 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenEarthAgent: A Unified Framework for Tool-Augmented Geospatial Agents
Feb 19, 2026Recent progress in multimodal reasoning has enabled agents that can interpret imagery, connect it with language, and perform structured analytical tasks. Extending such capabilities to the remote sensing domain remains challenging, as models must reason over spatial scale, geographic structures, and multispectral indices while maintaining coherent multi-step logic. To bridge this gap, OpenEarthAgent introduces a unified framework for developing tool-augmented geospatial agents trained on satellite imagery, natural-language queries, and detailed reasoning traces. The training pipeline relies on supervised fine-tuning over structured reasoning trajectories, aligning the model with verified multistep tool interactions across diverse analytical contexts. The accompanying corpus comprises 14,538 training and 1,169 evaluation instances, with more than 100K reasoning steps in the training split and over 7K reasoning steps in the evaluation split. It spans urban, environmental, disaster, and infrastructure domains, and incorporates GIS-based operations alongside index analyses such as NDVI, NBR, and NDBI. Grounded in explicit reasoning traces, the learned agent demonstrates structured reasoning, stable spatial understanding, and interpretable behaviour through tool-driven geospatial interactions across diverse conditions. We report consistent improvements over a strong baseline and competitive performance relative to recent open and closed-source models.
Face-Voice Association with Inductive Bias for Maximum Class Separation
Jan 20, 2026Face-voice association is widely studied in multimodal learning and is approached representing faces and voices with embeddings that are close for a same person and well separated from those of others. Previous work achieved this with loss functions. Recent advancements in classification have shown that the discriminative ability of embeddings can be strengthened by imposing maximum class separation as inductive bias. This technique has never been used in the domain of face-voice association, and this work aims at filling this gap. More specifically, we develop a method for face-voice association that imposes maximum class separation among multimodal representations of different speakers as an inductive bias. Through quantitative experiments we demonstrate the effectiveness of our approach, showing that it achieves SOTA performance on two task formulation of face-voice association. Furthermore, we carry out an ablation study to show that imposing inductive bias is most effective when combined with losses for inter-class orthogonality. To the best of our knowledge, this work is the first that applies and demonstrates the effectiveness of maximum class separation as an inductive bias in multimodal learning; it hence paves the way to establish a new paradigm.
Linking Faces and Voices Across Languages: Insights from the FAME 2026 Challenge
Dec 23, 2025Over half of the world's population is bilingual and people often communicate under multilingual scenarios. The Face-Voice Association in Multilingual Environments (FAME) 2026 Challenge, held at ICASSP 2026, focuses on developing methods for face-voice association that are effective when the language at test-time is different than the training one. This report provides a brief summary of the challenge.
RobustA: Robust Anomaly Detection in Multimodal Data
Nov 10, 2025In recent years, multimodal anomaly detection methods have demonstrated remarkable performance improvements over video-only models. However, real-world multimodal data is often corrupted due to unforeseen environmental distortions. In this paper, we present the first-of-its-kind work that comprehensively investigates the adverse effects of corrupted modalities on multimodal anomaly detection task. To streamline this work, we propose RobustA, a carefully curated evaluation dataset to systematically observe the impacts of audio and visual corruptions on the overall effectiveness of anomaly detection systems. Furthermore, we propose a multimodal anomaly detection method, which shows notable resilience against corrupted modalities. The proposed method learns a shared representation space for different modalities and employs a dynamic weighting scheme during inference based on the estimated level of corruption. Our work represents a significant step forward in enabling the real-world application of multimodal anomaly detection, addressing situations where the likely events of modality corruptions occur. The proposed evaluation dataset with corrupted modalities and respective extracted features will be made publicly available.
AI in Agriculture: A Survey of Deep Learning Techniques for Crops, Fisheries and Livestock
Jul 29, 2025



Crops, fisheries and livestock form the backbone of global food production, essential to feed the ever-growing global population. However, these sectors face considerable challenges, including climate variability, resource limitations, and the need for sustainable management. Addressing these issues requires efficient, accurate, and scalable technological solutions, highlighting the importance of artificial intelligence (AI). This survey presents a systematic and thorough review of more than 200 research works covering conventional machine learning approaches, advanced deep learning techniques (e.g., vision transformers), and recent vision-language foundation models (e.g., CLIP) in the agriculture domain, focusing on diverse tasks such as crop disease detection, livestock health management, and aquatic species monitoring. We further cover major implementation challenges such as data variability and experimental aspects: datasets, performance evaluation metrics, and geographical focus. We finish the survey by discussing potential open research directions emphasizing the need for multimodal data integration, efficient edge-device deployment, and domain-adaptable AI models for diverse farming environments. Rapid growth of evolving developments in this field can be actively tracked on our project page: https://github.com/umair1221/AI-in-Agriculture
GenMix: Effective Data Augmentation with Generative Diffusion Model Image Editing
Dec 03, 2024



Data augmentation is widely used to enhance generalization in visual classification tasks. However, traditional methods struggle when source and target domains differ, as in domain adaptation, due to their inability to address domain gaps. This paper introduces GenMix, a generalizable prompt-guided generative data augmentation approach that enhances both in-domain and cross-domain image classification. Our technique leverages image editing to generate augmented images based on custom conditional prompts, designed specifically for each problem type. By blending portions of the input image with its edited generative counterpart and incorporating fractal patterns, our approach mitigates unrealistic images and label ambiguity, improving the performance and adversarial robustness of the resulting models. Efficacy of our method is established with extensive experiments on eight public datasets for general and fine-grained classification, in both in-domain and cross-domain settings. Additionally, we demonstrate performance improvements for self-supervised learning, learning with data scarcity, and adversarial robustness. As compared to the existing state-of-the-art methods, our technique achieves stronger performance across the board.
A Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Aug 30, 2024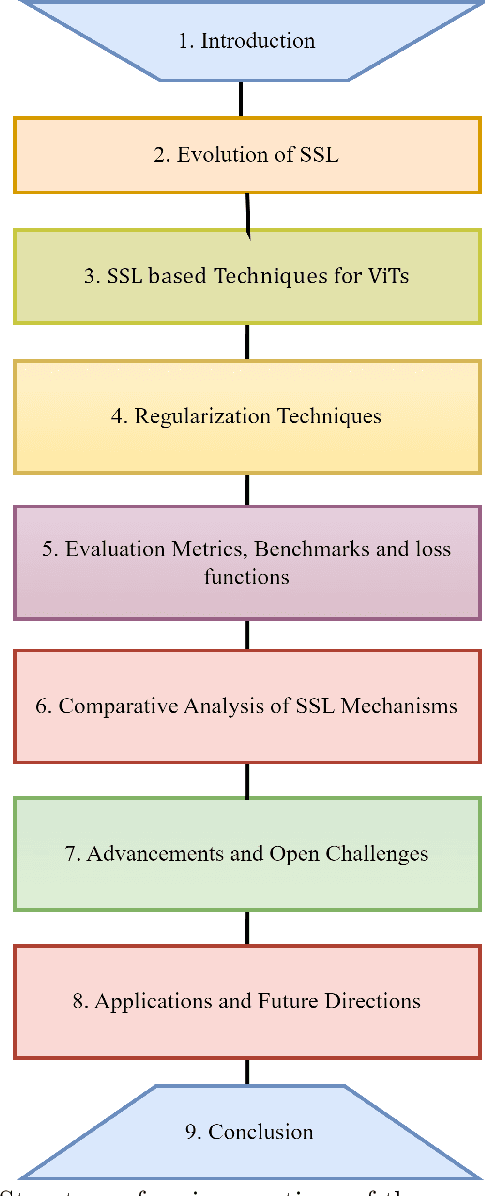
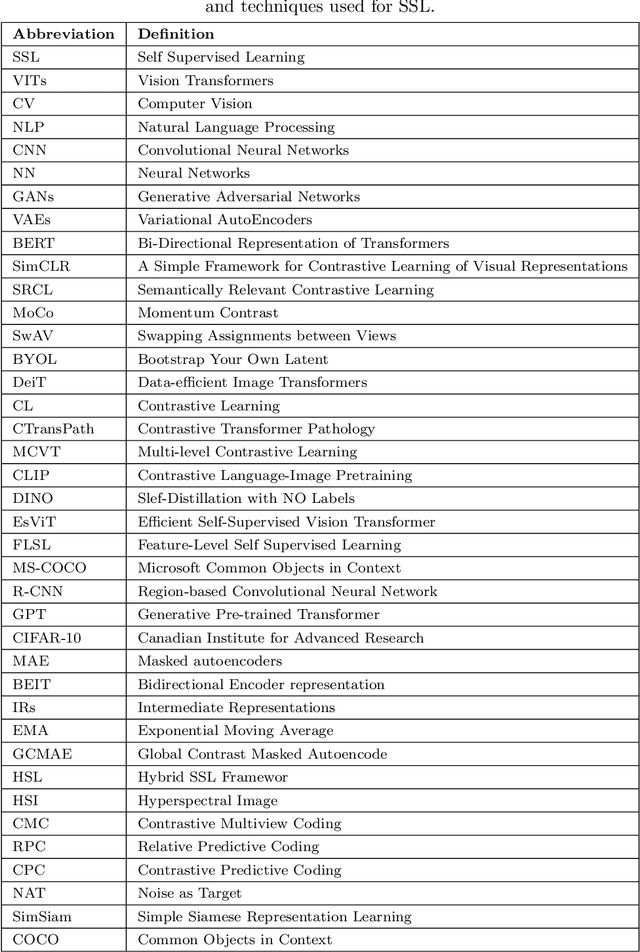
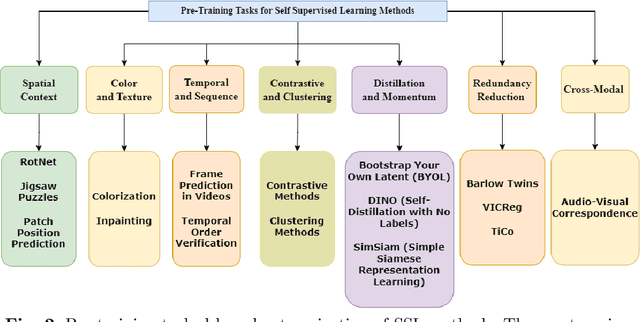
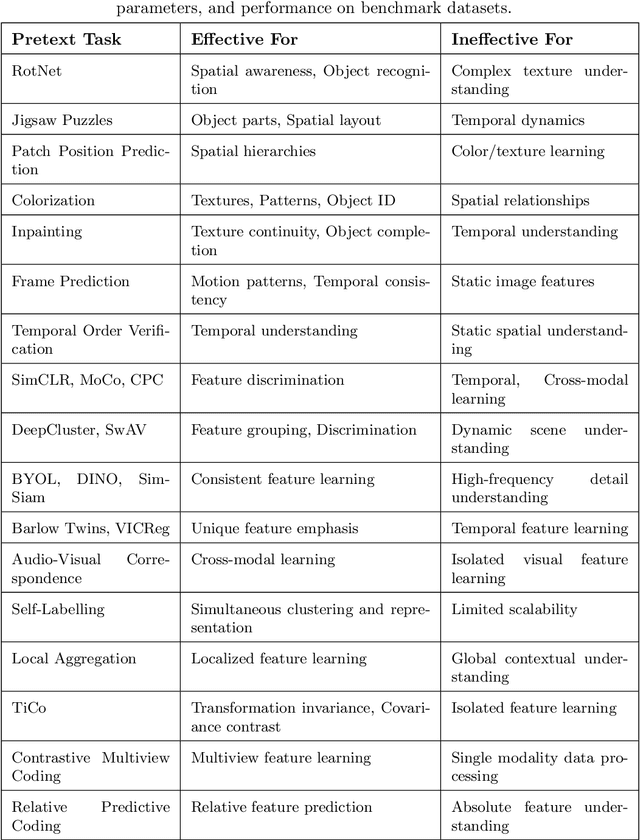
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to improve this vast amount of unlabeled data available. Thus its better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is less label data available. In this survey we thus develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
Modality Invariant Multimodal Learning to Handle Missing Modalities: A Single-Branch Approach
Aug 14, 2024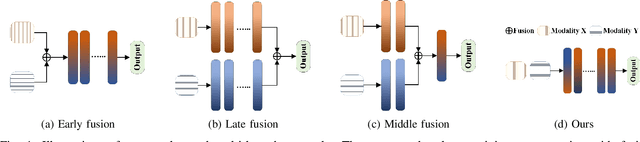
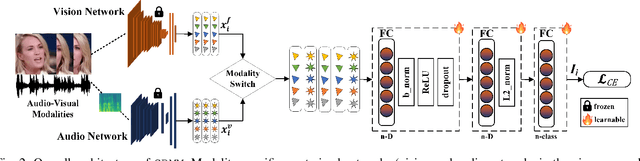


Multimodal networks have demonstrated remarkable performance improvements over their unimodal counterparts. Existing multimodal networks are designed in a multi-branch fashion that, due to the reliance on fusion strategies, exhibit deteriorated performance if one or more modalities are missing. In this work, we propose a modality invariant multimodal learning method, which is less susceptible to the impact of missing modalities. It consists of a single-branch network sharing weights across multiple modalities to learn inter-modality representations to maximize performance as well as robustness to missing modalities. Extensive experiments are performed on four challenging datasets including textual-visual (UPMC Food-101, Hateful Memes, Ferramenta) and audio-visual modalities (VoxCeleb1). Our proposed method achieves superior performance when all modalities are present as well as in the case of missing modalities during training or testing compared to the existing state-of-the-art methods.
Chameleon: Images Are What You Need For Multimodal Learning Robust To Missing Modalities
Jul 23, 2024Multimodal learning has demonstrated remarkable performance improvements over unimodal architectures. However, multimodal learning methods often exhibit deteriorated performances if one or more modalities are missing. This may be attributed to the commonly used multi-branch design containing modality-specific streams making the models reliant on the availability of a complete set of modalities. In this work, we propose a robust textual-visual multimodal learning method, Chameleon, that completely deviates from the conventional multi-branch design. To enable this, we present the unification of input modalities into one format by encoding textual modality into visual representations. As a result, our approach does not require modality-specific branches to learn modality-independent multimodal representations making it robust to missing modalities. Extensive experiments are performed on four popular challenging datasets including Hateful Memes, UPMC Food-101, MM-IMDb, and Ferramenta. Chameleon not only achieves superior performance when all modalities are present at train/test time but also demonstrates notable resilience in the case of missing modalities.
Exploiting Autoencoder's Weakness to Generate Pseudo Anomalies
May 09, 2024Due to the rare occurrence of anomalous events, a typical approach to anomaly detection is to train an autoencoder (AE) with normal data only so that it learns the patterns or representations of the normal training data. At test time, the trained AE is expected to well reconstruct normal but to poorly reconstruct anomalous data. However, contrary to the expectation, anomalous data is often well reconstructed as well. In order to further separate the reconstruction quality between normal and anomalous data, we propose creating pseudo anomalies from learned adaptive noise by exploiting the aforementioned weakness of AE, i.e., reconstructing anomalies too well. The generated noise is added to the normal data to create pseudo anomalies. Extensive experiments on Ped2, Avenue, ShanghaiTech, CIFAR-10, and KDDCUP datasets demonstrate the effectiveness and generic applicability of our approach in improving the discriminative capability of AEs for anomaly detection.
* SharedIt link: https://rdcu.be/dGOrh