 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace-Aware Instruction Tuning: Dataset and Benchmark for Guide Dog Robots Assisting the Visually Impaired
Feb 12, 2025



Guide dog robots offer promising solutions to enhance mobility and safety for visually impaired individuals, addressing the limitations of traditional guide dogs, particularly in perceptual intelligence and communication. With the emergence of Vision-Language Models (VLMs), robots are now capable of generating natural language descriptions of their surroundings, aiding in safer decision-making. However, existing VLMs often struggle to accurately interpret and convey spatial relationships, which is crucial for navigation in complex environments such as street crossings. We introduce the Space-Aware Instruction Tuning (SAIT) dataset and the Space-Aware Benchmark (SA-Bench) to address the limitations of current VLMs in understanding physical environments. Our automated data generation pipeline focuses on the virtual path to the destination in 3D space and the surroundings, enhancing environmental comprehension and enabling VLMs to provide more accurate guidance to visually impaired individuals. We also propose an evaluation protocol to assess VLM effectiveness in delivering walking guidance. Comparative experiments demonstrate that our space-aware instruction-tuned model outperforms state-of-the-art algorithms. We have fully open-sourced the SAIT dataset and SA-Bench, along with the related code, at https://github.com/byungokhan/Space-awareVLM
Rank Selection of CP-decomposed Convolutional Layers with Variational Bayesian Matrix Factorization
Jan 16, 2018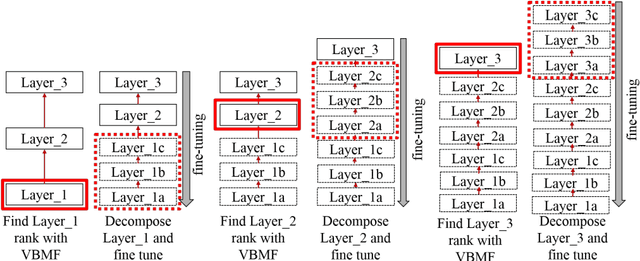
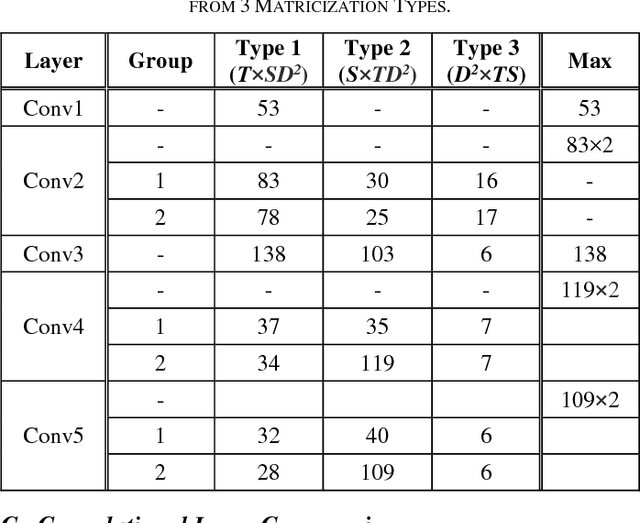
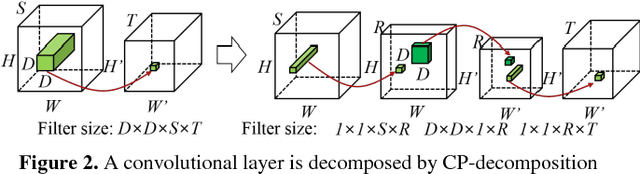

Convolutional Neural Networks (CNNs) is one of successful method in many areas such as image classification tasks. However, the amount of memory and computational cost needed for CNNs inference obstructs them to run efficiently in mobile devices because of memory and computational ability limitation. One of the method to compress CNNs is compressing the layers iteratively, i.e. by layer-by-layer compression and fine-tuning, with CP-decomposition in convolutional layers. To compress with CP-decomposition, rank selection is important. In the previous approach rank selection that is based on sensitivity of each layer, the average rank of the network was still arbitrarily selected. Additionally, the rank of all layers were decided before whole process of iterative compression, while the rank of a layer can be changed after fine-tuning. Therefore, this paper proposes selecting rank of each layer using Variational Bayesian Matrix Factorization (VBMF) which is more systematic than arbitrary approach. Furthermore, to consider the change of each layer's rank after fine-tuning of previous iteration, the method is applied just before compressing the target layer, i.e. after fine-tuning of the previous iteration. The results show better accuracy while also having more compression rate in AlexNet's convolutional layers compression.