 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Multi-Agent Ransomware Analysis Using AutoGen
Jan 28, 2026Ransomware has become one of the most serious cybersecurity threats causing major financial losses and operational disruptions worldwide.Traditional detection methods such as static analysis, heuristic scanning and behavioral analysis often fall short when used alone. To address these limitations, this paper presents multimodal multi agent ransomware analysis framework designed for ransomware classification. Proposed multimodal multiagent architecture combines information from static, dynamic and network sources. Each data type is handled by specialized agent that uses auto encoder based feature extraction. These representations are then integrated through a fusion agent. After that fused representation are used by transformer based classifier. It identifies the specific ransomware family. The agents interact through an interagent feedback mechanism that iteratively refines feature representations by suppressing low confidence information. The framework was evaluated on large scale datasets containing thousands of ransomware and benign samples. Multiple experiments were conducted on ransomware dataset. It outperforms single modality and nonadaptive fusion baseline achieving improvement of up to 0.936 in Macro-F1 for family classification and reducing calibration error. Over 100 epochs, the agentic feedback loop displays a stable monotonic convergence leading to over +0.75 absolute improvement in terms of agent quality and a final composite score of around 0.88 without fine tuning of the language models. Zeroday ransomware detection remains family dependent on polymorphism and modality disruptions. Confidence aware abstention enables reliable real world deployment by favoring conservativeand trustworthy decisions over forced classification. The findings indicate that proposed approach provides a practical andeffective path toward improving real world ransomware defense systems.
Automated MRI Tumor Segmentation using hybrid U-Net with Transformer and Efficient Attention
Jun 18, 2025Cancer is an abnormal growth with potential to invade locally and metastasize to distant organs. Accurate auto-segmentation of the tumor and surrounding normal tissues is required for radiotherapy treatment plan optimization. Recent AI-based segmentation models are generally trained on large public datasets, which lack the heterogeneity of local patient populations. While these studies advance AI-based medical image segmentation, research on local datasets is necessary to develop and integrate AI tumor segmentation models directly into hospital software for efficient and accurate oncology treatment planning and execution. This study enhances tumor segmentation using computationally efficient hybrid UNet-Transformer models on magnetic resonance imaging (MRI) datasets acquired from a local hospital under strict privacy protection. We developed a robust data pipeline for seamless DICOM extraction and preprocessing, followed by extensive image augmentation to ensure model generalization across diverse clinical settings, resulting in a total dataset of 6080 images for training. Our novel architecture integrates UNet-based convolutional neural networks with a transformer bottleneck and complementary attention modules, including efficient attention, Squeeze-and-Excitation (SE) blocks, Convolutional Block Attention Module (CBAM), and ResNeXt blocks. To accelerate convergence and reduce computational demands, we used a maximum batch size of 8 and initialized the encoder with pretrained ImageNet weights, training the model on dual NVIDIA T4 GPUs via checkpointing to overcome Kaggle's runtime limits. Quantitative evaluation on the local MRI dataset yielded a Dice similarity coefficient of 0.764 and an Intersection over Union (IoU) of 0.736, demonstrating competitive performance despite limited data and underscoring the importance of site-specific model development for clinical deployment.
Crime Hotspot Prediction Using Deep Graph Convolutional Networks
Jun 16, 2025
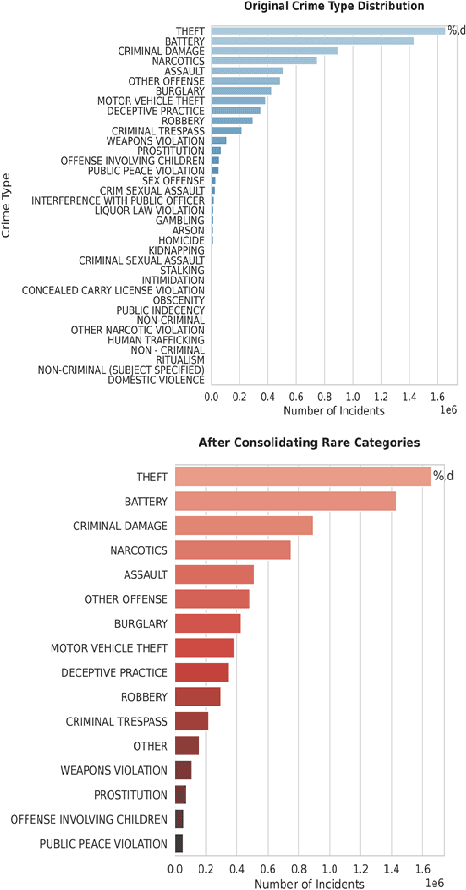

Crime hotspot prediction is critical for ensuring urban safety and effective law enforcement, yet it remains challenging due to the complex spatial dependencies inherent in criminal activity. The previous approaches tended to use classical algorithms such as the KDE and SVM to model data distributions and decision boundaries. The methods often fail to capture these spatial relationships, treating crime events as independent and ignoring geographical interactions. To address this, we propose a novel framework based on Graph Convolutional Networks (GCNs), which explicitly model spatial dependencies by representing crime data as a graph. In this graph, nodes represent discrete geographic grid cells and edges capture proximity relationships. Using the Chicago Crime Dataset, we engineer spatial features and train a multi-layer GCN model to classify crime types and predict high-risk zones. Our approach achieves 88% classification accuracy, significantly outperforming traditional methods. Additionally, the model generates interpretable heat maps of crime hotspots, demonstrating the practical utility of graph-based learning for predictive policing and spatial criminology.
AutoGen Driven Multi Agent Framework for Iterative Crime Data Analysis and Prediction
Jun 13, 2025This paper introduces LUCID-MA (Learning and Understanding Crime through Dialogue of Multiple Agents), an innovative AI powered framework where multiple AI agents collaboratively analyze and understand crime data. Our system that consists of three core components: an analysis assistant that highlights spatiotemporal crime patterns, a feedback component that reviews and refines analytical results and a prediction component that forecasts future crime trends. With a well-designed prompt and the LLaMA-2-13B-Chat-GPTQ model, it runs completely offline and allows the agents undergo self-improvement through 100 rounds of communication with less human interaction. A scoring function is incorporated to evaluate agent's performance, providing visual plots to track learning progress. This work demonstrates the potential of AutoGen-style agents for autonomous, scalable, and iterative analysis in social science domains maintaining data privacy through offline execution.
A Survey on Self-supervised Contrastive Learning for Multimodal Text-Image Analysis
Mar 14, 2025Self-supervised learning is a machine learning approach that generates implicit labels by learning underlined patterns and extracting discriminative features from unlabeled data without manual labelling. Contrastive learning introduces the concept of "positive" and "negative" samples, where positive pairs (e.g., variation of the same image/object) are brought together in the embedding space, and negative pairs (e.g., views from different images/objects) are pushed farther away. This methodology has shown significant improvements in image understanding and image text analysis without much reliance on labeled data. In this paper, we comprehensively discuss the terminologies, recent developments and applications of contrastive learning with respect to text-image models. Specifically, we provide an overview of the approaches of contrastive learning in text-image models in recent years. Secondly, we categorize the approaches based on different model structures. Thirdly, we further introduce and discuss the latest advances of the techniques used in the process such as pretext tasks for both images and text, architectural structures, and key trends. Lastly, we discuss the recent state-of-art applications of self-supervised contrastive learning Text-Image based models.
A Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Aug 30, 2024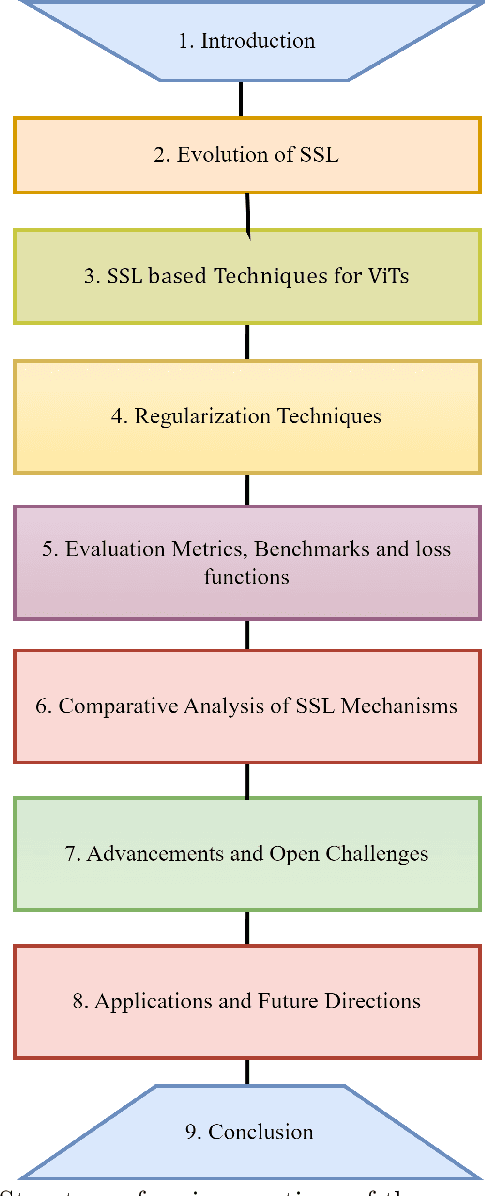
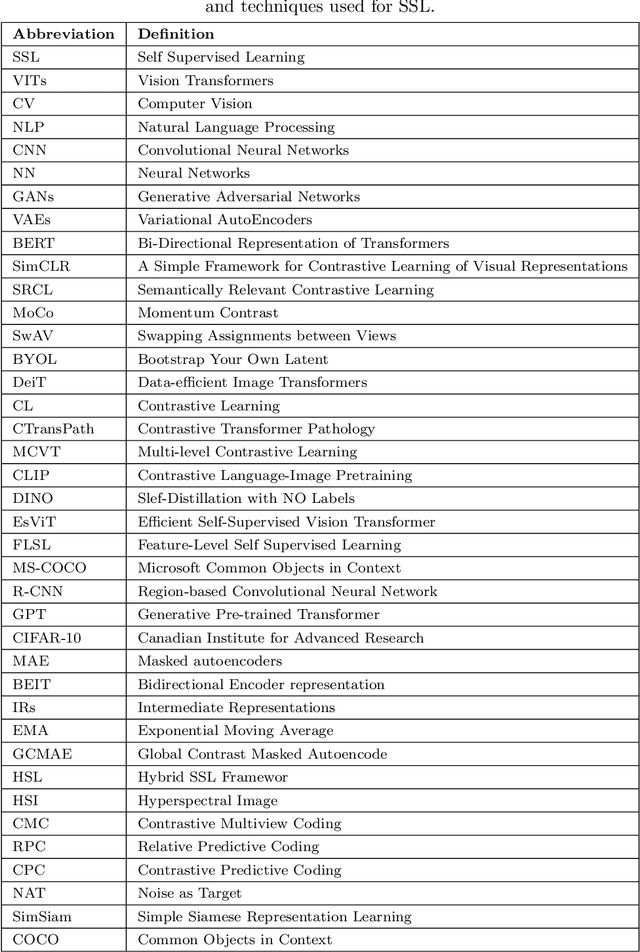
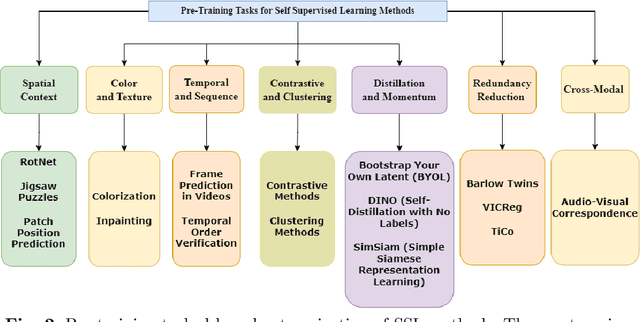
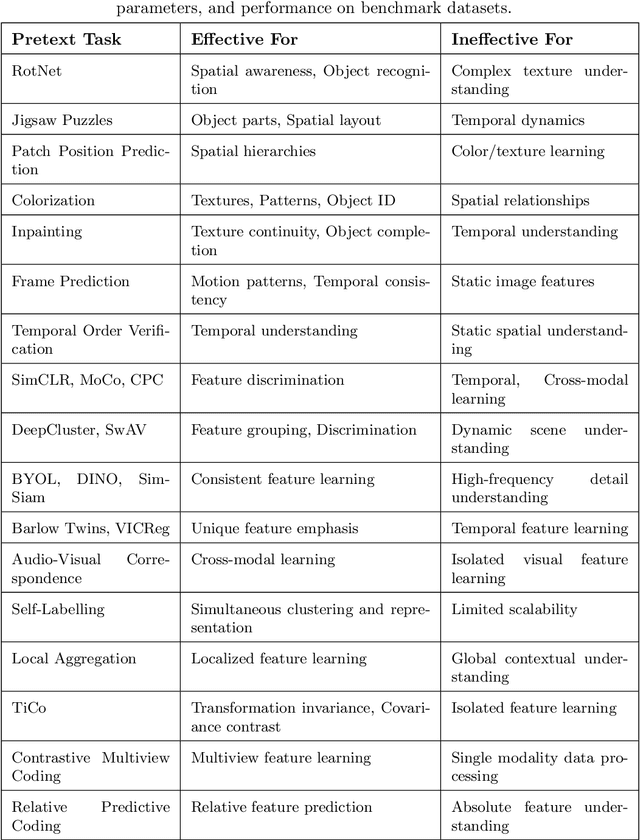
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to improve this vast amount of unlabeled data available. Thus its better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is less label data available. In this survey we thus develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
Channel Boosted CNN-Transformer-based Multi-Level and Multi-Scale Nuclei Segmentation
Jul 27, 2024



Accurate nuclei segmentation is an essential foundation for various applications in computational pathology, including cancer diagnosis and treatment planning. Even slight variations in nuclei representations can significantly impact these downstream tasks. However, achieving accurate segmentation remains challenging due to factors like clustered nuclei, high intra-class variability in size and shape, resemblance to other cells, and color or contrast variations between nuclei and background. Despite the extensive utilization of Convolutional Neural Networks (CNNs) in medical image segmentation, they may have trouble capturing long-range dependencies crucial for accurate nuclei delineation. Transformers address this limitation but might miss essential low-level features. To overcome these limitations, we utilized CNN-Transformer-based techniques for nuclei segmentation in H&E stained histology images. In this work, we proposed two CNN-Transformer architectures, Nuclei Hybrid Vision Transformer (NucleiHVT) and Channel Boosted Nuclei Hybrid Vision Transformer (CB-NucleiHVT), that leverage the strengths of both CNNs and Transformers to effectively learn nuclei boundaries in multi-organ histology images. The first architecture, NucleiHVT is inspired by the UNet architecture and incorporates the dual attention mechanism to capture both multi-level and multi-scale context effectively. The CB-NucleiHVT network, on the other hand, utilizes the concept of channel boosting to learn diverse feature spaces, enhancing the model's ability to distinguish subtle variations in nuclei characteristics. Detailed evaluation of two medical image segmentation datasets shows that the proposed architectures outperform existing CNN-based, Transformer-based, and hybrid methods. The proposed networks demonstrated effective results both in terms of quantitative metrics, and qualitative visual assessment.
Particle Multi-Axis Transformer for Jet Tagging
Jun 09, 2024



Jet tagging is an essential categorization problem in high energy physics. In recent times, Deep Learning has not only risen to the challenge of jet tagging but also significantly improved its performance. In this article, we propose an idea of a new architecture, Particle Multi-Axis transformer (ParMAT) which is a modified version of Particle transformer (ParT). ParMAT contains local and global spatial interactions within a single unit which improves its ability to handle various input lengths. We trained our model on JETCLASS, a publicly available large dataset that contains 100M jets of 10 different classes of particles. By integrating a parallel attention mechanism and pairwise interactions of particles in the attention mechanism,ParMAT achieves robustness and higher accuracy over the ParT and ParticleNet. The scalability of the model to huge datasets and its ability to automatically extract essential features demonstrate its potential for enhancing jet tagging.
A Recent Survey of Vision Transformers for Medical Image Segmentation
Dec 01, 2023
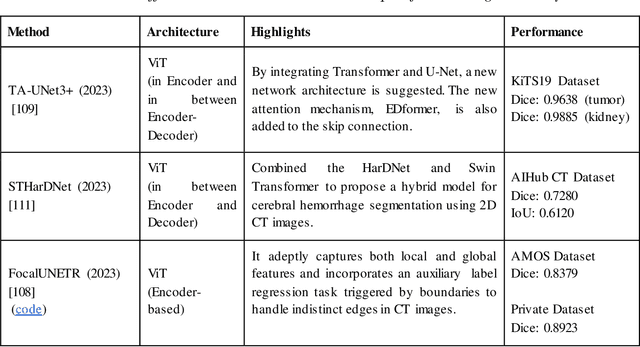

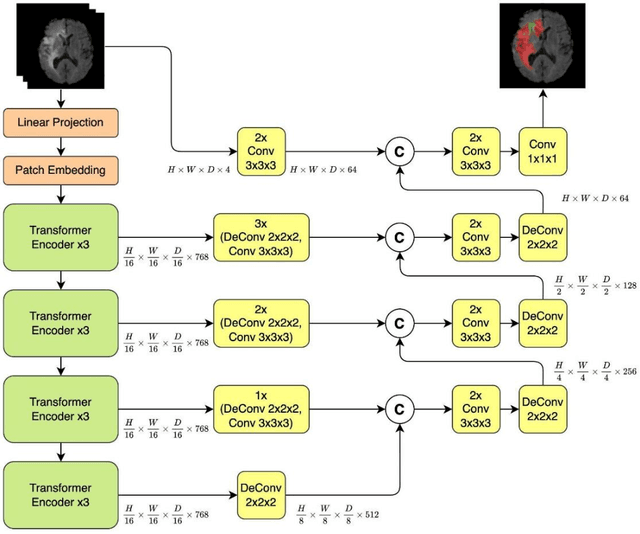
Medical image segmentation plays a crucial role in various healthcare applications, enabling accurate diagnosis, treatment planning, and disease monitoring. In recent years, Vision Transformers (ViTs) have emerged as a promising technique for addressing the challenges in medical image segmentation. In medical images, structures are usually highly interconnected and globally distributed. ViTs utilize their multi-scale attention mechanism to model the long-range relationships in the images. However, they do lack image-related inductive bias and translational invariance, potentially impacting their performance. Recently, researchers have come up with various ViT-based approaches that incorporate CNNs in their architectures, known as Hybrid Vision Transformers (HVTs) to capture local correlation in addition to the global information in the images. This survey paper provides a detailed review of the recent advancements in ViTs and HVTs for medical image segmentation. Along with the categorization of ViT and HVT-based medical image segmentation approaches we also present a detailed overview of their real-time applications in several medical image modalities. This survey may serve as a valuable resource for researchers, healthcare practitioners, and students in understanding the state-of-the-art approaches for ViT-based medical image segmentation.
MaxViT-UNet: Multi-Axis Attention for Medical Image Segmentation
May 25, 2023



Convolutional neural networks have made significant strides in medical image analysis in recent years. However, the local nature of the convolution operator inhibits the CNNs from capturing global and long-range interactions. Recently, Transformers have gained popularity in the computer vision community and also medical image segmentation. But scalability issues of self-attention mechanism and lack of the CNN like inductive bias have limited their adoption. In this work, we present MaxViT-UNet, an Encoder-Decoder based hybrid vision transformer for medical image segmentation. The proposed hybrid decoder, also based on MaxViT-block, is designed to harness the power of convolution and self-attention mechanism at each decoding stage with minimal computational burden. The multi-axis self-attention in each decoder stage helps in differentiating between the object and background regions much more efficiently. The hybrid decoder block initially fuses the lower level features upsampled via transpose convolution, with skip-connection features coming from hybrid encoder, then fused features are refined using multi-axis attention mechanism. The proposed decoder block is repeated multiple times to accurately segment the nuclei regions. Experimental results on MoNuSeg dataset proves the effectiveness of the proposed technique. Our MaxViT-UNet outperformed the previous CNN only (UNet) and Transformer only (Swin-UNet) techniques by a large margin of 2.36% and 5.31% on Dice metric respectively.