 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Aug 30, 2024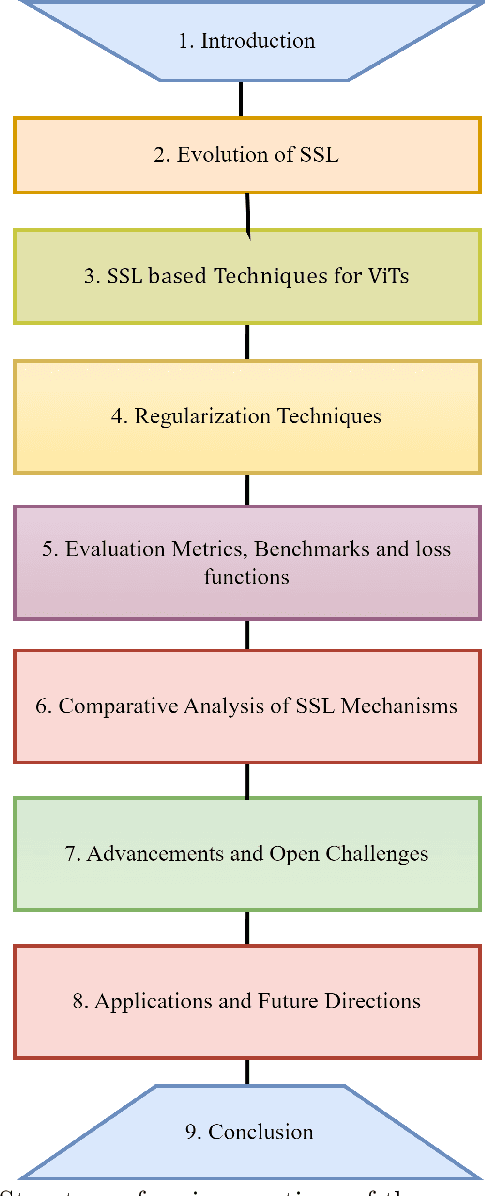
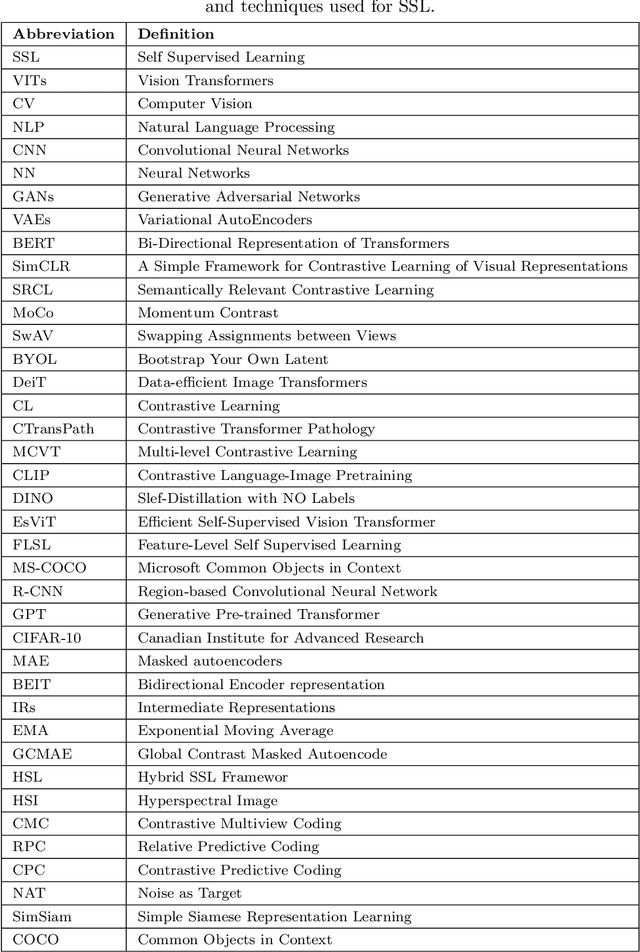
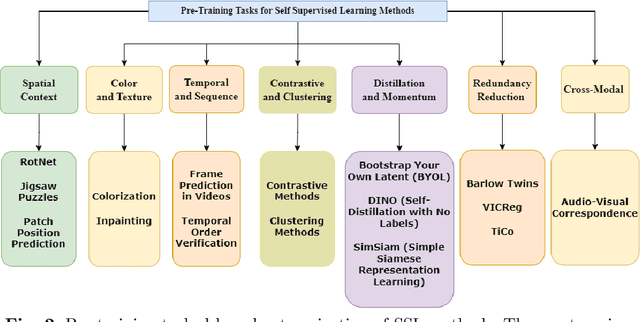
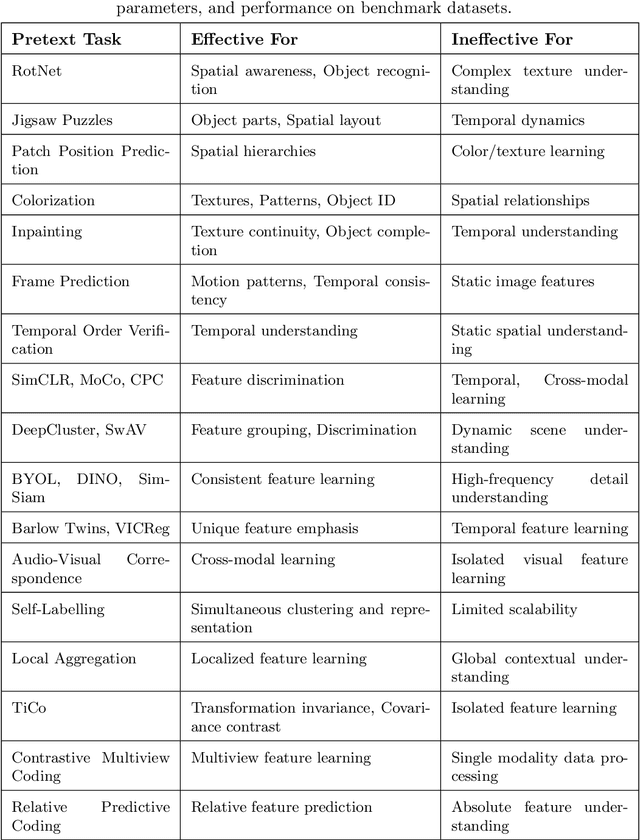
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to improve this vast amount of unlabeled data available. Thus its better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is less label data available. In this survey we thus develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
A Multimodal Memes Classification: A Survey and Open Research Issues
Sep 17, 2020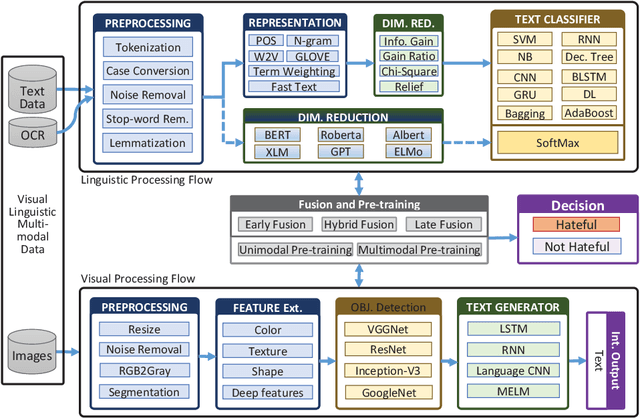
Memes are graphics and text overlapped so that together they present concepts that become dubious if one of them is absent. It is spread mostly on social media platforms, in the form of jokes, sarcasm, motivating, etc. After the success of BERT in Natural Language Processing (NLP), researchers inclined to Visual-Linguistic (VL) multimodal problems like memes classification, image captioning, Visual Question Answering (VQA), and many more. Unfortunately, many memes get uploaded each day on social media platforms that need automatic censoring to curb misinformation and hate. Recently, this issue has attracted the attention of researchers and practitioners. State-of-the-art methods that performed significantly on other VL dataset, tends to fail on memes classification. In this context, this work aims to conduct a comprehensive study on memes classification, generally on the VL multimodal problems and cutting edge solutions. We propose a generalized framework for VL problems. We cover the early and next-generation works on VL problems. Finally, we identify and articulate several open research issues and challenges. This is the first study that presents the generalized view of the advanced classification techniques concerning memes classification to the best of our knowledge. We believe this study presents a clear road-map for the Machine Learning (ML) research community to implement and enhance memes classification techniques.