 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Multi-Stuttered Speech Classification: Leveraging Whisper's Encoder for Efficient Parameter Reduction in Automated Assessment
Paper and Code
Jun 12, 2024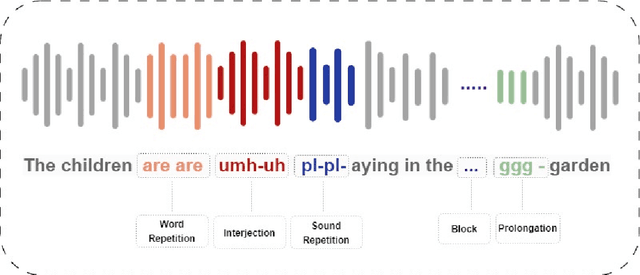



The automated classification of stuttered speech has significant implications for timely assessments providing assistance to speech language pathologists. Despite notable advancements in the field, the cases in which multiple disfluencies occur in speech require attention. We have taken a progressive approach to fill this gap by classifying multi-stuttered speech more efficiently. The problem has been addressed by firstly curating a dataset of multi-stuttered disfluencies from SEP-28k audio clips. Secondly, employing Whisper, a state-of-the-art speech recognition model has been leveraged by using its encoder and taking the problem as multi-label classification. Thirdly, using a 6 encoder layer Whisper and experimenting with various layer freezing strategies, a computationally efficient configuration of the model was identified. The proposed configuration achieved micro, macro, and weighted F1- scores of 0.88, 0.85, and 0.87, correspondingly on an external test dataset i.e. Fluency-Bank. In addition, through layer freezing strategies, we were able to achieve the aforementioned results by fine-tuning a single encoder layer, consequently, reducing the model's trainable parameters from 20.27 million to 3.29 million. This research study unveils the contribution of the last encoder layer in the identification of disfluencies in stuttered speech. Consequently, it has led to a computationally efficient approach which makes the model more adaptable for various dialects and languages.