 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOSNet: A Novel Semantic Segmentation Network using Enhanced Boundaries in Cluttered Scenes
Oct 31, 2024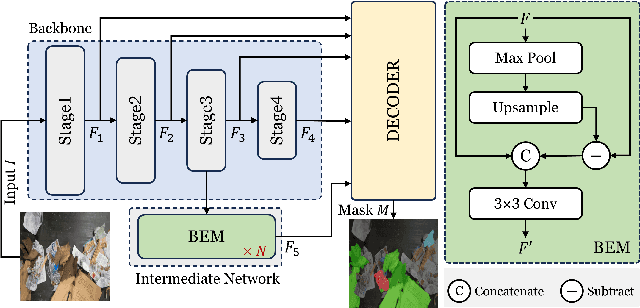

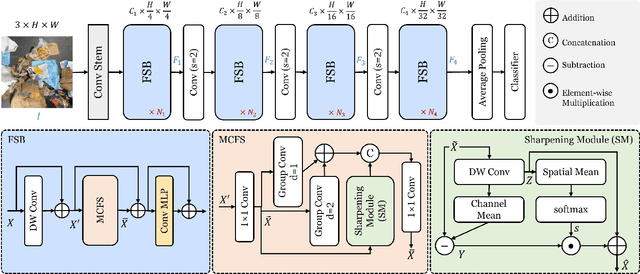

Automated waste recycling aims to efficiently separate the recyclable objects from the waste by employing vision-based systems. However, the presence of varying shaped objects having different material types makes it a challenging problem, especially in cluttered environments. Existing segmentation methods perform reasonably on many semantic segmentation datasets by employing multi-contextual representations, however, their performance is degraded when utilized for waste object segmentation in cluttered scenarios. In addition, plastic objects further increase the complexity of the problem due to their translucent nature. To address these limitations, we introduce an efficacious segmentation network, named COSNet, that uses boundary cues along with multi-contextual information to accurately segment the objects in cluttered scenes. COSNet introduces novel components including feature sharpening block (FSB) and boundary enhancement module (BEM) for enhancing the features and highlighting the boundary information of irregular waste objects in cluttered environment. Extensive experiments on three challenging datasets including ZeroWaste-f, SpectralWaste, and ADE20K demonstrate the effectiveness of the proposed method. Our COSNet achieves a significant gain of 1.8% on ZeroWaste-f and 2.1% on SpectralWaste datasets respectively in terms of mIoU metric.
FANet: Feature Amplification Network for Semantic Segmentation in Cluttered Background
Jul 12, 2024Existing deep learning approaches leave out the semantic cues that are crucial in semantic segmentation present in complex scenarios including cluttered backgrounds and translucent objects, etc. To handle these challenges, we propose a feature amplification network (FANet) as a backbone network that incorporates semantic information using a novel feature enhancement module at multi-stages. To achieve this, we propose an adaptive feature enhancement (AFE) block that benefits from both a spatial context module (SCM) and a feature refinement module (FRM) in a parallel fashion. SCM aims to exploit larger kernel leverages for the increased receptive field to handle scale variations in the scene. Whereas our novel FRM is responsible for generating semantic cues that can capture both low-frequency and high-frequency regions for better segmentation tasks. We perform experiments over challenging real-world ZeroWaste-f dataset which contains background-cluttered and translucent objects. Our experimental results demonstrate the state-of-the-art performance compared to existing methods.