 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Multi-label Image Classification: a Discriminator-free Approach
May 20, 2025This paper introduces a discriminator-free adversarial-based approach termed DDA-MLIC for Unsupervised Domain Adaptation (UDA) in the context of Multi-Label Image Classification (MLIC). While recent efforts have explored adversarial-based UDA methods for MLIC, they typically include an additional discriminator subnet. Nevertheless, decoupling the classification and the discrimination tasks may harm their task-specific discriminative power. Herein, we address this challenge by presenting a novel adversarial critic directly derived from the task-specific classifier. Specifically, we employ a two-component Gaussian Mixture Model (GMM) to model both source and target predictions, distinguishing between two distinct clusters. Instead of using the traditional Expectation Maximization (EM) algorithm, our approach utilizes a Deep Neural Network (DNN) to estimate the parameters of each GMM component. Subsequently, the source and target GMM parameters are leveraged to formulate an adversarial loss using the Fr\'echet distance. The proposed framework is therefore not only fully differentiable but is also cost-effective as it avoids the expensive iterative process usually induced by the standard EM method. The proposed method is evaluated on several multi-label image datasets covering three different types of domain shift. The obtained results demonstrate that DDA-MLIC outperforms existing state-of-the-art methods in terms of precision while requiring a lower number of parameters. The code is made publicly available at github.com/cvi2snt/DDA-MLIC.
Uncertainty-Aware Knowledge Distillation for Compact and Efficient 6DoF Pose Estimation
Mar 17, 2025Compact and efficient 6DoF object pose estimation is crucial in applications such as robotics, augmented reality, and space autonomous navigation systems, where lightweight models are critical for real-time accurate performance. This paper introduces a novel uncertainty-aware end-to-end Knowledge Distillation (KD) framework focused on keypoint-based 6DoF pose estimation. Keypoints predicted by a large teacher model exhibit varying levels of uncertainty that can be exploited within the distillation process to enhance the accuracy of the student model while ensuring its compactness. To this end, we propose a distillation strategy that aligns the student and teacher predictions by adjusting the knowledge transfer based on the uncertainty associated with each teacher keypoint prediction. Additionally, the proposed KD leverages this uncertainty-aware alignment of keypoints to transfer the knowledge at key locations of their respective feature maps. Experiments on the widely-used LINEMOD benchmark demonstrate the effectiveness of our method, achieving superior 6DoF object pose estimation with lightweight models compared to state-of-the-art approaches. Further validation on the SPEED+ dataset for spacecraft pose estimation highlights the robustness of our approach under diverse 6DoF pose estimation scenarios.
When Unsupervised Domain Adaptation meets One-class Anomaly Detection: Addressing the Two-fold Unsupervised Curse by Leveraging Anomaly Scarcity
Feb 28, 2025This paper introduces the first fully unsupervised domain adaptation (UDA) framework for unsupervised anomaly detection (UAD). The performance of UAD techniques degrades significantly in the presence of a domain shift, difficult to avoid in a real-world setting. While UDA has contributed to solving this issue in binary and multi-class classification, such a strategy is ill-posed in UAD. This might be explained by the unsupervised nature of the two tasks, namely, domain adaptation and anomaly detection. Herein, we first formulate this problem that we call the two-fold unsupervised curse. Then, we propose a pioneering solution to this curse, considered intractable so far, by assuming that anomalies are rare. Specifically, we leverage clustering techniques to identify a dominant cluster in the target feature space. Posed as the normal cluster, the latter is aligned with the source normal features. Concretely, given a one-class source set and an unlabeled target set composed mostly of normal data and some anomalies, we fit the source features within a hypersphere while jointly aligning them with the features of the dominant cluster from the target set. The paper provides extensive experiments and analysis on common adaptation benchmarks for anomaly detection, demonstrating the relevance of both the newly introduced paradigm and the proposed approach. The code will be made publicly available.
Audio-visual Deepfake Detection With Local Temporal Inconsistencies
Jan 14, 2025



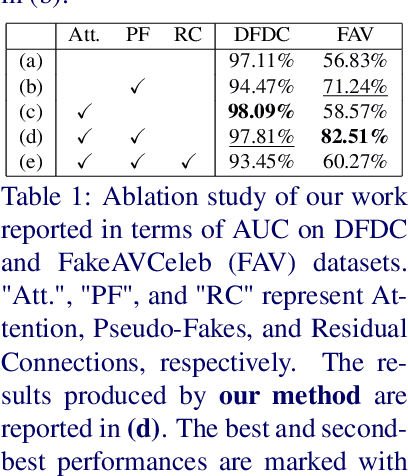
This paper proposes an audio-visual deepfake detection approach that aims to capture fine-grained temporal inconsistencies between audio and visual modalities. To achieve this, both architectural and data synthesis strategies are introduced. From an architectural perspective, a temporal distance map, coupled with an attention mechanism, is designed to capture these inconsistencies while minimizing the impact of irrelevant temporal subsequences. Moreover, we explore novel pseudo-fake generation techniques to synthesize local inconsistencies. Our approach is evaluated against state-of-the-art methods using the DFDC and FakeAVCeleb datasets, demonstrating its effectiveness in detecting audio-visual deepfakes.
Vulnerability-Aware Spatio-Temporal Learning for Generalizable and Interpretable Deepfake Video Detection
Jan 02, 2025



Detecting deepfake videos is highly challenging due to the complex intertwined spatial and temporal artifacts in forged sequences. Most recent approaches rely on binary classifiers trained on both real and fake data. However, such methods may struggle to focus on important artifacts, which can hinder their generalization capability. Additionally, these models often lack interpretability, making it difficult to understand how predictions are made. To address these issues, we propose FakeSTormer, offering two key contributions. First, we introduce a multi-task learning framework with additional spatial and temporal branches that enable the model to focus on subtle spatio-temporal artifacts. These branches also provide interpretability by highlighting video regions that may contain artifacts. Second, we propose a video-level data synthesis algorithm that generates pseudo-fake videos with subtle artifacts, providing the model with high-quality samples and ground truth data for our spatial and temporal branches. Extensive experiments on several challenging benchmarks demonstrate the competitiveness of our approach compared to recent state-of-the-art methods. The code is available at https://github.com/10Ring/FakeSTormer.
FakeFormer: Efficient Vulnerability-Driven Transformers for Generalisable Deepfake Detection
Oct 29, 2024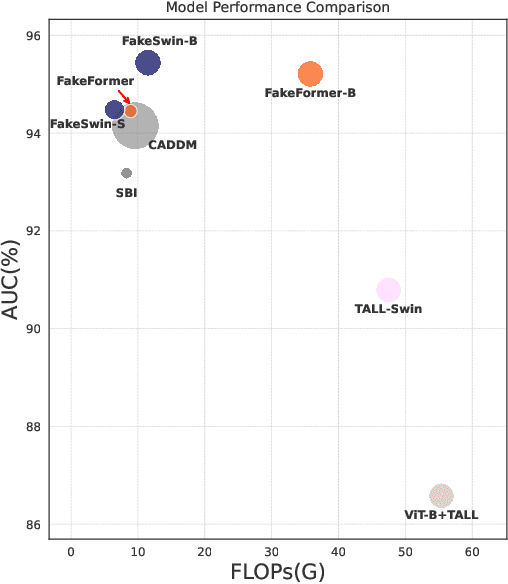

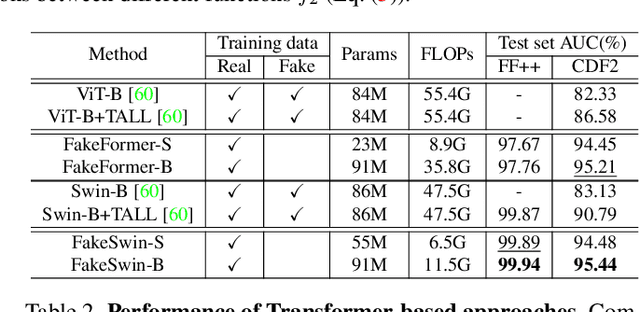
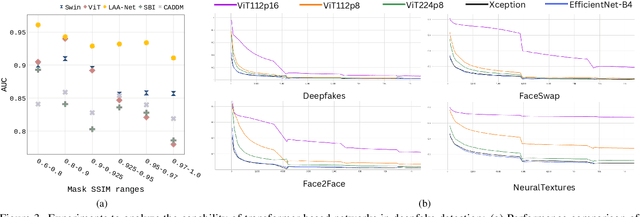
Recently, Vision Transformers (ViTs) have achieved unprecedented effectiveness in the general domain of image classification. Nonetheless, these models remain underexplored in the field of deepfake detection, given their lower performance as compared to Convolution Neural Networks (CNNs) in that specific context. In this paper, we start by investigating why plain ViT architectures exhibit a suboptimal performance when dealing with the detection of facial forgeries. Our analysis reveals that, as compared to CNNs, ViT struggles to model localized forgery artifacts that typically characterize deepfakes. Based on this observation, we propose a deepfake detection framework called FakeFormer, which extends ViTs to enforce the extraction of subtle inconsistency-prone information. For that purpose, an explicit attention learning guided by artifact-vulnerable patches and tailored to ViTs is introduced. Extensive experiments are conducted on diverse well-known datasets, including FF++, Celeb-DF, WildDeepfake, DFD, DFDCP, and DFDC. The results show that FakeFormer outperforms the state-of-the-art in terms of generalization and computational cost, without the need for large-scale training datasets. The code is available at \url{https://github.com/10Ring/FakeFormer}.
A Hitchhikers Guide to Fine-Grained Face Forgery Detection Using Common Sense Reasoning
Oct 01, 2024

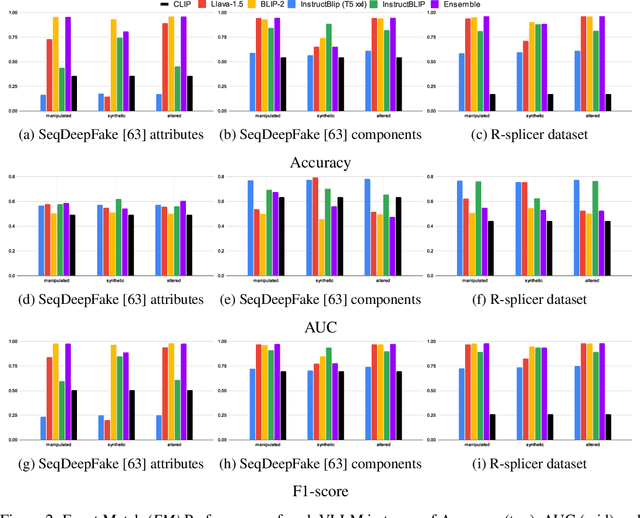

Explainability in artificial intelligence is crucial for restoring trust, particularly in areas like face forgery detection, where viewers often struggle to distinguish between real and fabricated content. Vision and Large Language Models (VLLM) bridge computer vision and natural language, offering numerous applications driven by strong common-sense reasoning. Despite their success in various tasks, the potential of vision and language remains underexplored in face forgery detection, where they hold promise for enhancing explainability by leveraging the intrinsic reasoning capabilities of language to analyse fine-grained manipulation areas. As such, there is a need for a methodology that converts face forgery detection to a Visual Question Answering (VQA) task to systematically and fairly evaluate these capabilities. Previous efforts for unified benchmarks in deepfake detection have focused on the simpler binary task, overlooking evaluation protocols for fine-grained detection and text-generative models. We propose a multi-staged approach that diverges from the traditional binary decision paradigm to address this gap. In the first stage, we assess the models' performance on the binary task and their sensitivity to given instructions using several prompts. In the second stage, we delve deeper into fine-grained detection by identifying areas of manipulation in a multiple-choice VQA setting. In the third stage, we convert the fine-grained detection to an open-ended question and compare several matching strategies for the multi-label classification task. Finally, we qualitatively evaluate the fine-grained responses of the VLLMs included in the benchmark. We apply our benchmark to several popular models, providing a detailed comparison of binary, multiple-choice, and open-ended VQA evaluation across seven datasets. \url{https://nickyfot.github.io/hitchhickersguide.github.io/}
Detecting Audio-Visual Deepfakes with Fine-Grained Inconsistencies
Aug 14, 2024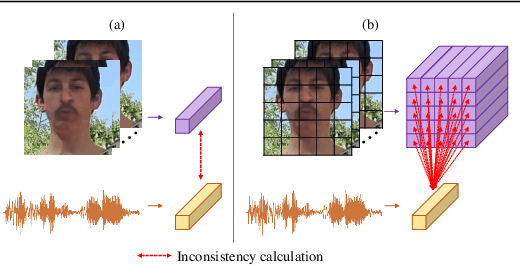
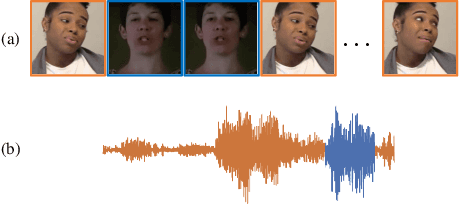
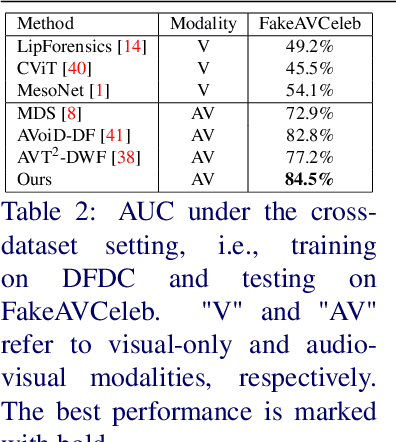
Existing methods on audio-visual deepfake detection mainly focus on high-level features for modeling inconsistencies between audio and visual data. As a result, these approaches usually overlook finer audio-visual artifacts, which are inherent to deepfakes. Herein, we propose the introduction of fine-grained mechanisms for detecting subtle artifacts in both spatial and temporal domains. First, we introduce a local audio-visual model capable of capturing small spatial regions that are prone to inconsistencies with audio. For that purpose, a fine-grained mechanism based on a spatially-local distance coupled with an attention module is adopted. Second, we introduce a temporally-local pseudo-fake augmentation to include samples incorporating subtle temporal inconsistencies in our training set. Experiments on the DFDC and the FakeAVCeleb datasets demonstrate the superiority of the proposed method in terms of generalization as compared to the state-of-the-art under both in-dataset and cross-dataset settings.
Statistics-aware Audio-visual Deepfake Detector
Jul 16, 2024In this paper, we propose an enhanced audio-visual deep detection method. Recent methods in audio-visual deepfake detection mostly assess the synchronization between audio and visual features. Although they have shown promising results, they are based on the maximization/minimization of isolated feature distances without considering feature statistics. Moreover, they rely on cumbersome deep learning architectures and are heavily dependent on empirically fixed hyperparameters. Herein, to overcome these limitations, we propose: (1) a statistical feature loss to enhance the discrimination capability of the model, instead of relying solely on feature distances; (2) using the waveform for describing the audio as a replacement of frequency-based representations; (3) a post-processing normalization of the fakeness score; (4) the use of shallower network for reducing the computational complexity. Experiments on the DFDC and FakeAVCeleb datasets demonstrate the relevance of the proposed method.
Targeted Augmented Data for Audio Deepfake Detection
Jul 10, 2024The availability of highly convincing audio deepfake generators highlights the need for designing robust audio deepfake detectors. Existing works often rely solely on real and fake data available in the training set, which may lead to overfitting, thereby reducing the robustness to unseen manipulations. To enhance the generalization capabilities of audio deepfake detectors, we propose a novel augmentation method for generating audio pseudo-fakes targeting the decision boundary of the model. Inspired by adversarial attacks, we perturb original real data to synthesize pseudo-fakes with ambiguous prediction probabilities. Comprehensive experiments on two well-known architectures demonstrate that the proposed augmentation contributes to improving the generalization capabilities of these architectures.