 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAA-X: Unified Localized Artifact Attention for Quality-Agnostic and Generalizable Face Forgery Detection
Apr 05, 2026In this paper, we propose Localized Artifact Attention X (LAA-X), a novel deepfake detection framework that is both robust to high-quality forgeries and capable of generalizing to unseen manipulations. Existing approaches typically rely on binary classifiers coupled with implicit attention mechanisms, which often fail to generalize beyond known manipulations. In contrast, LAA-X introduces an explicit attention strategy based on a multi-task learning framework combined with blending-based data synthesis. Auxiliary tasks are designed to guide the model toward localized, artifact-prone (i.e., vulnerable) regions. The proposed framework is compatible with both CNN and transformer backbones, resulting in two different versions, namely, LAA-Net and LAA-Former, respectively. Despite being trained only on real and pseudo-fake samples, LAA-X competes with state-of-the-art methods across multiple benchmarks. Code and pre-trained weights for LAA-Net\footnote{https://github.com/10Ring/LAA-Net} and LAA-Former\footnote{https://github.com/10Ring/LAA-Former} are publicly available.
Zero-Shot Anomaly Detection in Battery Thermal Images Using Visual Question Answering with Prior Knowledge
May 22, 2025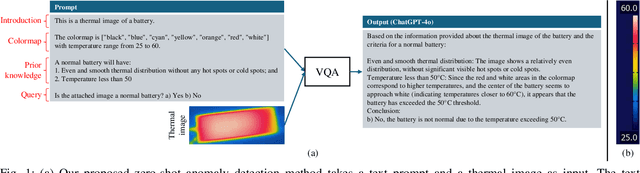

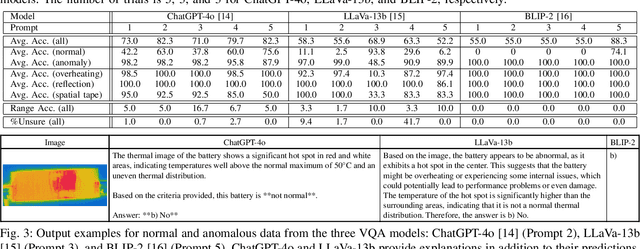
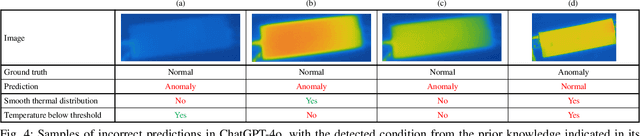
Batteries are essential for various applications, including electric vehicles and renewable energy storage, making safety and efficiency critical concerns. Anomaly detection in battery thermal images helps identify failures early, but traditional deep learning methods require extensive labeled data, which is difficult to obtain, especially for anomalies due to safety risks and high data collection costs. To overcome this, we explore zero-shot anomaly detection using Visual Question Answering (VQA) models, which leverage pretrained knowledge and textbased prompts to generalize across vision tasks. By incorporating prior knowledge of normal battery thermal behavior, we design prompts to detect anomalies without battery-specific training data. We evaluate three VQA models (ChatGPT-4o, LLaVa-13b, and BLIP-2) analyzing their robustness to prompt variations, repeated trials, and qualitative outputs. Despite the lack of finetuning on battery data, our approach demonstrates competitive performance compared to state-of-the-art models that are trained with the battery data. Our findings highlight the potential of VQA-based zero-shot learning for battery anomaly detection and suggest future directions for improving its effectiveness.
Audio-visual Deepfake Detection With Local Temporal Inconsistencies
Jan 14, 2025



This paper proposes an audio-visual deepfake detection approach that aims to capture fine-grained temporal inconsistencies between audio and visual modalities. To achieve this, both architectural and data synthesis strategies are introduced. From an architectural perspective, a temporal distance map, coupled with an attention mechanism, is designed to capture these inconsistencies while minimizing the impact of irrelevant temporal subsequences. Moreover, we explore novel pseudo-fake generation techniques to synthesize local inconsistencies. Our approach is evaluated against state-of-the-art methods using the DFDC and FakeAVCeleb datasets, demonstrating its effectiveness in detecting audio-visual deepfakes.
Vulnerability-Aware Spatio-Temporal Learning for Generalizable and Interpretable Deepfake Video Detection
Jan 02, 2025



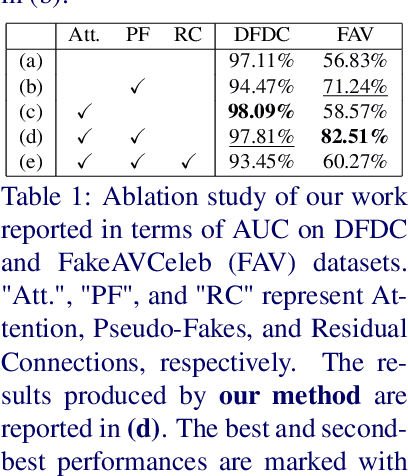
Detecting deepfake videos is highly challenging due to the complex intertwined spatial and temporal artifacts in forged sequences. Most recent approaches rely on binary classifiers trained on both real and fake data. However, such methods may struggle to focus on important artifacts, which can hinder their generalization capability. Additionally, these models often lack interpretability, making it difficult to understand how predictions are made. To address these issues, we propose FakeSTormer, offering two key contributions. First, we introduce a multi-task learning framework with additional spatial and temporal branches that enable the model to focus on subtle spatio-temporal artifacts. These branches also provide interpretability by highlighting video regions that may contain artifacts. Second, we propose a video-level data synthesis algorithm that generates pseudo-fake videos with subtle artifacts, providing the model with high-quality samples and ground truth data for our spatial and temporal branches. Extensive experiments on several challenging benchmarks demonstrate the competitiveness of our approach compared to recent state-of-the-art methods. The code is available at https://github.com/10Ring/FakeSTormer.
FakeFormer: Efficient Vulnerability-Driven Transformers for Generalisable Deepfake Detection
Oct 29, 2024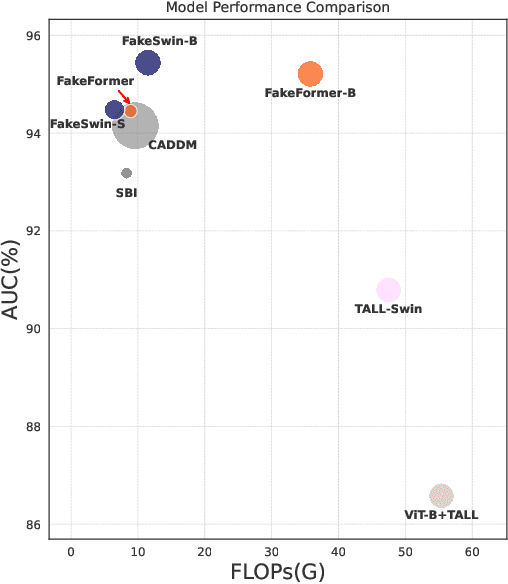

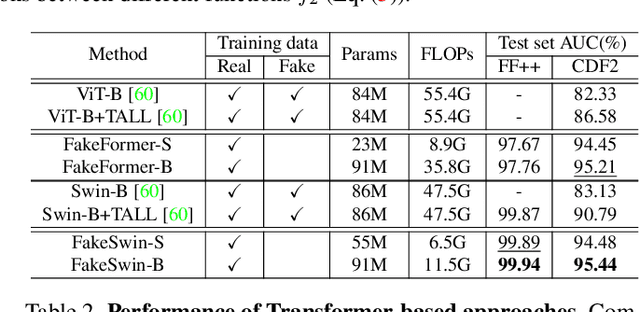
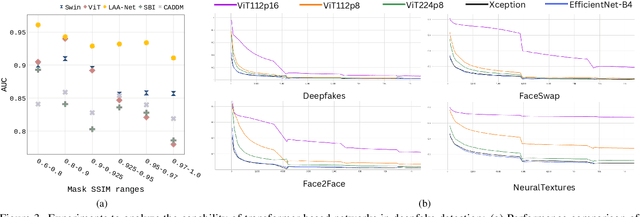
Recently, Vision Transformers (ViTs) have achieved unprecedented effectiveness in the general domain of image classification. Nonetheless, these models remain underexplored in the field of deepfake detection, given their lower performance as compared to Convolution Neural Networks (CNNs) in that specific context. In this paper, we start by investigating why plain ViT architectures exhibit a suboptimal performance when dealing with the detection of facial forgeries. Our analysis reveals that, as compared to CNNs, ViT struggles to model localized forgery artifacts that typically characterize deepfakes. Based on this observation, we propose a deepfake detection framework called FakeFormer, which extends ViTs to enforce the extraction of subtle inconsistency-prone information. For that purpose, an explicit attention learning guided by artifact-vulnerable patches and tailored to ViTs is introduced. Extensive experiments are conducted on diverse well-known datasets, including FF++, Celeb-DF, WildDeepfake, DFD, DFDCP, and DFDC. The results show that FakeFormer outperforms the state-of-the-art in terms of generalization and computational cost, without the need for large-scale training datasets. The code is available at \url{https://github.com/10Ring/FakeFormer}.
Detecting Audio-Visual Deepfakes with Fine-Grained Inconsistencies
Aug 14, 2024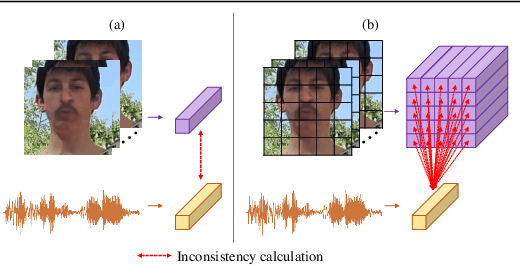
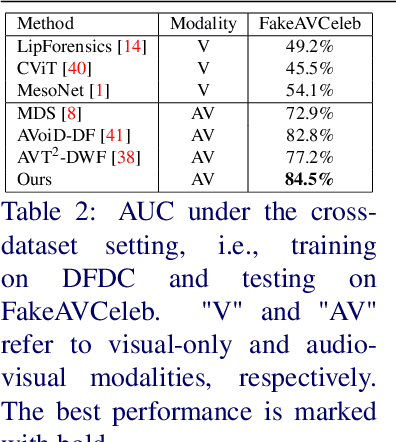
Existing methods on audio-visual deepfake detection mainly focus on high-level features for modeling inconsistencies between audio and visual data. As a result, these approaches usually overlook finer audio-visual artifacts, which are inherent to deepfakes. Herein, we propose the introduction of fine-grained mechanisms for detecting subtle artifacts in both spatial and temporal domains. First, we introduce a local audio-visual model capable of capturing small spatial regions that are prone to inconsistencies with audio. For that purpose, a fine-grained mechanism based on a spatially-local distance coupled with an attention module is adopted. Second, we introduce a temporally-local pseudo-fake augmentation to include samples incorporating subtle temporal inconsistencies in our training set. Experiments on the DFDC and the FakeAVCeleb datasets demonstrate the superiority of the proposed method in terms of generalization as compared to the state-of-the-art under both in-dataset and cross-dataset settings.
Statistics-aware Audio-visual Deepfake Detector
Jul 16, 2024In this paper, we propose an enhanced audio-visual deep detection method. Recent methods in audio-visual deepfake detection mostly assess the synchronization between audio and visual features. Although they have shown promising results, they are based on the maximization/minimization of isolated feature distances without considering feature statistics. Moreover, they rely on cumbersome deep learning architectures and are heavily dependent on empirically fixed hyperparameters. Herein, to overcome these limitations, we propose: (1) a statistical feature loss to enhance the discrimination capability of the model, instead of relying solely on feature distances; (2) using the waveform for describing the audio as a replacement of frequency-based representations; (3) a post-processing normalization of the fakeness score; (4) the use of shallower network for reducing the computational complexity. Experiments on the DFDC and FakeAVCeleb datasets demonstrate the relevance of the proposed method.
Targeted Augmented Data for Audio Deepfake Detection
Jul 10, 2024The availability of highly convincing audio deepfake generators highlights the need for designing robust audio deepfake detectors. Existing works often rely solely on real and fake data available in the training set, which may lead to overfitting, thereby reducing the robustness to unseen manipulations. To enhance the generalization capabilities of audio deepfake detectors, we propose a novel augmentation method for generating audio pseudo-fakes targeting the decision boundary of the model. Inspired by adversarial attacks, we perturb original real data to synthesize pseudo-fakes with ambiguous prediction probabilities. Comprehensive experiments on two well-known architectures demonstrate that the proposed augmentation contributes to improving the generalization capabilities of these architectures.
Exploiting Autoencoder's Weakness to Generate Pseudo Anomalies
May 09, 2024Due to the rare occurrence of anomalous events, a typical approach to anomaly detection is to train an autoencoder (AE) with normal data only so that it learns the patterns or representations of the normal training data. At test time, the trained AE is expected to well reconstruct normal but to poorly reconstruct anomalous data. However, contrary to the expectation, anomalous data is often well reconstructed as well. In order to further separate the reconstruction quality between normal and anomalous data, we propose creating pseudo anomalies from learned adaptive noise by exploiting the aforementioned weakness of AE, i.e., reconstructing anomalies too well. The generated noise is added to the normal data to create pseudo anomalies. Extensive experiments on Ped2, Avenue, ShanghaiTech, CIFAR-10, and KDDCUP datasets demonstrate the effectiveness and generic applicability of our approach in improving the discriminative capability of AEs for anomaly detection.
* SharedIt link: https://rdcu.be/dGOrh
Constricting Normal Latent Space for Anomaly Detection with Normal-only Training Data
Mar 24, 2024



In order to devise an anomaly detection model using only normal training data, an autoencoder (AE) is typically trained to reconstruct the data. As a result, the AE can extract normal representations in its latent space. During test time, since AE is not trained using real anomalies, it is expected to poorly reconstruct the anomalous data. However, several researchers have observed that it is not the case. In this work, we propose to limit the reconstruction capability of AE by introducing a novel latent constriction loss, which is added to the existing reconstruction loss. By using our method, no extra computational cost is added to the AE during test time. Evaluations using three video anomaly detection benchmark datasets, i.e., Ped2, Avenue, and ShanghaiTech, demonstrate the effectiveness of our method in limiting the reconstruction capability of AE, which leads to a better anomaly detection model.