 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace-Aware Instruction Tuning: Dataset and Benchmark for Guide Dog Robots Assisting the Visually Impaired
Feb 12, 2025



Guide dog robots offer promising solutions to enhance mobility and safety for visually impaired individuals, addressing the limitations of traditional guide dogs, particularly in perceptual intelligence and communication. With the emergence of Vision-Language Models (VLMs), robots are now capable of generating natural language descriptions of their surroundings, aiding in safer decision-making. However, existing VLMs often struggle to accurately interpret and convey spatial relationships, which is crucial for navigation in complex environments such as street crossings. We introduce the Space-Aware Instruction Tuning (SAIT) dataset and the Space-Aware Benchmark (SA-Bench) to address the limitations of current VLMs in understanding physical environments. Our automated data generation pipeline focuses on the virtual path to the destination in 3D space and the surroundings, enhancing environmental comprehension and enabling VLMs to provide more accurate guidance to visually impaired individuals. We also propose an evaluation protocol to assess VLM effectiveness in delivering walking guidance. Comparative experiments demonstrate that our space-aware instruction-tuned model outperforms state-of-the-art algorithms. We have fully open-sourced the SAIT dataset and SA-Bench, along with the related code, at https://github.com/byungokhan/Space-awareVLM
Model Comparison for Fast Domain Adaptation in Table Service Scenario
Mar 08, 2024In restaurants, many aspects of customer service, such as greeting customers, taking orders, and processing payments, are automated. Due to the various cuisines, required services, and different standards of each restaurant, one challenging part of making the entire automated process is inspecting and providing appropriate services at the table during a meal. In this paper, we demonstrate an approach for automatically checking and providing services at the table. We initially construct a base model to recognize common information to comprehend the context of the table, such as object category, remaining food quantity, and meal progress status. After that, we add a service recognition classifier and retrain the model using a small amount of local restaurant data. We gathered data capturing the restaurant table during the meal in order to find a suitable service recognition classifier. With different inputs, combinations, time series, and data choices, we carried out a variety of tests. Through these tests, we discovered that the model with few significant data points and trainable parameters is more crucial in the case of sparse and redundant retraining data.
Balancing Domain Gap for Object Instance Detection
Sep 26, 2019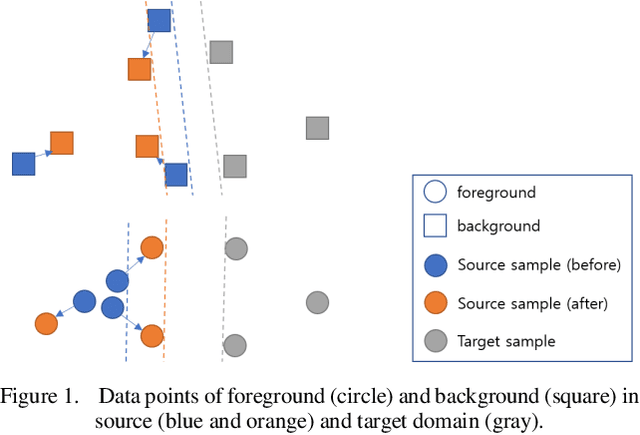
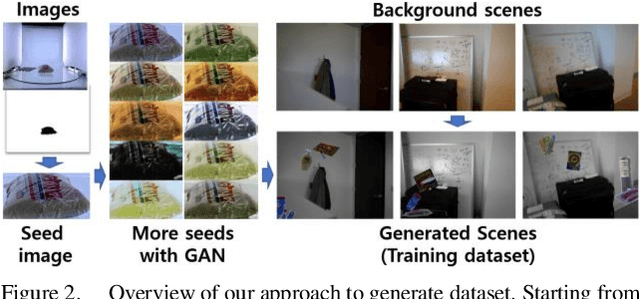


Object instance detection in cluttered indoor environment is a core functionality for service robots. We can readily build a detection system by following recent successful strategy of deep convolutional neural networks, if we have a large annotated dataset. However, it is hard to prepare such a huge dataset in instance detection problem where only small number of samples are available. This is one of main impediment to deploying an object detection system. To overcome this obstacle, many approaches to generate synthetic dataset have been proposed. These approaches confront the domain gap or reality gap problem stems from discrepancy between source domain (synthetic training dataset) and target domain (real test dataset). In this paper, we propose a simple approach to generate a synthetic dataset with minimum human effort. Especially, we identify that domain gaps of foreground and background are unbalanced and propose methods to balance these gaps. In the experiment, we verify that our methods help domain gaps to balance and improve the accuracy of object instance detection in cluttered indoor environment.