 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoral Outrage Shapes Commitments Beyond Attention: Multimodal Moral Emotions on YouTube in Korea and the US
Jan 29, 2026Understanding how media rhetoric shapes audience engagement is crucial in the attention economy. This study examines how moral emotional framing by mainstream news channels on YouTube influences user behavior across Korea and the United States. To capture the platform's multimodal nature, combining thumbnail images and video titles, we develop a multimodal moral emotion classifier by fine tuning a vision language model. The model is trained on human annotated multimodal datasets in both languages and applied to approximately 400,000 videos from major news outlets. We analyze engagement levels including views, likes, and comments, representing increasing degrees of commitment. The results show that other condemning rhetoric expressions of moral outrage that criticize others morally consistently increase all forms of engagement across cultures, with effects ranging from passive viewing to active commenting. These findings suggest that moral outrage is a particularly effective emotional strategy, attracting not only attention but also active participation. We discuss concerns about the potential misuse of other condemning rhetoric, as such practices may deepen polarization by reinforcing in group and out group divisions. To facilitate future research and ensure reproducibility, we publicly release our Korean and English multimodal moral emotion classifiers.
Learning from Oblivion: Predicting Knowledge Overflowed Weights via Retrodiction of Forgetting
Aug 07, 2025Pre-trained weights have become a cornerstone of modern deep learning, enabling efficient knowledge transfer and improving downstream task performance, especially in data-scarce scenarios. However, a fundamental question remains: how can we obtain better pre-trained weights that encapsulate more knowledge beyond the given dataset? In this work, we introduce \textbf{KNowledge Overflowed Weights (KNOW)} prediction, a novel strategy that leverages structured forgetting and its inversion to synthesize knowledge-enriched weights. Our key insight is that sequential fine-tuning on progressively downsized datasets induces a structured forgetting process, which can be modeled and reversed to recover knowledge as if trained on a larger dataset. We construct a dataset of weight transitions governed by this controlled forgetting and employ meta-learning to model weight prediction effectively. Specifically, our \textbf{KNowledge Overflowed Weights Nowcaster (KNOWN)} acts as a hyper-model that learns the general evolution of weights and predicts enhanced weights with improved generalization. Extensive experiments across diverse datasets and architectures demonstrate that KNOW prediction consistently outperforms Na\"ive fine-tuning and simple weight prediction, leading to superior downstream performance. Our work provides a new perspective on reinterpreting forgetting dynamics to push the limits of knowledge transfer in deep learning.
Learning Dexterous Bimanual Catch Skills through Adversarial-Cooperative Heterogeneous-Agent Reinforcement Learning
Feb 17, 2025
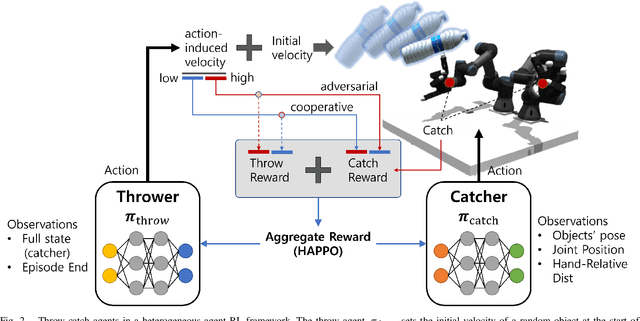


Robotic catching has traditionally focused on single-handed systems, which are limited in their ability to handle larger or more complex objects. In contrast, bimanual catching offers significant potential for improved dexterity and object handling but introduces new challenges in coordination and control. In this paper, we propose a novel framework for learning dexterous bimanual catching skills using Heterogeneous-Agent Reinforcement Learning (HARL). Our approach introduces an adversarial reward scheme, where a throw agent increases the difficulty of throws-adjusting speed-while a catch agent learns to coordinate both hands to catch objects under these evolving conditions. We evaluate the framework in simulated environments using 15 different objects, demonstrating robustness and versatility in handling diverse objects. Our method achieved approximately a 2x increase in catching reward compared to single-agent baselines across 15 diverse objects.
Space-Aware Instruction Tuning: Dataset and Benchmark for Guide Dog Robots Assisting the Visually Impaired
Feb 12, 2025



Guide dog robots offer promising solutions to enhance mobility and safety for visually impaired individuals, addressing the limitations of traditional guide dogs, particularly in perceptual intelligence and communication. With the emergence of Vision-Language Models (VLMs), robots are now capable of generating natural language descriptions of their surroundings, aiding in safer decision-making. However, existing VLMs often struggle to accurately interpret and convey spatial relationships, which is crucial for navigation in complex environments such as street crossings. We introduce the Space-Aware Instruction Tuning (SAIT) dataset and the Space-Aware Benchmark (SA-Bench) to address the limitations of current VLMs in understanding physical environments. Our automated data generation pipeline focuses on the virtual path to the destination in 3D space and the surroundings, enhancing environmental comprehension and enabling VLMs to provide more accurate guidance to visually impaired individuals. We also propose an evaluation protocol to assess VLM effectiveness in delivering walking guidance. Comparative experiments demonstrate that our space-aware instruction-tuned model outperforms state-of-the-art algorithms. We have fully open-sourced the SAIT dataset and SA-Bench, along with the related code, at https://github.com/byungokhan/Space-awareVLM
A Dual Process VLA: Efficient Robotic Manipulation Leveraging VLM
Oct 21, 2024



Vision-Language-Action (VLA) models are receiving increasing attention for their ability to enable robots to perform complex tasks by integrating visual context with linguistic commands. However, achieving efficient real-time performance remains challenging due to the high computational demands of existing models. To overcome this, we propose Dual Process VLA (DP-VLA), a hierarchical framework inspired by dual-process theory. DP-VLA utilizes a Large System 2 Model (L-Sys2) for complex reasoning and decision-making, while a Small System 1 Model (S-Sys1) handles real-time motor control and sensory processing. By leveraging Vision-Language Models (VLMs), the L-Sys2 operates at low frequencies, reducing computational overhead, while the S-Sys1 ensures fast and accurate task execution. Experimental results on the RoboCasa dataset demonstrate that DP-VLA achieves faster inference and higher task success rates, providing a scalable solution for advanced robotic applications.
Model Comparison for Fast Domain Adaptation in Table Service Scenario
Mar 08, 2024In restaurants, many aspects of customer service, such as greeting customers, taking orders, and processing payments, are automated. Due to the various cuisines, required services, and different standards of each restaurant, one challenging part of making the entire automated process is inspecting and providing appropriate services at the table during a meal. In this paper, we demonstrate an approach for automatically checking and providing services at the table. We initially construct a base model to recognize common information to comprehend the context of the table, such as object category, remaining food quantity, and meal progress status. After that, we add a service recognition classifier and retrain the model using a small amount of local restaurant data. We gathered data capturing the restaurant table during the meal in order to find a suitable service recognition classifier. With different inputs, combinations, time series, and data choices, we carried out a variety of tests. Through these tests, we discovered that the model with few significant data points and trainable parameters is more crucial in the case of sparse and redundant retraining data.
LoTa-Bench: Benchmarking Language-oriented Task Planners for Embodied Agents
Feb 13, 2024


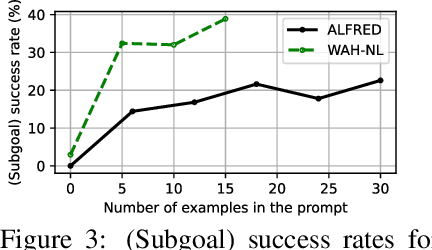
Large language models (LLMs) have recently received considerable attention as alternative solutions for task planning. However, comparing the performance of language-oriented task planners becomes difficult, and there exists a dearth of detailed exploration regarding the effects of various factors such as pre-trained model selection and prompt construction. To address this, we propose a benchmark system for automatically quantifying performance of task planning for home-service embodied agents. Task planners are tested on two pairs of datasets and simulators: 1) ALFRED and AI2-THOR, 2) an extension of Watch-And-Help and VirtualHome. Using the proposed benchmark system, we perform extensive experiments with LLMs and prompts, and explore several enhancements of the baseline planner. We expect that the proposed benchmark tool would accelerate the development of language-oriented task planners.
Uncertainty-Aware Shared Autonomy System with Hierarchical Conservative Skill Inference
Dec 05, 2023Shared autonomy imitation learning, in which robots share workspace with humans for learning, enables correct actions in unvisited states and the effective resolution of compounding errors through expert's corrections. However, it demands continuous human attention and supervision to lead the demonstrations, without considering the risks associated with human judgment errors and delayed interventions. This can potentially lead to high levels of fatigue for the demonstrator and the additional errors. In this work, we propose an uncertainty-aware shared autonomy system that enables the robot to infer conservative task skills considering environmental uncertainties and learning from expert demonstrations and corrections. To enhance generalization and scalability, we introduce a hierarchical structure-based skill uncertainty inference framework operating at more abstract levels. We apply this to robot motion to promote a more stable interaction. Although shared autonomy systems have demonstrated high-level results in recent research and play a critical role, specific system design details have remained elusive. This paper provides a detailed design proposal for a shared autonomy system considering various robot configurations. Furthermore, we experimentally demonstrate the system's capability to learn operational skills, even in dynamic environments with interference, through pouring and pick-and-place tasks. Our code will be released soon.
Nonverbal Social Behavior Generation for Social Robots Using End-to-End Learning
Nov 02, 2022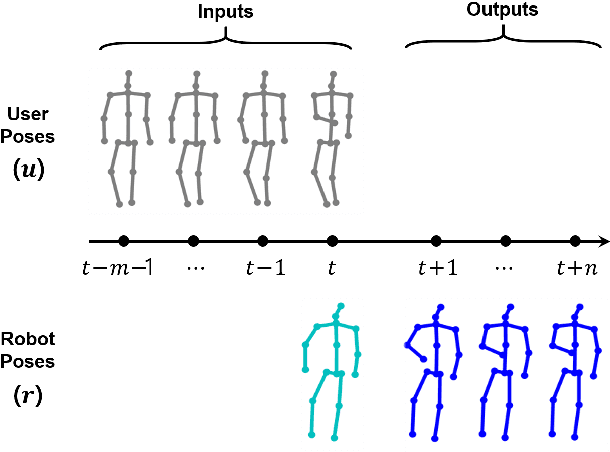

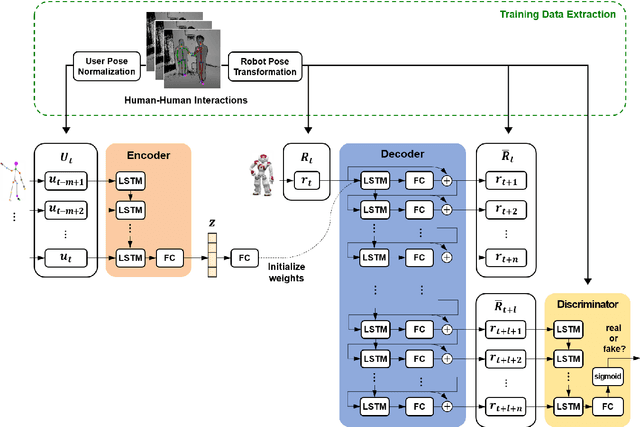

To provide effective and enjoyable human-robot interaction, it is important for social robots to exhibit nonverbal behaviors, such as a handshake or a hug. However, the traditional approach of reproducing pre-coded motions allows users to easily predict the reaction of the robot, giving the impression that the robot is a machine rather than a real agent. Therefore, we propose a neural network architecture based on the Seq2Seq model that learns social behaviors from human-human interactions in an end-to-end manner. We adopted a generative adversarial network to prevent invalid pose sequences from occurring when generating long-term behavior. To verify the proposed method, experiments were performed using the humanoid robot Pepper in a simulated environment. Because it is difficult to determine success or failure in social behavior generation, we propose new metrics to calculate the difference between the generated behavior and the ground-truth behavior. We used these metrics to show how different network architectural choices affect the performance of behavior generation, and we compared the performance of learning multiple behaviors and that of learning a single behavior. We expect that our proposed method can be used not only with home service robots, but also for guide robots, delivery robots, educational robots, and virtual robots, enabling the users to enjoy and effectively interact with the robots.
VOTE400: A Speech Dataset to Study Voice Interface for Elderly-Care
Jan 20, 2021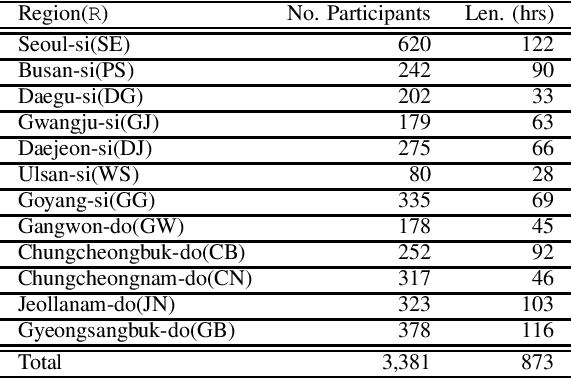
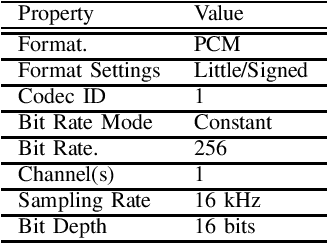
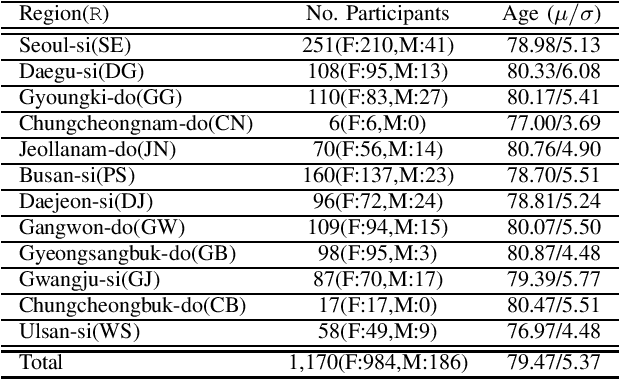
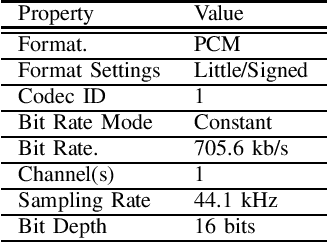
This paper introduces a large-scale Korean speech dataset, called VOTE400, that can be used for analyzing and recognizing voices of the elderly people. The dataset includes about 300 hours of continuous dialog speech and 100 hours of read speech, both recorded by the elderly people aged 65 years or over. A preliminary experiment showed that speech recognition system trained with VOTE400 can outperform conventional systems in speech recognition of elderly people's voice. This work is a multi-organizational effort led by ETRI and MINDs Lab Inc. for the purpose of advancing the speech recognition performance of the elderly-care robots.