 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeFormer: Efficient Vulnerability-Driven Transformers for Generalisable Deepfake Detection
Paper and Code
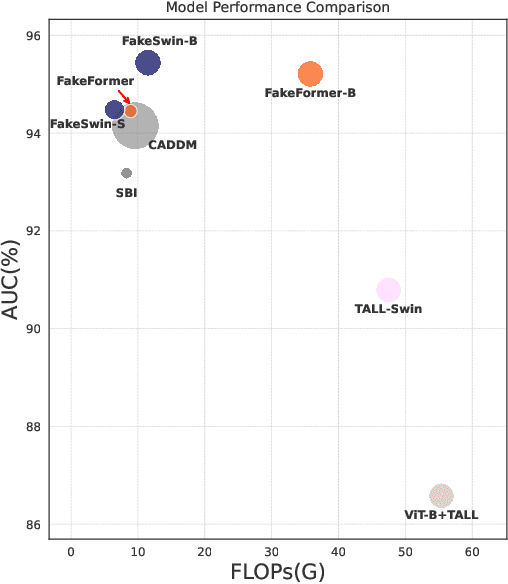

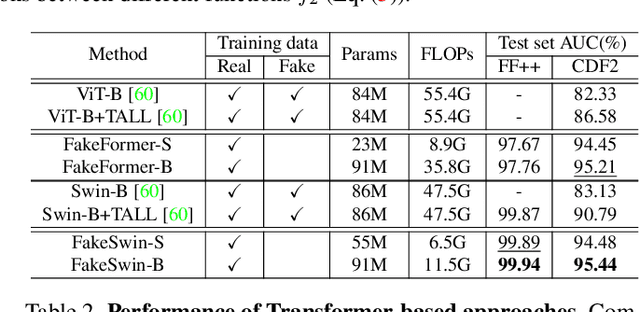
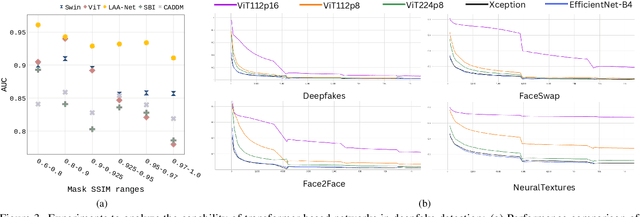
Recently, Vision Transformers (ViTs) have achieved unprecedented effectiveness in the general domain of image classification. Nonetheless, these models remain underexplored in the field of deepfake detection, given their lower performance as compared to Convolution Neural Networks (CNNs) in that specific context. In this paper, we start by investigating why plain ViT architectures exhibit a suboptimal performance when dealing with the detection of facial forgeries. Our analysis reveals that, as compared to CNNs, ViT struggles to model localized forgery artifacts that typically characterize deepfakes. Based on this observation, we propose a deepfake detection framework called FakeFormer, which extends ViTs to enforce the extraction of subtle inconsistency-prone information. For that purpose, an explicit attention learning guided by artifact-vulnerable patches and tailored to ViTs is introduced. Extensive experiments are conducted on diverse well-known datasets, including FF++, Celeb-DF, WildDeepfake, DFD, DFDCP, and DFDC. The results show that FakeFormer outperforms the state-of-the-art in terms of generalization and computational cost, without the need for large-scale training datasets. The code is available at \url{https://github.com/10Ring/FakeFormer}.