 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Multi-Stuttered Speech Classification: Leveraging Whisper's Encoder for Efficient Parameter Reduction in Automated Assessment
Jun 12, 2024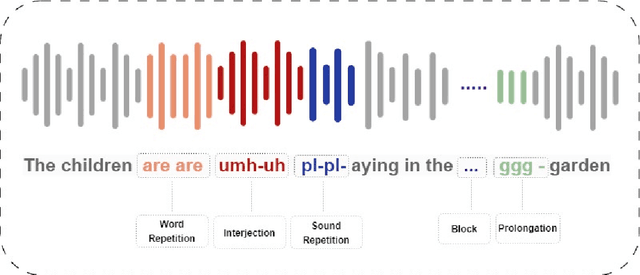



The automated classification of stuttered speech has significant implications for timely assessments providing assistance to speech language pathologists. Despite notable advancements in the field, the cases in which multiple disfluencies occur in speech require attention. We have taken a progressive approach to fill this gap by classifying multi-stuttered speech more efficiently. The problem has been addressed by firstly curating a dataset of multi-stuttered disfluencies from SEP-28k audio clips. Secondly, employing Whisper, a state-of-the-art speech recognition model has been leveraged by using its encoder and taking the problem as multi-label classification. Thirdly, using a 6 encoder layer Whisper and experimenting with various layer freezing strategies, a computationally efficient configuration of the model was identified. The proposed configuration achieved micro, macro, and weighted F1- scores of 0.88, 0.85, and 0.87, correspondingly on an external test dataset i.e. Fluency-Bank. In addition, through layer freezing strategies, we were able to achieve the aforementioned results by fine-tuning a single encoder layer, consequently, reducing the model's trainable parameters from 20.27 million to 3.29 million. This research study unveils the contribution of the last encoder layer in the identification of disfluencies in stuttered speech. Consequently, it has led to a computationally efficient approach which makes the model more adaptable for various dialects and languages.
Whisper in Focus: Enhancing Stuttered Speech Classification with Encoder Layer Optimization
Nov 09, 2023



In recent years, advancements in the field of speech processing have led to cutting-edge deep learning algorithms with immense potential for real-world applications. The automated identification of stuttered speech is one of such applications that the researchers are addressing by employing deep learning techniques. Recently, researchers have utilized Wav2vec2.0, a speech recognition model to classify disfluency types in stuttered speech. Although Wav2vec2.0 has shown commendable results, its ability to generalize across all disfluency types is limited. In addition, since its base model uses 12 encoder layers, it is considered a resource-intensive model. Our study unravels the capabilities of Whisper for the classification of disfluency types in stuttered speech. We have made notable contributions in three pivotal areas: enhancing the quality of SEP28-k benchmark dataset, exploration of Whisper for classification, and introducing an efficient encoder layer freezing strategy. The optimized Whisper model has achieved the average F1-score of 0.81, which proffers its abilities. This study also unwinds the significance of deeper encoder layers in the identification of disfluency types, as the results demonstrate their greater contribution compared to initial layers. This research represents substantial contributions, shifting the emphasis towards an efficient solution, thereby thriving towards prospective innovation.
Vision Transformers in Medical Computer Vision -- A Contemplative Retrospection
Mar 29, 2022
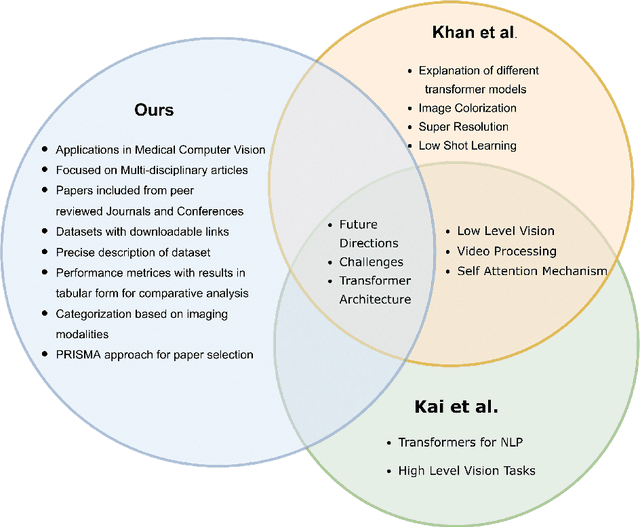
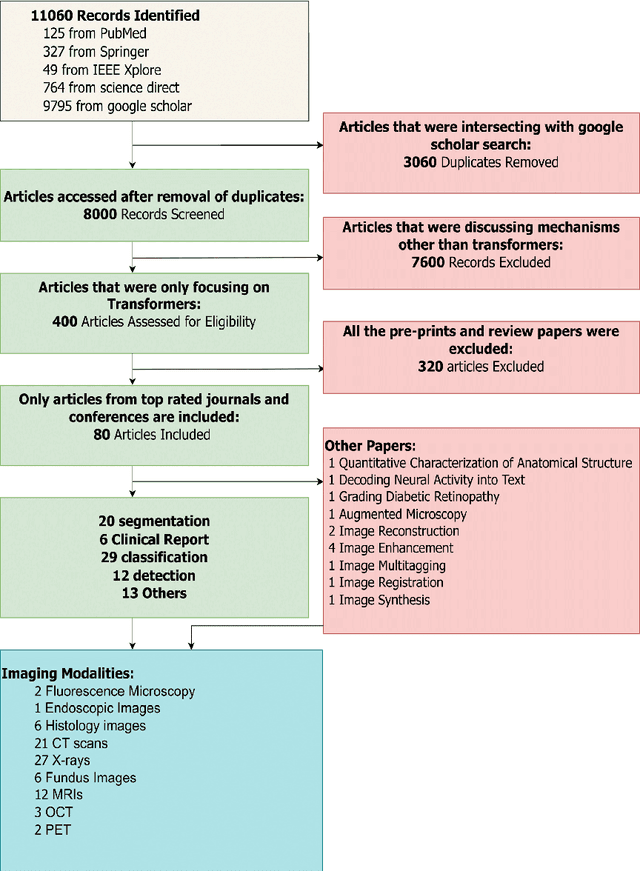
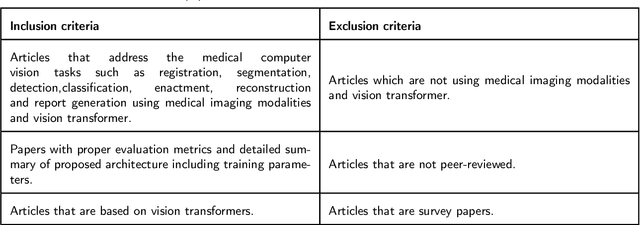
Recent escalation in the field of computer vision underpins a huddle of algorithms with the magnificent potential to unravel the information contained within images. These computer vision algorithms are being practised in medical image analysis and are transfiguring the perception and interpretation of Imaging data. Among these algorithms, Vision Transformers are evolved as one of the most contemporary and dominant architectures that are being used in the field of computer vision. These are immensely utilized by a plenty of researchers to perform new as well as former experiments. Here, in this article we investigate the intersection of Vision Transformers and Medical images and proffered an overview of various ViTs based frameworks that are being used by different researchers in order to decipher the obstacles in Medical Computer Vision. We surveyed the application of Vision transformers in different areas of medical computer vision such as image-based disease classification, anatomical structure segmentation, registration, region-based lesion Detection, captioning, report generation, reconstruction using multiple medical imaging modalities that greatly assist in medical diagnosis and hence treatment process. Along with this, we also demystify several imaging modalities used in Medical Computer Vision. Moreover, to get more insight and deeper understanding, self-attention mechanism of transformers is also explained briefly. Conclusively, we also put some light on available data sets, adopted methodology, their performance measures, challenges and their solutions in form of discussion. We hope that this review article will open future directions for researchers in medical computer vision.