 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionSort: Enhanced Cluttered Waste Segmentation with Advanced Decoding and Comprehensive Modality Optimization
Aug 27, 2025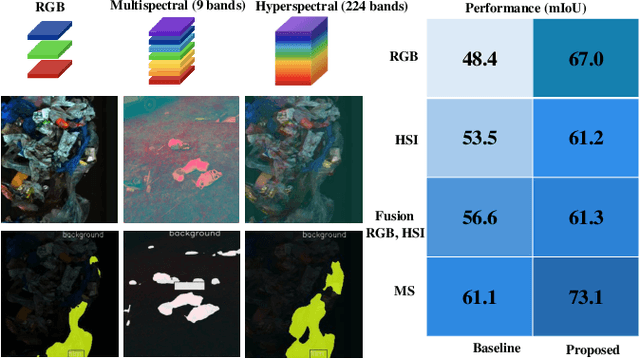



In the realm of waste management, automating the sorting process for non-biodegradable materials presents considerable challenges due to the complexity and variability of waste streams. To address these challenges, we introduce an enhanced neural architecture that builds upon an existing Encoder-Decoder structure to improve the accuracy and efficiency of waste sorting systems. Our model integrates several key innovations: a Comprehensive Attention Block within the decoder, which refines feature representations by combining convolutional and upsampling operations. In parallel, we utilize attention through the Mamba architecture, providing an additional performance boost. We also introduce a Data Fusion Block that fuses images with more than three channels. To achieve this, we apply PCA transformation to reduce the dimensionality while retaining the maximum variance and essential information across three dimensions, which are then used for further processing. We evaluated the model on RGB, hyperspectral, multispectral, and a combination of RGB and hyperspectral data. The results demonstrate that our approach outperforms existing methods by a significant margin.
Automated MRI Tumor Segmentation using hybrid U-Net with Transformer and Efficient Attention
Jun 18, 2025Cancer is an abnormal growth with potential to invade locally and metastasize to distant organs. Accurate auto-segmentation of the tumor and surrounding normal tissues is required for radiotherapy treatment plan optimization. Recent AI-based segmentation models are generally trained on large public datasets, which lack the heterogeneity of local patient populations. While these studies advance AI-based medical image segmentation, research on local datasets is necessary to develop and integrate AI tumor segmentation models directly into hospital software for efficient and accurate oncology treatment planning and execution. This study enhances tumor segmentation using computationally efficient hybrid UNet-Transformer models on magnetic resonance imaging (MRI) datasets acquired from a local hospital under strict privacy protection. We developed a robust data pipeline for seamless DICOM extraction and preprocessing, followed by extensive image augmentation to ensure model generalization across diverse clinical settings, resulting in a total dataset of 6080 images for training. Our novel architecture integrates UNet-based convolutional neural networks with a transformer bottleneck and complementary attention modules, including efficient attention, Squeeze-and-Excitation (SE) blocks, Convolutional Block Attention Module (CBAM), and ResNeXt blocks. To accelerate convergence and reduce computational demands, we used a maximum batch size of 8 and initialized the encoder with pretrained ImageNet weights, training the model on dual NVIDIA T4 GPUs via checkpointing to overcome Kaggle's runtime limits. Quantitative evaluation on the local MRI dataset yielded a Dice similarity coefficient of 0.764 and an Intersection over Union (IoU) of 0.736, demonstrating competitive performance despite limited data and underscoring the importance of site-specific model development for clinical deployment.
Intelligent Task Offloading in VANETs: A Hybrid AI-Driven Approach for Low-Latency and Energy Efficiency
Apr 29, 2025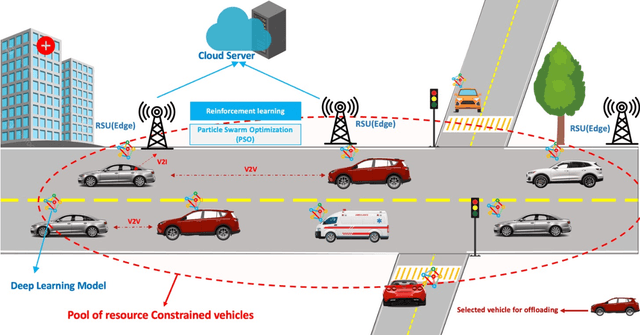
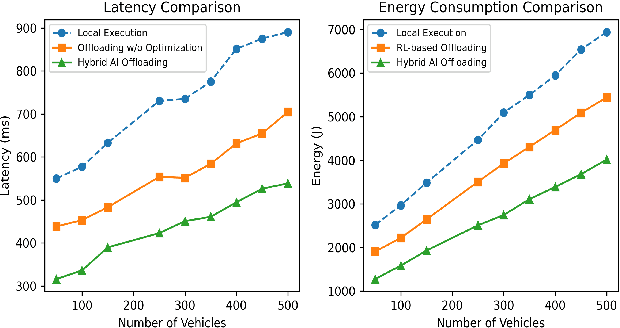
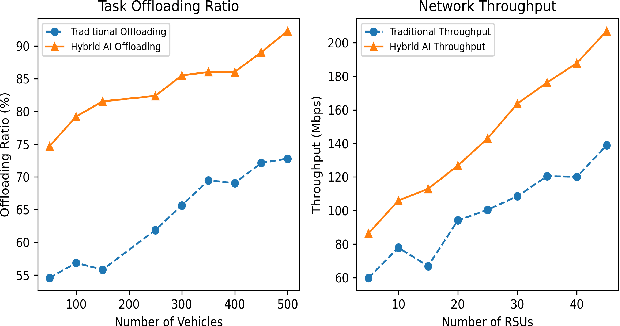
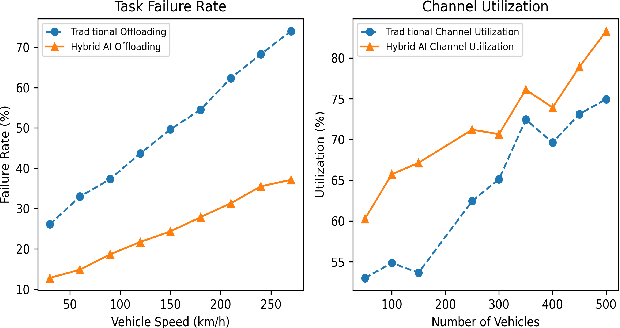
Vehicular Ad-hoc Networks (VANETs) are integral to intelligent transportation systems, enabling vehicles to offload computational tasks to nearby roadside units (RSUs) and mobile edge computing (MEC) servers for real-time processing. However, the highly dynamic nature of VANETs introduces challenges, such as unpredictable network conditions, high latency, energy inefficiency, and task failure. This research addresses these issues by proposing a hybrid AI framework that integrates supervised learning, reinforcement learning, and Particle Swarm Optimization (PSO) for intelligent task offloading and resource allocation. The framework leverages supervised models for predicting optimal offloading strategies, reinforcement learning for adaptive decision-making, and PSO for optimizing latency and energy consumption. Extensive simulations demonstrate that the proposed framework achieves significant reductions in latency and energy usage while improving task success rates and network throughput. By offering an efficient, and scalable solution, this framework sets the foundation for enhancing real-time applications in dynamic vehicular environments.
Performance Analysis of Traditional and Network Coded Transmission in Infrastructure-less Multi-hop Wireless Networks
Nov 21, 2024Infrastructure-less Multi-hop Wireless Networks are the backbone for mission critical communications such as in disaster and battlefield scenarios. However, interference signals in the wireless channel cause losses to transmission in wireless networks resulting in a reduced network throughput and making efficient transmission very challenging. Therefore, techniques to overcome interference and increase transmission efficiency have been a hot area of research for decades. In this paper two methods for transmitting data through infrastructure-less multi hop wireless networks, Traditional (TR) and Network Coded (NC) transmission are thoroughly examined for scenarios having one or two communication streams in a network. The study has developed network models in MATLAB for each transmission technique and scenario. The simulation results showed that the NC transmission method yielded a better throughput under the same network settings and physical interference. Furthermore, the impact of increasing numbers of hops between source and destination on the network capacity and the communications latency was also observed and conclusions were drawn.
COSNet: A Novel Semantic Segmentation Network using Enhanced Boundaries in Cluttered Scenes
Oct 31, 2024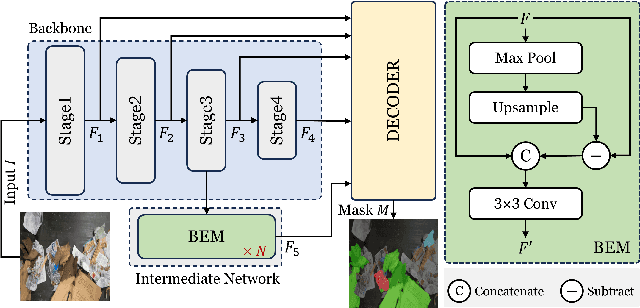

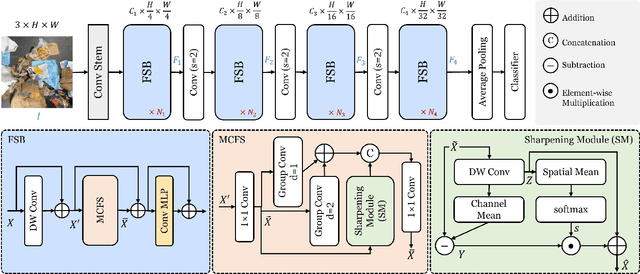

Automated waste recycling aims to efficiently separate the recyclable objects from the waste by employing vision-based systems. However, the presence of varying shaped objects having different material types makes it a challenging problem, especially in cluttered environments. Existing segmentation methods perform reasonably on many semantic segmentation datasets by employing multi-contextual representations, however, their performance is degraded when utilized for waste object segmentation in cluttered scenarios. In addition, plastic objects further increase the complexity of the problem due to their translucent nature. To address these limitations, we introduce an efficacious segmentation network, named COSNet, that uses boundary cues along with multi-contextual information to accurately segment the objects in cluttered scenes. COSNet introduces novel components including feature sharpening block (FSB) and boundary enhancement module (BEM) for enhancing the features and highlighting the boundary information of irregular waste objects in cluttered environment. Extensive experiments on three challenging datasets including ZeroWaste-f, SpectralWaste, and ADE20K demonstrate the effectiveness of the proposed method. Our COSNet achieves a significant gain of 1.8% on ZeroWaste-f and 2.1% on SpectralWaste datasets respectively in terms of mIoU metric.
Underwater Object Detection Enhancement via Channel Stabilization
Aug 02, 2024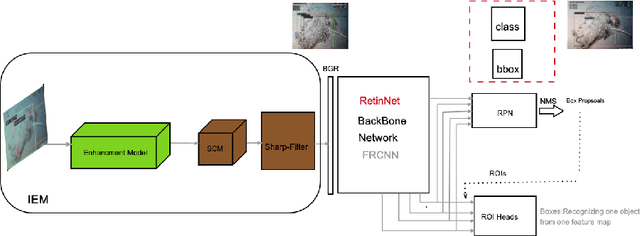


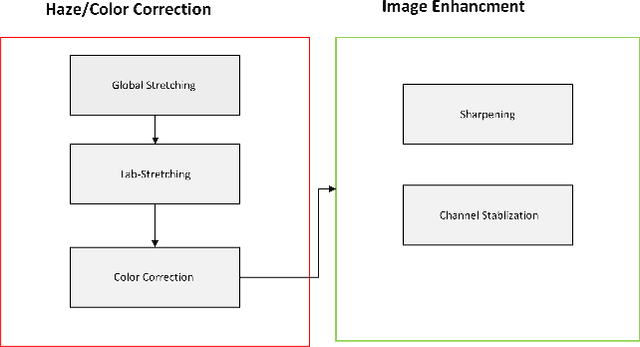
The complex marine environment exacerbates the challenges of object detection manifold. Marine trash endangers the aquatic ecosystem, presenting a persistent challenge. Accurate detection of marine deposits is crucial for mitigating this harm. Our work addresses underwater object detection by enhancing image quality and evaluating detection methods. We use Detectron2's backbone with various base models and configurations for this task. We propose a novel channel stabilization technique alongside a simplified image enhancement model to reduce haze and color cast in training images, improving multi-scale object detection. Following image processing, we test different Detectron2 backbones for optimal detection accuracy. Additionally, we apply a sharpening filter with augmentation techniques to highlight object profiles for easier recognition. Results are demonstrated on the TrashCan Dataset, both instance and material versions. The best-performing backbone method incorporates our channel stabilization and augmentation techniques. We also compare our Detectron2 detection results with the Deformable Transformer. In the instance version of TrashCan 1.0, our method achieves a 9.53% absolute increase in average precision for small objects and a 7% absolute gain in bounding box detection compared to the baseline. The code will be available on Code: https://github.com/aliman80/Underwater- Object-Detection-via-Channel-Stablization
Understanding the Interplay of Scale, Data, and Bias in Language Models: A Case Study with BERT
Jul 25, 2024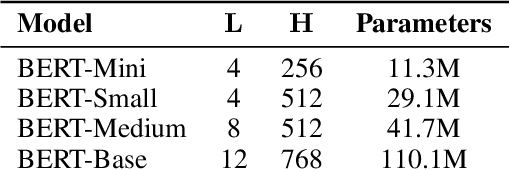



In the current landscape of language model research, larger models, larger datasets and more compute seems to be the only way to advance towards intelligence. While there have been extensive studies of scaling laws and models' scaling behaviors, the effect of scale on a model's social biases and stereotyping tendencies has received less attention. In this study, we explore the influence of model scale and pre-training data on its learnt social biases. We focus on BERT -- an extremely popular language model -- and investigate biases as they show up during language modeling (upstream), as well as during classification applications after fine-tuning (downstream). Our experiments on four architecture sizes of BERT demonstrate that pre-training data substantially influences how upstream biases evolve with model scale. With increasing scale, models pre-trained on large internet scrapes like Common Crawl exhibit higher toxicity, whereas models pre-trained on moderated data sources like Wikipedia show greater gender stereotypes. However, downstream biases generally decrease with increasing model scale, irrespective of the pre-training data. Our results highlight the qualitative role of pre-training data in the biased behavior of language models, an often overlooked aspect in the study of scale. Through a detailed case study of BERT, we shed light on the complex interplay of data and model scale, and investigate how it translates to concrete biases.
FANet: Feature Amplification Network for Semantic Segmentation in Cluttered Background
Jul 12, 2024Existing deep learning approaches leave out the semantic cues that are crucial in semantic segmentation present in complex scenarios including cluttered backgrounds and translucent objects, etc. To handle these challenges, we propose a feature amplification network (FANet) as a backbone network that incorporates semantic information using a novel feature enhancement module at multi-stages. To achieve this, we propose an adaptive feature enhancement (AFE) block that benefits from both a spatial context module (SCM) and a feature refinement module (FRM) in a parallel fashion. SCM aims to exploit larger kernel leverages for the increased receptive field to handle scale variations in the scene. Whereas our novel FRM is responsible for generating semantic cues that can capture both low-frequency and high-frequency regions for better segmentation tasks. We perform experiments over challenging real-world ZeroWaste-f dataset which contains background-cluttered and translucent objects. Our experimental results demonstrate the state-of-the-art performance compared to existing methods.
CLIP-Decoder : ZeroShot Multilabel Classification using Multimodal CLIP Aligned Representation
Jun 21, 2024Multi-label classification is an essential task utilized in a wide variety of real-world applications. Multi-label zero-shot learning is a method for classifying images into multiple unseen categories for which no training data is available, while in general zero-shot situations, the test set may include observed classes. The CLIP-Decoder is a novel method based on the state-of-the-art ML-Decoder attention-based head. We introduce multi-modal representation learning in CLIP-Decoder, utilizing the text encoder to extract text features and the image encoder for image feature extraction. Furthermore, we minimize semantic mismatch by aligning image and word embeddings in the same dimension and comparing their respective representations using a combined loss, which comprises classification loss and CLIP loss. This strategy outperforms other methods and we achieve cutting-edge results on zero-shot multilabel classification tasks using CLIP-Decoder. Our method achieves an absolute increase of 3.9% in performance compared to existing methods for zero-shot learning multi-label classification tasks. Additionally, in the generalized zero-shot learning multi-label classification task, our method shows an impressive increase of almost 2.3%.
Vision Transformers in Medical Computer Vision -- A Contemplative Retrospection
Mar 29, 2022
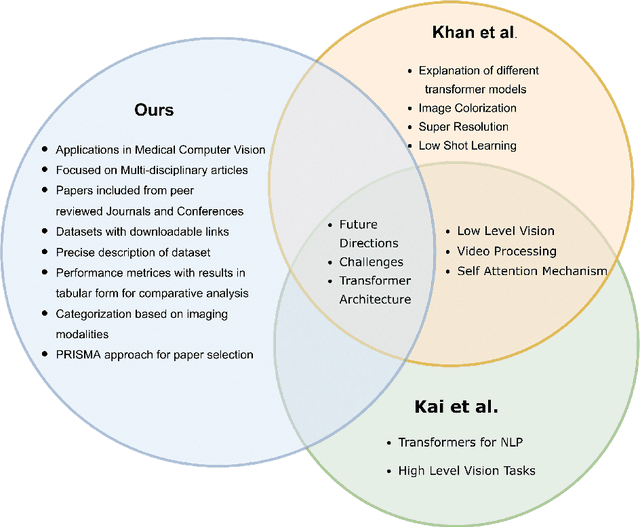
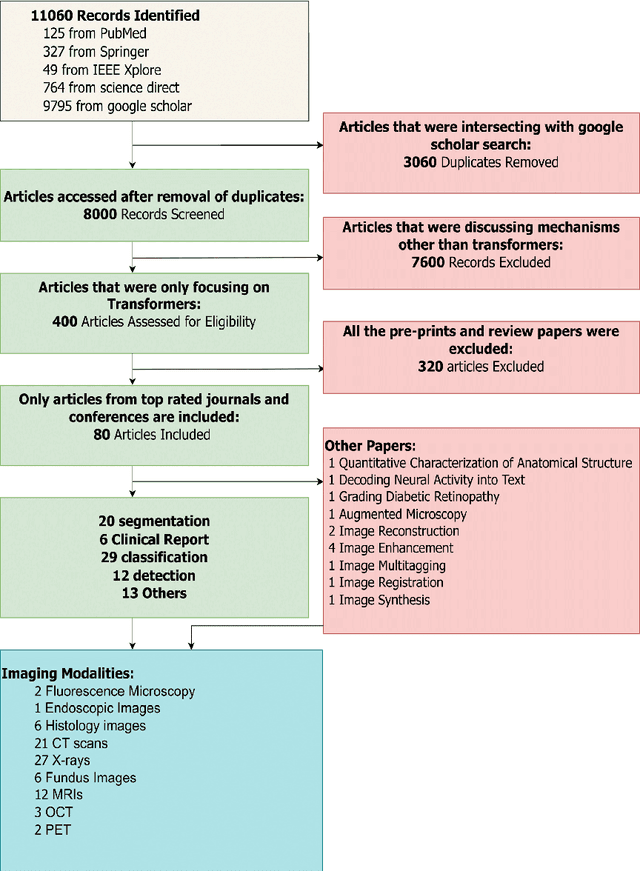
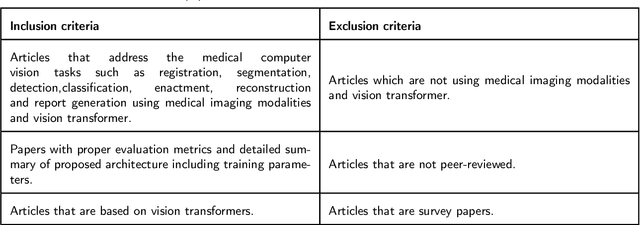
Recent escalation in the field of computer vision underpins a huddle of algorithms with the magnificent potential to unravel the information contained within images. These computer vision algorithms are being practised in medical image analysis and are transfiguring the perception and interpretation of Imaging data. Among these algorithms, Vision Transformers are evolved as one of the most contemporary and dominant architectures that are being used in the field of computer vision. These are immensely utilized by a plenty of researchers to perform new as well as former experiments. Here, in this article we investigate the intersection of Vision Transformers and Medical images and proffered an overview of various ViTs based frameworks that are being used by different researchers in order to decipher the obstacles in Medical Computer Vision. We surveyed the application of Vision transformers in different areas of medical computer vision such as image-based disease classification, anatomical structure segmentation, registration, region-based lesion Detection, captioning, report generation, reconstruction using multiple medical imaging modalities that greatly assist in medical diagnosis and hence treatment process. Along with this, we also demystify several imaging modalities used in Medical Computer Vision. Moreover, to get more insight and deeper understanding, self-attention mechanism of transformers is also explained briefly. Conclusively, we also put some light on available data sets, adopted methodology, their performance measures, challenges and their solutions in form of discussion. We hope that this review article will open future directions for researchers in medical computer vision.