 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Boosted CNN-Transformer-based Multi-Level and Multi-Scale Nuclei Segmentation
Jul 27, 2024



Accurate nuclei segmentation is an essential foundation for various applications in computational pathology, including cancer diagnosis and treatment planning. Even slight variations in nuclei representations can significantly impact these downstream tasks. However, achieving accurate segmentation remains challenging due to factors like clustered nuclei, high intra-class variability in size and shape, resemblance to other cells, and color or contrast variations between nuclei and background. Despite the extensive utilization of Convolutional Neural Networks (CNNs) in medical image segmentation, they may have trouble capturing long-range dependencies crucial for accurate nuclei delineation. Transformers address this limitation but might miss essential low-level features. To overcome these limitations, we utilized CNN-Transformer-based techniques for nuclei segmentation in H&E stained histology images. In this work, we proposed two CNN-Transformer architectures, Nuclei Hybrid Vision Transformer (NucleiHVT) and Channel Boosted Nuclei Hybrid Vision Transformer (CB-NucleiHVT), that leverage the strengths of both CNNs and Transformers to effectively learn nuclei boundaries in multi-organ histology images. The first architecture, NucleiHVT is inspired by the UNet architecture and incorporates the dual attention mechanism to capture both multi-level and multi-scale context effectively. The CB-NucleiHVT network, on the other hand, utilizes the concept of channel boosting to learn diverse feature spaces, enhancing the model's ability to distinguish subtle variations in nuclei characteristics. Detailed evaluation of two medical image segmentation datasets shows that the proposed architectures outperform existing CNN-based, Transformer-based, and hybrid methods. The proposed networks demonstrated effective results both in terms of quantitative metrics, and qualitative visual assessment.
Particle Multi-Axis Transformer for Jet Tagging
Jun 09, 2024



Jet tagging is an essential categorization problem in high energy physics. In recent times, Deep Learning has not only risen to the challenge of jet tagging but also significantly improved its performance. In this article, we propose an idea of a new architecture, Particle Multi-Axis transformer (ParMAT) which is a modified version of Particle transformer (ParT). ParMAT contains local and global spatial interactions within a single unit which improves its ability to handle various input lengths. We trained our model on JETCLASS, a publicly available large dataset that contains 100M jets of 10 different classes of particles. By integrating a parallel attention mechanism and pairwise interactions of particles in the attention mechanism,ParMAT achieves robustness and higher accuracy over the ParT and ParticleNet. The scalability of the model to huge datasets and its ability to automatically extract essential features demonstrate its potential for enhancing jet tagging.
A Recent Survey of Vision Transformers for Medical Image Segmentation
Dec 01, 2023
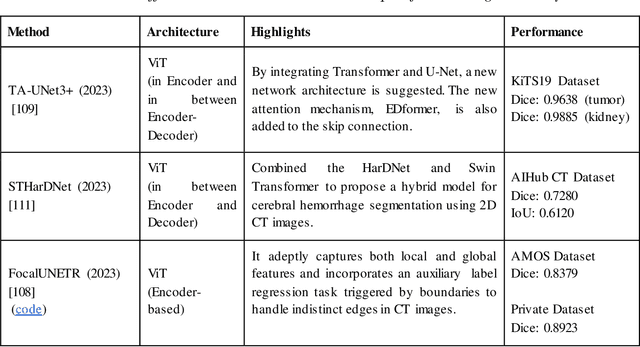

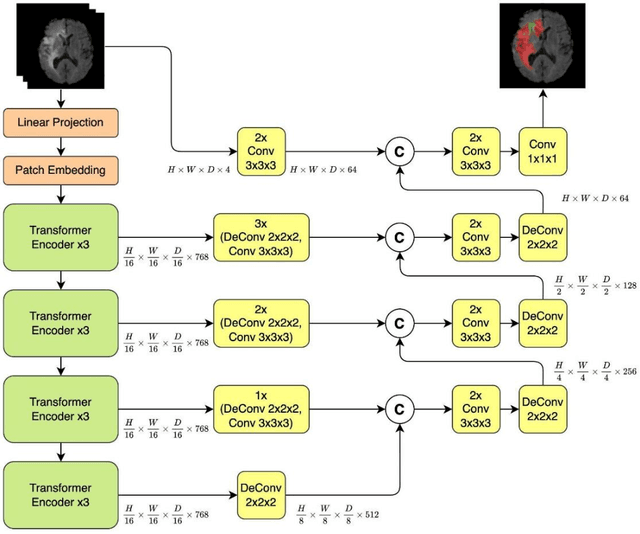
Medical image segmentation plays a crucial role in various healthcare applications, enabling accurate diagnosis, treatment planning, and disease monitoring. In recent years, Vision Transformers (ViTs) have emerged as a promising technique for addressing the challenges in medical image segmentation. In medical images, structures are usually highly interconnected and globally distributed. ViTs utilize their multi-scale attention mechanism to model the long-range relationships in the images. However, they do lack image-related inductive bias and translational invariance, potentially impacting their performance. Recently, researchers have come up with various ViT-based approaches that incorporate CNNs in their architectures, known as Hybrid Vision Transformers (HVTs) to capture local correlation in addition to the global information in the images. This survey paper provides a detailed review of the recent advancements in ViTs and HVTs for medical image segmentation. Along with the categorization of ViT and HVT-based medical image segmentation approaches we also present a detailed overview of their real-time applications in several medical image modalities. This survey may serve as a valuable resource for researchers, healthcare practitioners, and students in understanding the state-of-the-art approaches for ViT-based medical image segmentation.
MaxViT-UNet: Multi-Axis Attention for Medical Image Segmentation
May 25, 2023



Convolutional neural networks have made significant strides in medical image analysis in recent years. However, the local nature of the convolution operator inhibits the CNNs from capturing global and long-range interactions. Recently, Transformers have gained popularity in the computer vision community and also medical image segmentation. But scalability issues of self-attention mechanism and lack of the CNN like inductive bias have limited their adoption. In this work, we present MaxViT-UNet, an Encoder-Decoder based hybrid vision transformer for medical image segmentation. The proposed hybrid decoder, also based on MaxViT-block, is designed to harness the power of convolution and self-attention mechanism at each decoding stage with minimal computational burden. The multi-axis self-attention in each decoder stage helps in differentiating between the object and background regions much more efficiently. The hybrid decoder block initially fuses the lower level features upsampled via transpose convolution, with skip-connection features coming from hybrid encoder, then fused features are refined using multi-axis attention mechanism. The proposed decoder block is repeated multiple times to accurately segment the nuclei regions. Experimental results on MoNuSeg dataset proves the effectiveness of the proposed technique. Our MaxViT-UNet outperformed the previous CNN only (UNet) and Transformer only (Swin-UNet) techniques by a large margin of 2.36% and 5.31% on Dice metric respectively.