 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tumor Aware DenseNet Swin Hybrid Learning with Boosted and Hierarchical Feature Spaces for Large-Scale Brain MRI Classification
Jan 26, 2026This study proposes an efficient Densely Swin Hybrid (EDSH) framework for brain tumor MRI analysis, designed to jointly capture fine grained texture patterns and long range contextual dependencies. Two tumor aware experimental setups are introduced to address class-specific diagnostic challenges. The first setup employs a Boosted Feature Space (BFS), where independently customized DenseNet and Swint branches learn complementary local and global representations that are dimension aligned, fused, and boosted, enabling highly sensitive detection of diffuse glioma patterns by successfully learning the features of irregular shape, poorly defined mass, and heterogeneous texture. The second setup adopts a hierarchical DenseNet Swint architecture with Deep Feature Extraction have Dual Residual connections (DFE and DR), in which DenseNet serves as a stem CNN for structured local feature learning, while Swin_t models global tumor morphology, effectively suppressing false negatives in meningioma and pituitary tumor classification by learning the features of well defined mass, location (outside brain) and enlargments in tumors (dural tail or upward extension). DenseNet is customized at the input level to match MRI spatial characteristics, leveraging dense residual connectivity to preserve texture information and mitigate vanishing-gradient effects. In parallel, Swint is tailored through task aligned patch embedding and shifted-window self attention to efficiently capture hierarchical global dependencies. Extensive evaluation on a large-scale MRI dataset (stringent 40,260 images across four tumor classes) demonstrates consistent superiority over standalone CNNs, Vision Transformers, and hybrids, achieving 98.50 accuracy and recall on the test unseen dataset.
RSwinV2-MD: An Enhanced Residual SwinV2 Transformer for Monkeypox Detection from Skin Images
Jan 06, 2026In this paper, a deep learning approach for Mpox diagnosis named Customized Residual SwinTransformerV2 (RSwinV2) has been proposed, trying to enhance the capability of lesion classification by employing the RSwinV2 tool-assisted vision approach. In the RSwinV2 method, a hierarchical structure of the transformer has been customized based on the input dimensionality, embedding structure, and output targeted by the method. In this RSwinV2 approach, the input image has been split into non-overlapping patches and processed using shifted windows and attention in these patches. This process has helped the method link all the windows efficiently by avoiding the locality issues of non-overlapping regions in attention, while being computationally efficient. RSwinV2 has further developed based on SwinTransformer and has included patch and position embeddings to take advantage of the transformer global-linking capability by employing multi-head attention in these embeddings. Furthermore, RSwinV2 has developed and incorporated the Inverse Residual Block (IRB) into this method, which utilizes convolutional skip connections with these inclusive designs to address the vanishing gradient issues during processing. RSwinV2 inclusion of IRB has therefore facilitated this method to link global patterns as well as local patterns; hence, its integrity has helped improve lesion classification capability by minimizing variability of Mpox and increasing differences of Mpox, chickenpox, measles, and cowpox. In testing SwinV2, its accuracy of 96.51 and an F1score of 96.13 have been achieved on the Kaggle public dataset, which has outperformed standard CNN models and SwinTransformers; the RSwinV2 vector has thus proved its validity as a computer-assisted tool for Mpox lesion observation interpretation.
MambaFormer: Token-Level Guided Routing Mixture-of-Experts for Accurate and Efficient Clinical Assistance
Jan 03, 2026The deployment of large language models (LLMs) in real-world clinical applications is constrained by the fundamental trade-off between computational cost and the efficiency of linear-time models. To address this, we propose an LLM-based MambaFormer hybrid Mixture-of-Experts (MoE) framework for efficient medical question-answering (QA) and clinical assistance. The MambaFormer employs a lightweight gating mechanism that performs token-level dynamic routing to a customized Transformer expert (ET5) for short, complex queries or to a State Space Model expert (EMamba) for long, high-throughput sequences. The customized EMamba and ET5 models are tailored to accommodate input sequence dimensionality, embedding structure, sequence length, and target-specific output heads, and are fine-tuned through transfer learning on a new, custom-designed DentalQA dataset. Moreover, intelligent routing decisions are driven by the contextual complexity of token embeddings, normalized sequence length, and domain-aware features, thereby enforcing a Pareto-optimal trade-off between inference latency and prediction accuracy. Furthermore, a novel utility-guided multi-objective loss jointly optimizes decisions, router parameters, routing behavior, expert utilization, and computational cost by adaptively regulating token-level expert activation. Finally, the proposed MambaFormer is cross-validated (holdout) for medical QA on the new, custom-designed DentalQA and PubMedQA datasets and compared with state-of-the-art techniques. The proposed MambaFormer outperforms (BERTScore = 0.9180) with ultra-low latency (0.077 s), delivering a 24.4 speedup over T5-Large and establishing a scalable solution for resource-constrained clinical deployment.
Residual-SwinCA-Net: A Channel-Aware Integrated Residual CNN-Swin Transformer for Malignant Lesion Segmentation in BUSI
Dec 09, 2025A novel deep hybrid Residual-SwinCA-Net segmentation framework is proposed in the study for addressing such challenges by extracting locally correlated and robust features, incorporating residual CNN modules. Furthermore, for learning global dependencies, Swin Transformer blocks are customized using internal residual pathways, which reinforce gradient stability, refine local patterns, and facilitate global feature fusion. Formerly, for enhancing tissue continuity, ultrasound noise suppressions, and accentuating fine structural transitions Laplacian-of-Gaussian regional operator is applied, and for maintaining the morphological integrity of malignant lesion contours, a boundary-oriented operator has been incorporated. Subsequently, a contraction strategy was applied stage-wise by progressively reducing features-map progressively for capturing scale invariance and enhancing the robustness of structural variability. In addition, each decoder level prior augmentation integrates a new Multi-Scale Channel Attention and Squeezing (MSCAS) module. The MSCAS selectively emphasizes encoder salient maps, retains discriminative global context, and complementary local structures with minimal computational cost while suppressing redundant activations. Finally, the Pixel-Attention module encodes class-relevant spatial cues by adaptively weighing malignant lesion pixels while suppressing background interference. The Residual-SwinCA-Net and existing CNNs/ViTs techniques have been implemented on the publicly available BUSI dataset. The proposed Residual-SwinCA-Net framework outperformed and achieved 99.29% mean accuracy, 98.74% IoU, and 0.9041 Dice for breast lesion segmentation. The proposed Residual-SwinCA-Net framework improves the BUSI lesion diagnostic performance and strengthens timely clinical decision-making.
RS-CA-HSICT: A Residual and Spatial Channel Augmented CNN Transformer Framework for Monkeypox Detection
Nov 19, 2025This work proposes a hybrid deep learning approach, namely Residual and Spatial Learning based Channel Augmented Integrated CNN-Transformer architecture, that leverages the strengths of CNN and Transformer towards enhanced MPox detection. The proposed RS-CA-HSICT framework is composed of an HSICT block, a residual CNN module, a spatial CNN block, and a CA, which enhances the diverse feature space, detailed lesion information, and long-range dependencies. The new HSICT module first integrates an abstract representation of the stem CNN and customized ICT blocks for efficient multihead attention and structured CNN layers with homogeneous (H) and structural (S) operations. The customized ICT blocks learn global contextual interactions and local texture extraction. Additionally, H and S layers learn spatial homogeneity and fine structural details by reducing noise and modeling complex morphological variations. Moreover, inverse residual learning enhances vanishing gradient, and stage-wise resolution reduction ensures scale invariance. Furthermore, the RS-CA-HSICT framework augments the learned HSICT channels with the TL-driven Residual and Spatial CNN maps for enhanced multiscale feature space capturing global and localized structural cues, subtle texture, and contrast variations. These channels, preceding augmentation, are refined through the Channel-Fusion-and-Attention block, which preserves discriminative channels while suppressing redundant ones, thereby enabling efficient computation. Finally, the spatial attention mechanism refines pixel selection to detect subtle patterns and intra-class contrast variations in Mpox. Experimental results on both the Kaggle benchmark and a diverse MPox dataset reported classification accuracy as high as 98.30% and an F1-score of 98.13%, which outperforms the existing CNNs and ViTs.
A Novel Deep Hybrid Framework with Ensemble-Based Feature Optimization for Robust Real-Time Human Activity Recognition
Aug 26, 2025



Human Activity Recognition (HAR) plays a pivotal role in various applications, including smart surveillance, healthcare, assistive technologies, sports analytics, etc. However, HAR systems still face critical challenges, including high computational costs, redundant features, and limited scalability in real-time scenarios. An optimized hybrid deep learning framework is introduced that integrates a customized InceptionV3, an LSTM architecture, and a novel ensemble-based feature selection strategy. The proposed framework first extracts spatial descriptors using the customized InceptionV3 model, which captures multilevel contextual patterns, region homogeneity, and fine-grained localization cues. The temporal dependencies across frames are then modeled using LSTMs to effectively encode motion dynamics. Finally, an ensemble-based genetic algorithm with Adaptive Dynamic Fitness Sharing and Attention (ADFSA) is employed to select a compact and optimized feature set by dynamically balancing objectives such as accuracy, redundancy, uniqueness, and complexity reduction. Consequently, the selected feature subsets, which are both diverse and discriminative, enable various lightweight machine learning classifiers to achieve accurate and robust HAR in heterogeneous environments. Experimental results on the robust UCF-YouTube dataset, which presents challenges such as occlusion, cluttered backgrounds, motion dynamics, and poor illumination, demonstrate good performance. The proposed approach achieves 99.65% recognition accuracy, reduces features to as few as 7, and enhances inference time. The lightweight and scalable nature of the HAR system supports real-time deployment on edge devices such as Raspberry Pi, enabling practical applications in intelligent, resource-aware environments, including public safety, assistive technology, and autonomous monitoring systems.
CE-RS-SBCIT A Novel Channel Enhanced Hybrid CNN Transformer with Residual, Spatial, and Boundary-Aware Learning for Brain Tumor MRI Analysis
Aug 23, 2025Brain tumors remain among the most lethal human diseases, where early detection and accurate classification are critical for effective diagnosis and treatment planning. Although deep learning-based computer-aided diagnostic (CADx) systems have shown remarkable progress. However, conventional convolutional neural networks (CNNs) and Transformers face persistent challenges, including high computational cost, sensitivity to minor contrast variations, structural heterogeneity, and texture inconsistencies in MRI data. Therefore, a novel hybrid framework, CE-RS-SBCIT, is introduced, integrating residual and spatial learning-based CNNs with transformer-driven modules. The proposed framework exploits local fine-grained and global contextual cues through four core innovations: (i) a smoothing and boundary-based CNN-integrated Transformer (SBCIT), (ii) tailored residual and spatial learning CNNs, (iii) a channel enhancement (CE) strategy, and (iv) a novel spatial attention mechanism. The developed SBCIT employs stem convolution and contextual interaction transformer blocks with systematic smoothing and boundary operations, enabling efficient global feature modeling. Moreover, Residual and spatial CNNs, enhanced by auxiliary transfer-learned feature maps, enrich the representation space, while the CE module amplifies discriminative channels and mitigates redundancy. Furthermore, the spatial attention mechanism selectively emphasizes subtle contrast and textural variations across tumor classes. Extensive evaluation on challenging MRI datasets from Kaggle and Figshare, encompassing glioma, meningioma, pituitary tumors, and healthy controls, demonstrates superior performance, achieving 98.30% accuracy, 98.08% sensitivity, 98.25% F1-score, and 98.43% precision.
Advanced Hybrid Transformer LSTM Technique with Attention and TS Mixer for Drilling Rate of Penetration Prediction
Aug 07, 2025The Rate of Penetration (ROP) is crucial for optimizing drilling operations; however, accurately predicting it is hindered by the complex, dynamic, and high-dimensional nature of drilling data. Traditional empirical, physics-based, and basic machine learning models often fail to capture intricate temporal and contextual relationships, resulting in suboptimal predictions and limited real-time utility. To address this gap, we propose a novel hybrid deep learning architecture integrating Long Short-Term Memory (LSTM) networks, Transformer encoders, Time-Series Mixer (TS-Mixer) blocks, and attention mechanisms to synergistically model temporal dependencies, static feature interactions, global context, and dynamic feature importance. Evaluated on a real-world drilling dataset, our model outperformed benchmarks (standalone LSTM, TS-Mixer, and simpler hybrids) with an R-squared score of 0.9988 and a Mean Absolute Percentage Error of 1.447%, as measured by standard regression metrics (R-squared, MAE, RMSE, MAPE). Model interpretability was ensured using SHAP and LIME, while actual vs. predicted curves and bias checks confirmed accuracy and fairness across scenarios. This advanced hybrid approach enables reliable real-time ROP prediction, paving the way for intelligent, cost-effective drilling optimization systems with significant operational impact.
A Comprehensive Survey on Architectural Advances in Deep CNNs: Challenges, Applications, and Emerging Research Directions
Mar 19, 2025


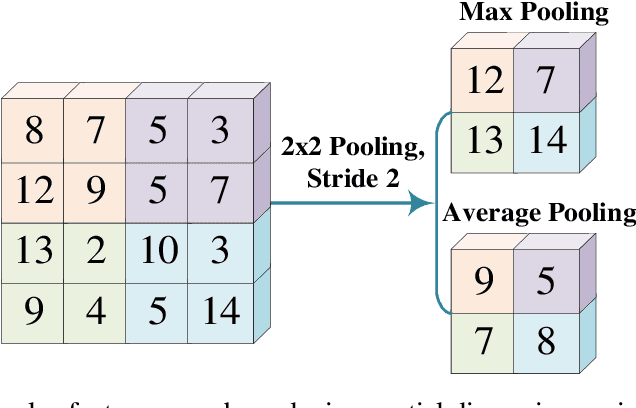
Deep Convolutional Neural Networks (CNNs) have significantly advanced deep learning, driving breakthroughs in computer vision, natural language processing, medical diagnosis, object detection, and speech recognition. Architectural innovations including 1D, 2D, and 3D convolutional models, dilated and grouped convolutions, depthwise separable convolutions, and attention mechanisms address domain-specific challenges and enhance feature representation and computational efficiency. Structural refinements such as spatial-channel exploitation, multi-path design, and feature-map enhancement contribute to robust hierarchical feature extraction and improved generalization, particularly through transfer learning. Efficient preprocessing strategies, including Fourier transforms, structured transforms, low-precision computation, and weight compression, optimize inference speed and facilitate deployment in resource-constrained environments. This survey presents a unified taxonomy that classifies CNN architectures based on spatial exploitation, multi-path structures, depth, width, dimensionality expansion, channel boosting, and attention mechanisms. It systematically reviews CNN applications in face recognition, pose estimation, action recognition, text classification, statistical language modeling, disease diagnosis, radiological analysis, cryptocurrency sentiment prediction, 1D data processing, video analysis, and speech recognition. In addition to consolidating architectural advancements, the review highlights emerging learning paradigms such as few-shot, zero-shot, weakly supervised, federated learning frameworks and future research directions include hybrid CNN-transformer models, vision-language integration, generative learning, etc. This review provides a comprehensive perspective on CNN's evolution from 2015 to 2025, outlining key innovations, challenges, and opportunities.
A Novel Channel Boosted Residual CNN-Transformer with Regional-Boundary Learning for Breast Cancer Detection
Mar 19, 2025Recent advancements in detecting tumors using deep learning on breast ultrasound images (BUSI) have demonstrated significant success. Deep CNNs and vision-transformers (ViTs) have demonstrated individually promising initial performance. However, challenges related to model complexity and contrast, texture, and tumor morphology variations introduce uncertainties that hinder the effectiveness of current methods. This study introduces a novel hybrid framework, CB-Res-RBCMT, combining customized residual CNNs and new ViT components for detailed BUSI cancer analysis. The proposed RBCMT uses stem convolution blocks with CNN Meet Transformer (CMT) blocks, followed by new Regional and boundary (RB) feature extraction operations for capturing contrast and morphological variations. Moreover, the CMT block incorporates global contextual interactions through multi-head attention, enhancing computational efficiency with a lightweight design. Additionally, the customized inverse residual and stem CNNs within the CMT effectively extract local texture information and handle vanishing gradients. Finally, the new channel-boosted (CB) strategy enriches the feature diversity of the limited dataset by combining the original RBCMT channels with transfer learning-based residual CNN-generated maps. These diverse channels are processed through a spatial attention block for optimal pixel selection, reducing redundancy and improving the discrimination of minor contrast and texture variations. The proposed CB-Res-RBCMT achieves an F1-score of 95.57%, accuracy of 95.63%, sensitivity of 96.42%, and precision of 94.79% on the standard harmonized stringent BUSI dataset, outperforming existing ViT and CNN methods. These results demonstrate the versatility of our integrated CNN-Transformer framework in capturing diverse features and delivering superior performance in BUSI cancer diagnosis.