 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Climate Risk of Generative AI: Region-Aware Carbon Accounting with G-TRACE and the AI Sustainability Pyramid
Nov 06, 2025



Generative Artificial Intelligence (GenAI) represents a rapidly expanding digital infrastructure whose energy demand and associated CO2 emissions are emerging as a new category of climate risk. This study introduces G-TRACE (GenAI Transformative Carbon Estimator), a cross-modal, region-aware framework that quantifies training- and inference-related emissions across modalities and deployment geographies. Using real-world analytics and microscopic simulation, G-TRACE measures energy use and carbon intensity per output type (text, image, video) and reveals how decentralized inference amplifies small per-query energy costs into system-level impacts. Through the Ghibli-style image generation trend (2024-2025), we estimate 4,309 MWh of energy consumption and 2,068 tCO2 emissions, illustrating how viral participation inflates individual digital actions into tonne-scale consequences. Building on these findings, we propose the AI Sustainability Pyramid, a seven-level governance model linking carbon accounting metrics (L1-L7) with operational readiness, optimization, and stewardship. This framework translates quantitative emission metrics into actionable policy guidance for sustainable AI deployment. The study contributes to the quantitative assessment of emerging digital infrastructures as a novel category of climate risk, supporting adaptive governance for sustainable technology deployment. By situating GenAI within climate-risk frameworks, the work advances data-driven methods for aligning technological innovation with global decarbonization and resilience objectives.
A Benchmark Dataset with Larger Context for Non-Factoid Question Answering over Islamic Text
Sep 15, 2024



Accessing and comprehending religious texts, particularly the Quran (the sacred scripture of Islam) and Ahadith (the corpus of the sayings or traditions of the Prophet Muhammad), in today's digital era necessitates efficient and accurate Question-Answering (QA) systems. Yet, the scarcity of QA systems tailored specifically to the detailed nature of inquiries about the Quranic Tafsir (explanation, interpretation, context of Quran for clarity) and Ahadith poses significant challenges. To address this gap, we introduce a comprehensive dataset meticulously crafted for QA purposes within the domain of Quranic Tafsir and Ahadith. This dataset comprises a robust collection of over 73,000 question-answer pairs, standing as the largest reported dataset in this specialized domain. Importantly, both questions and answers within the dataset are meticulously enriched with contextual information, serving as invaluable resources for training and evaluating tailored QA systems. However, while this paper highlights the dataset's contributions and establishes a benchmark for evaluating QA performance in the Quran and Ahadith domains, our subsequent human evaluation uncovered critical insights regarding the limitations of existing automatic evaluation techniques. The discrepancy between automatic evaluation metrics, such as ROUGE scores, and human assessments became apparent. The human evaluation indicated significant disparities: the model's verdict consistency with expert scholars ranged between 11% to 20%, while its contextual understanding spanned a broader spectrum of 50% to 90%. These findings underscore the necessity for evaluation techniques that capture the nuances and complexities inherent in understanding religious texts, surpassing the limitations of traditional automatic metrics.
Optimizing Multi-Stuttered Speech Classification: Leveraging Whisper's Encoder for Efficient Parameter Reduction in Automated Assessment
Jun 12, 2024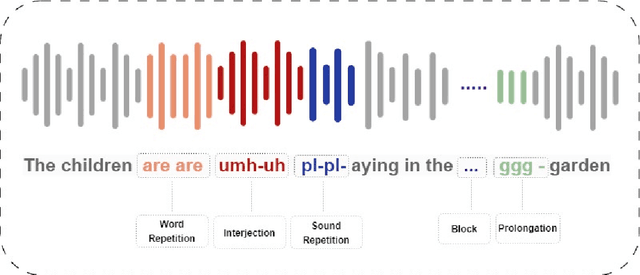



The automated classification of stuttered speech has significant implications for timely assessments providing assistance to speech language pathologists. Despite notable advancements in the field, the cases in which multiple disfluencies occur in speech require attention. We have taken a progressive approach to fill this gap by classifying multi-stuttered speech more efficiently. The problem has been addressed by firstly curating a dataset of multi-stuttered disfluencies from SEP-28k audio clips. Secondly, employing Whisper, a state-of-the-art speech recognition model has been leveraged by using its encoder and taking the problem as multi-label classification. Thirdly, using a 6 encoder layer Whisper and experimenting with various layer freezing strategies, a computationally efficient configuration of the model was identified. The proposed configuration achieved micro, macro, and weighted F1- scores of 0.88, 0.85, and 0.87, correspondingly on an external test dataset i.e. Fluency-Bank. In addition, through layer freezing strategies, we were able to achieve the aforementioned results by fine-tuning a single encoder layer, consequently, reducing the model's trainable parameters from 20.27 million to 3.29 million. This research study unveils the contribution of the last encoder layer in the identification of disfluencies in stuttered speech. Consequently, it has led to a computationally efficient approach which makes the model more adaptable for various dialects and languages.
Increasing Profitability and Confidence by using Interpretable Model for Investment Decisions
Dec 24, 2023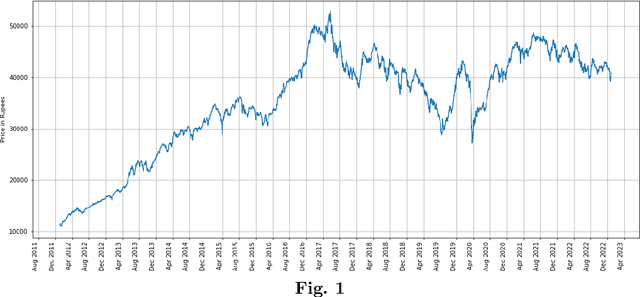

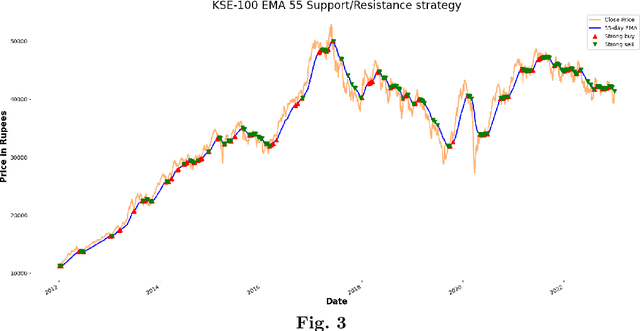
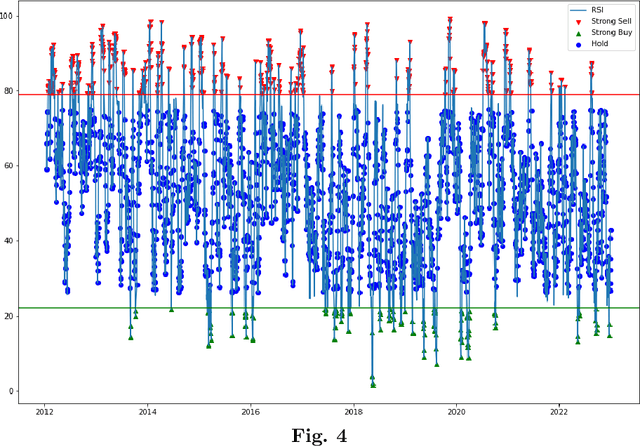
Financial forecasting plays an important role in making informed decisions for financial stakeholders, specifically in the stock exchange market. In a traditional setting, investors commonly rely on the equity research department for valuable reports on market insights and investment recommendations. The equity research department, however, faces challenges in effectuating decision-making due to the demanding cognitive effort required for analyzing the inherently volatile nature of market dynamics. Furthermore, financial forecasting systems employed by analysts pose potential risks in terms of interpretability and gaining the trust of all stakeholders. This paper presents an interpretable decision-making model leveraging the SHAP-based explainability technique to forecast investment recommendations. The proposed solution not only provides valuable insights into the factors that influence forecasted recommendations but also caters to investors of varying types, including those interested in daily and short-term investment opportunities. To ascertain the efficacy of the proposed model, a case study is devised that demonstrates a notable enhancement in investor's portfolio value, employing our trading strategies. The results highlight the significance of incorporating interpretability in forecasting models to boost stakeholders' confidence and foster transparency in the stock exchange domain.
Whisper in Focus: Enhancing Stuttered Speech Classification with Encoder Layer Optimization
Nov 09, 2023



In recent years, advancements in the field of speech processing have led to cutting-edge deep learning algorithms with immense potential for real-world applications. The automated identification of stuttered speech is one of such applications that the researchers are addressing by employing deep learning techniques. Recently, researchers have utilized Wav2vec2.0, a speech recognition model to classify disfluency types in stuttered speech. Although Wav2vec2.0 has shown commendable results, its ability to generalize across all disfluency types is limited. In addition, since its base model uses 12 encoder layers, it is considered a resource-intensive model. Our study unravels the capabilities of Whisper for the classification of disfluency types in stuttered speech. We have made notable contributions in three pivotal areas: enhancing the quality of SEP28-k benchmark dataset, exploration of Whisper for classification, and introducing an efficient encoder layer freezing strategy. The optimized Whisper model has achieved the average F1-score of 0.81, which proffers its abilities. This study also unwinds the significance of deeper encoder layers in the identification of disfluency types, as the results demonstrate their greater contribution compared to initial layers. This research represents substantial contributions, shifting the emphasis towards an efficient solution, thereby thriving towards prospective innovation.