. However, it is hard to prepare such a huge dataset in instance detection problem where only small number of samples are available. This is one of main impediment to deploying an object detection system. To overcome this obstacle, many approaches to generate synthetic dataset have been proposed. These approaches confront the domain gap or reality gap problem stems from discrepancy between source domain (synthetic training dataset) and target domain (real test dataset). In this paper, we propose a simple approach to generate a synthetic dataset with minimum human effort. Especially, we identify that domain gaps of foreground and background are unbalanced and propose methods to balance these gaps. In the experiment, we verify that our methods help domain gaps to balance and improve the accuracy of object instance detection in cluttered indoor environment.
Neural Networks with Activation Networks
Nov 21, 2018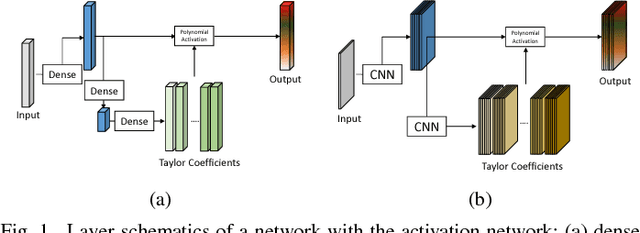
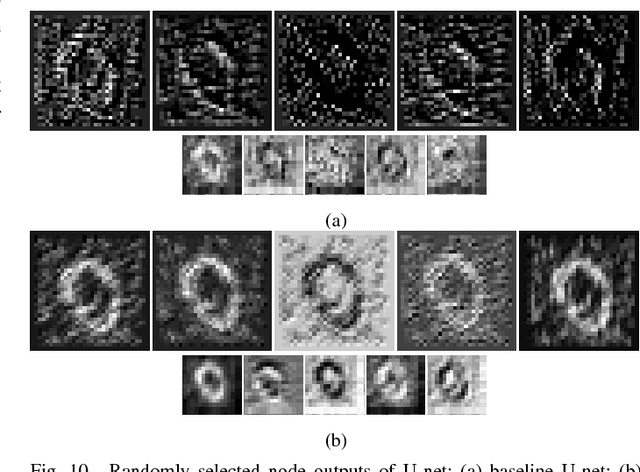
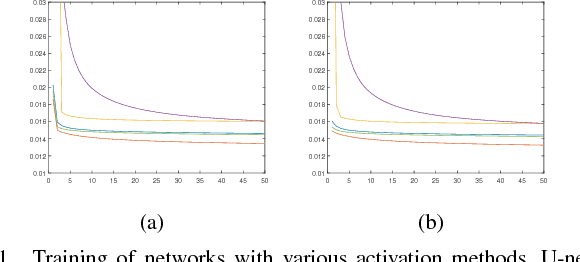
This work presents an adaptive activation method for neural networks that exploits the interdependency of features. Each pixel, node, and layer is assigned with a polynomial activation function, whose coefficients are provided by an auxiliary activation network. The activation of a feature depends on the features of neighboring pixels in a convolutional layer and other nodes in a dense layer. The dependency is learned from data by the activation networks. In our experiments, networks with activation networks provide significant performance improvement compared to the baseline networks on which they are built. The proposed method can be used to improve the network performance as an alternative to increasing the number of nodes and layers.
Robots Learn Social Skills: End-to-End Learning of Co-Speech Gesture Generation for Humanoid Robots
Oct 30, 2018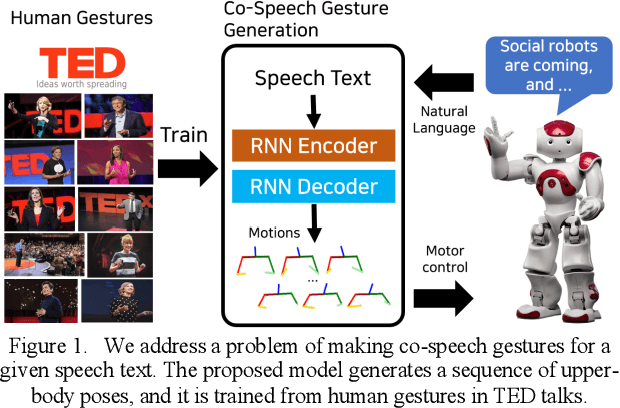

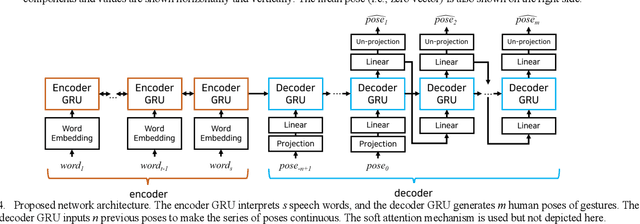
Co-speech gestures enhance interaction experiences between humans as well as between humans and robots. Existing robots use rule-based speech-gesture association, but this requires human labor and prior knowledge of experts to be implemented. We present a learning-based co-speech gesture generation that is learned from 52 h of TED talks. The proposed end-to-end neural network model consists of an encoder for speech text understanding and a decoder to generate a sequence of gestures. The model successfully produces various gestures including iconic, metaphoric, deictic, and beat gestures. In a subjective evaluation, participants reported that the gestures were human-like and matched the speech content. We also demonstrate a co-speech gesture with a NAO robot working in real time.