 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIVRA: Improving Visual-Token Relations for Robot Action Policy with Training-Free Hint-Based Guidance
Jan 22, 2026Many Vision-Language-Action (VLA) models flatten image patches into a 1D token sequence, weakening the 2D spatial cues needed for precise manipulation. We introduce IVRA, a lightweight, training-free method that improves spatial understanding by exploiting affinity hints already available in the model's built-in vision encoder, without requiring any external encoder or retraining. IVRA selectively injects these affinity signals into a language-model layer in which instance-level features reside. This inference-time intervention realigns visual-token interactions and better preserves geometric structure while keeping all model parameters fixed. We demonstrate the generality of IVRA by applying it to diverse VLA architectures (LLaRA, OpenVLA, and FLOWER) across simulated benchmarks spanning both 2D and 3D manipulation (VIMA and LIBERO) and on various real-robot tasks. On 2D VIMA, IVRA improves average success by +4.2% over the baseline LLaRA in a low-data regime. On 3D LIBERO, it yields consistent gains over the OpenVLA and FLOWER baselines, including improvements when baseline accuracy is near saturation (96.3% to 97.1%). All code and models will be released publicly. Visualizations are available at: jongwoopark7978.github.io/IVRA
Learning from Oblivion: Predicting Knowledge Overflowed Weights via Retrodiction of Forgetting
Aug 07, 2025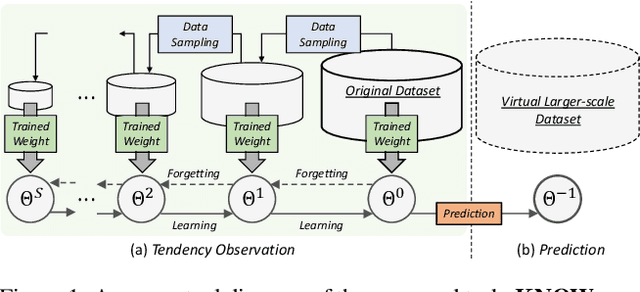
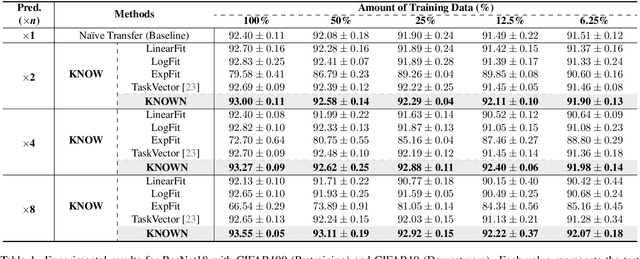
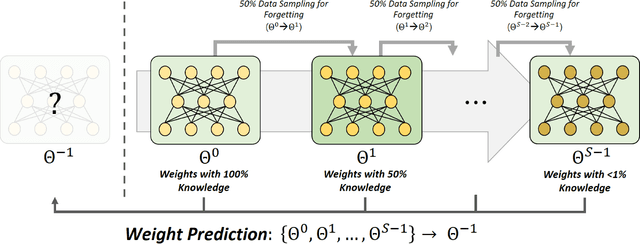
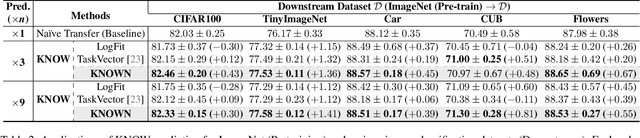
Pre-trained weights have become a cornerstone of modern deep learning, enabling efficient knowledge transfer and improving downstream task performance, especially in data-scarce scenarios. However, a fundamental question remains: how can we obtain better pre-trained weights that encapsulate more knowledge beyond the given dataset? In this work, we introduce \textbf{KNowledge Overflowed Weights (KNOW)} prediction, a novel strategy that leverages structured forgetting and its inversion to synthesize knowledge-enriched weights. Our key insight is that sequential fine-tuning on progressively downsized datasets induces a structured forgetting process, which can be modeled and reversed to recover knowledge as if trained on a larger dataset. We construct a dataset of weight transitions governed by this controlled forgetting and employ meta-learning to model weight prediction effectively. Specifically, our \textbf{KNowledge Overflowed Weights Nowcaster (KNOWN)} acts as a hyper-model that learns the general evolution of weights and predicts enhanced weights with improved generalization. Extensive experiments across diverse datasets and architectures demonstrate that KNOW prediction consistently outperforms Na\"ive fine-tuning and simple weight prediction, leading to superior downstream performance. Our work provides a new perspective on reinterpreting forgetting dynamics to push the limits of knowledge transfer in deep learning.
A Dual Process VLA: Efficient Robotic Manipulation Leveraging VLM
Oct 21, 2024



Vision-Language-Action (VLA) models are receiving increasing attention for their ability to enable robots to perform complex tasks by integrating visual context with linguistic commands. However, achieving efficient real-time performance remains challenging due to the high computational demands of existing models. To overcome this, we propose Dual Process VLA (DP-VLA), a hierarchical framework inspired by dual-process theory. DP-VLA utilizes a Large System 2 Model (L-Sys2) for complex reasoning and decision-making, while a Small System 1 Model (S-Sys1) handles real-time motor control and sensory processing. By leveraging Vision-Language Models (VLMs), the L-Sys2 operates at low frequencies, reducing computational overhead, while the S-Sys1 ensures fast and accurate task execution. Experimental results on the RoboCasa dataset demonstrate that DP-VLA achieves faster inference and higher task success rates, providing a scalable solution for advanced robotic applications.
ETRI-Activity3D: A Large-Scale RGB-D Dataset for Robots to Recognize Daily Activities of the Elderly
Mar 11, 2020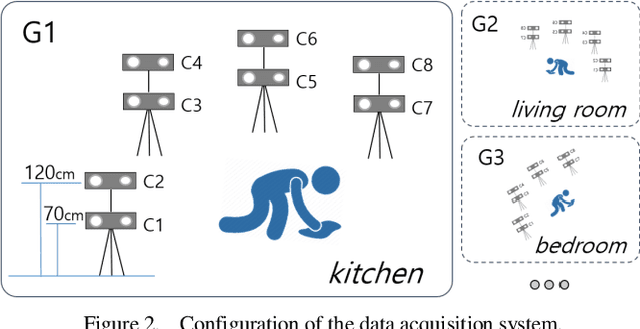
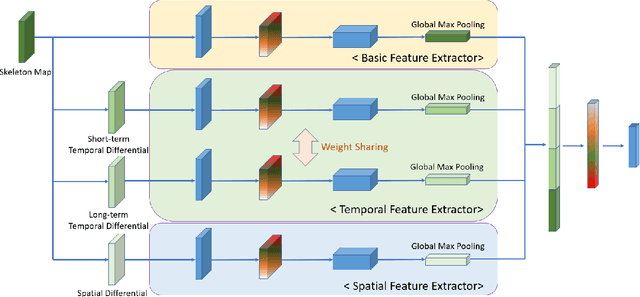
Deep learning, based on which many modern algorithms operate, is well known to be data-hungry. In particular, the datasets appropriate for the intended application are difficult to obtain. To cope with this situation, we introduce a new dataset called ETRI-Activity3D, focusing on the daily activities of the elderly in robot-view. The major characteristics of the new dataset are as follows: 1) practical action categories that are selected from the close observation of the daily lives of the elderly; 2) realistic data collection, which reflects the robot's working environment and service situations; and 3) a large-scale dataset that overcomes the limitations of the current 3D activity analysis benchmark datasets. The proposed dataset contains 112,620 samples including RGB videos, depth maps, and skeleton sequences. During the data acquisition, 100 subjects were asked to perform 55 daily activities. Additionally, we propose a novel network called four-stream adaptive CNN (FSA-CNN). The proposed FSA-CNN has three main properties: robustness to spatio-temporal variations, input-adaptive activation function, and extension of the conventional two-stream approach. In the experiment section, we confirmed the superiority of the proposed FSA-CNN using NTU RGB+D and ETRI-Activity3D. Further, the domain difference between both groups of age was verified experimentally. Finally, the extension of FSA-CNN to deal with the multimodal data was investigated.
Neural Networks with Activation Networks
Nov 21, 2018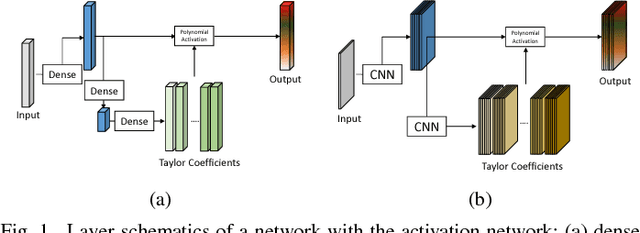
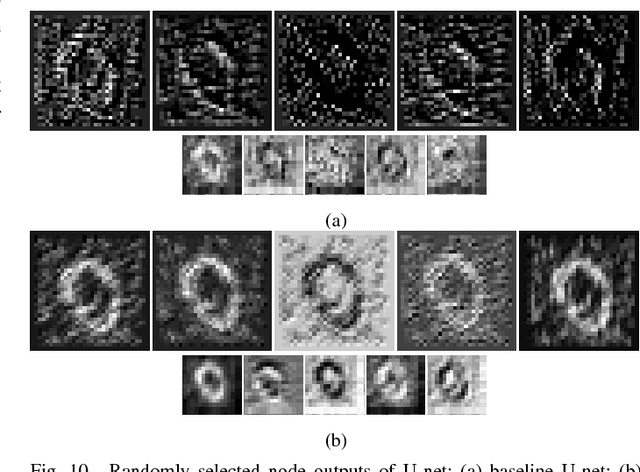
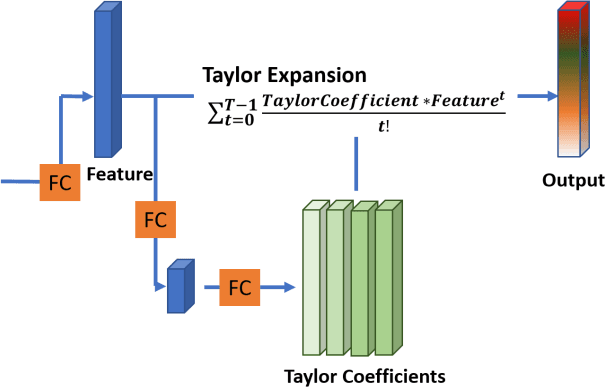
This work presents an adaptive activation method for neural networks that exploits the interdependency of features. Each pixel, node, and layer is assigned with a polynomial activation function, whose coefficients are provided by an auxiliary activation network. The activation of a feature depends on the features of neighboring pixels in a convolutional layer and other nodes in a dense layer. The dependency is learned from data by the activation networks. In our experiments, networks with activation networks provide significant performance improvement compared to the baseline networks on which they are built. The proposed method can be used to improve the network performance as an alternative to increasing the number of nodes and layers.
Optimal Architecture for Deep Neural Networks with Heterogeneous Sensitivity
Nov 02, 2018



This work presents a neural network that consists of nodes with heterogeneous sensitivity. Each node in a network is assigned a variable that determines the sensitivity with which it learns to perform a given task. The network is trained by a constrained optimization that minimizes the sparsity of the sensitivity variables while ensuring the network's performance. As a result, the network learns to perform a given task using only a small number of sensitive nodes. The L-curve is used to find a regularization parameter for the constrained optimization. To validate our approach, we design networks with optimal architectures for autoregression, object recognition, facial expression recognition, and object detection. In our experiments, the optimal networks designed by the proposed method provide the same or higher performance but with far less computational complexity.
Deep Asymmetric Networks with a Set of Node-wise Variant Activation Functions
Sep 11, 2018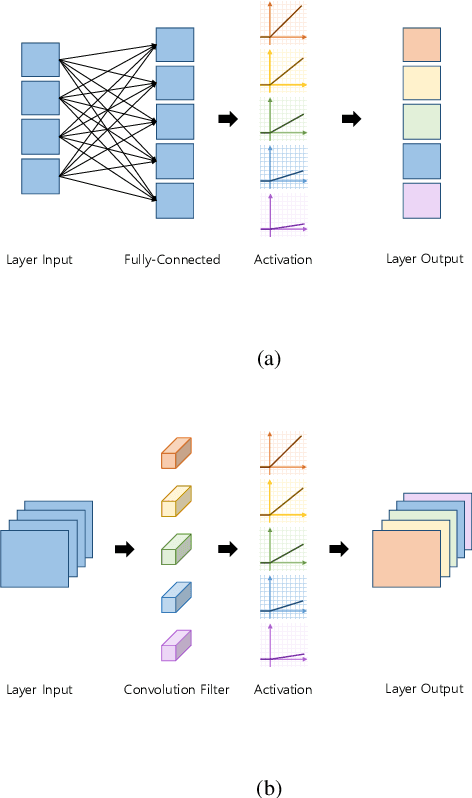



This work presents deep asymmetric networks with a set of node-wise variant activation functions. The nodes' sensitivities are affected by activation function selections such that the nodes with smaller indices become increasingly more sensitive. As a result, features learned by the nodes are sorted by the node indices in the order of their importance. Asymmetric networks not only learn input features but also the importance of those features. Nodes of lesser importance in asymmetric networks can be pruned to reduce the complexity of the networks, and the pruned networks can be retrained without incurring performance losses. We validate the feature-sorting property using both shallow and deep asymmetric networks as well as deep asymmetric networks transferred from famous networks.