 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Faces and Voices Across Languages: Insights from the FAME 2026 Challenge
Dec 23, 2025Over half of the world's population is bilingual and people often communicate under multilingual scenarios. The Face-Voice Association in Multilingual Environments (FAME) 2026 Challenge, held at ICASSP 2026, focuses on developing methods for face-voice association that are effective when the language at test-time is different than the training one. This report provides a brief summary of the challenge.
Modality Invariant Multimodal Learning to Handle Missing Modalities: A Single-Branch Approach
Aug 14, 2024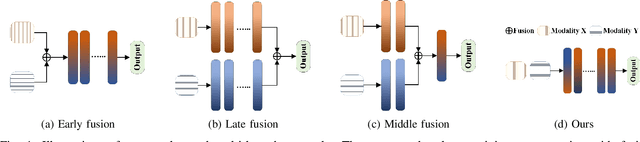


Multimodal networks have demonstrated remarkable performance improvements over their unimodal counterparts. Existing multimodal networks are designed in a multi-branch fashion that, due to the reliance on fusion strategies, exhibit deteriorated performance if one or more modalities are missing. In this work, we propose a modality invariant multimodal learning method, which is less susceptible to the impact of missing modalities. It consists of a single-branch network sharing weights across multiple modalities to learn inter-modality representations to maximize performance as well as robustness to missing modalities. Extensive experiments are performed on four challenging datasets including textual-visual (UPMC Food-101, Hateful Memes, Ferramenta) and audio-visual modalities (VoxCeleb1). Our proposed method achieves superior performance when all modalities are present as well as in the case of missing modalities during training or testing compared to the existing state-of-the-art methods.
Face-voice Association in Multilingual Environments (FAME) Challenge 2024 Evaluation Plan
Apr 16, 2024The advancements of technology have led to the use of multimodal systems in various real-world applications. Among them, the audio-visual systems are one of the widely used multimodal systems. In the recent years, associating face and voice of a person has gained attention due to presence of unique correlation between them. The Face-voice Association in Multilingual Environments (FAME) Challenge 2024 focuses on exploring face-voice association under a unique condition of multilingual scenario. This condition is inspired from the fact that half of the world's population is bilingual and most often people communicate under multilingual scenario. The challenge uses a dataset namely, Multilingual Audio-Visual (MAV-Celeb) for exploring face-voice association in multilingual environments. This report provides the details of the challenge, dataset, baselines and task details for the FAME Challenge.
Classification of Potholes Based on Surface Area Using Pre-Trained Models of Convolutional Neural Network
Sep 29, 2023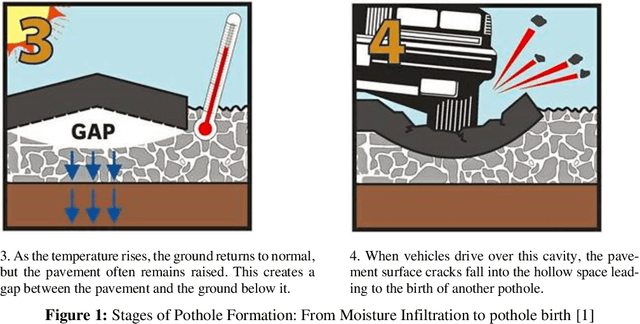
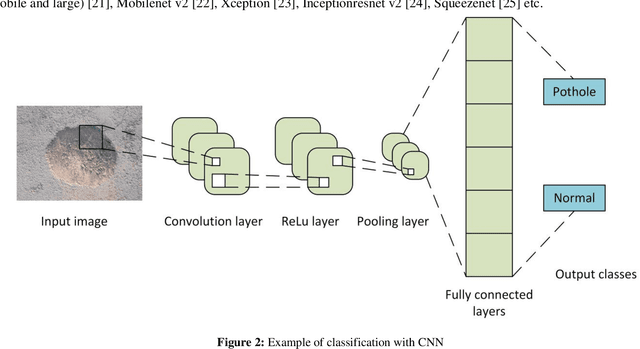
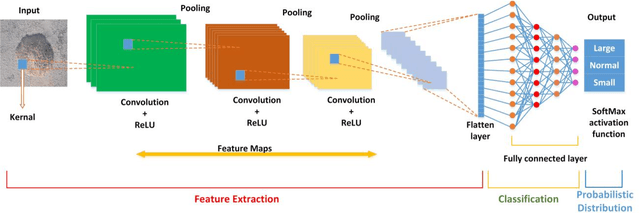
Potholes are fatal and can cause severe damage to vehicles as well as can cause deadly accidents. In South Asian countries, pavement distresses are the primary cause due to poor subgrade conditions, lack of subsurface drainage, and excessive rainfalls. The present research compares the performance of three pre-trained Convolutional Neural Network (CNN) models, i.e., ResNet 50, ResNet 18, and MobileNet. At first, pavement images are classified to find whether images contain potholes, i.e., Potholes or Normal. Secondly, pavements images are classi-fied into three categories, i.e., Small Pothole, Large Pothole, and Normal. Pavement images are taken from 3.5 feet (waist height) and 2 feet. MobileNet v2 has an accuracy of 98% for detecting a pothole. The classification of images taken at the height of 2 feet has an accuracy value of 87.33%, 88.67%, and 92% for classifying the large, small, and normal pavement, respectively. Similarly, the classification of the images taken from full of waist (FFW) height has an accuracy value of 98.67%, 98.67%, and 100%.
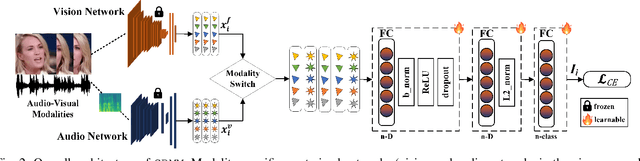
Single-branch Network for Multimodal Training
Mar 10, 2023With the rapid growth of social media platforms, users are sharing billions of multimedia posts containing audio, images, and text. Researchers have focused on building autonomous systems capable of processing such multimedia data to solve challenging multimodal tasks including cross-modal retrieval, matching, and verification. Existing works use separate networks to extract embeddings of each modality to bridge the gap between them. The modular structure of their branched networks is fundamental in creating numerous multimodal applications and has become a defacto standard to handle multiple modalities. In contrast, we propose a novel single-branch network capable of learning discriminative representation of unimodal as well as multimodal tasks without changing the network. An important feature of our single-branch network is that it can be trained either using single or multiple modalities without sacrificing performance. We evaluated our proposed single-branch network on the challenging multimodal problem (face-voice association) for cross-modal verification and matching tasks with various loss formulations. Experimental results demonstrate the superiority of our proposed single-branch network over the existing methods in a wide range of experiments. Code: https://github.com/msaadsaeed/SBNet
Speaker Recognition in Realistic Scenario Using Multimodal Data
Feb 25, 2023



In recent years, an association is established between faces and voices of celebrities leveraging large scale audio-visual information from YouTube. The availability of large scale audio-visual datasets is instrumental in developing speaker recognition methods based on standard Convolutional Neural Networks. Thus, the aim of this paper is to leverage large scale audio-visual information to improve speaker recognition task. To achieve this task, we proposed a two-branch network to learn joint representations of faces and voices in a multimodal system. Afterwards, features are extracted from the two-branch network to train a classifier for speaker recognition. We evaluated our proposed framework on a large scale audio-visual dataset named VoxCeleb$1$. Our results show that addition of facial information improved the performance of speaker recognition. Moreover, our results indicate that there is an overlap between face and voice.
Learning Branched Fusion and Orthogonal Projection for Face-Voice Association
Aug 22, 2022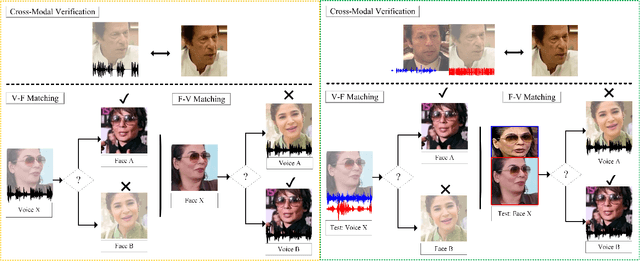
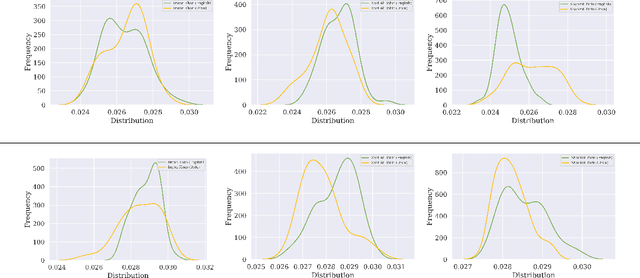


Recent years have seen an increased interest in establishing association between faces and voices of celebrities leveraging audio-visual information from YouTube. Prior works adopt metric learning methods to learn an embedding space that is amenable for associated matching and verification tasks. Albeit showing some progress, such formulations are, however, restrictive due to dependency on distance-dependent margin parameter, poor run-time training complexity, and reliance on carefully crafted negative mining procedures. In this work, we hypothesize that an enriched representation coupled with an effective yet efficient supervision is important towards realizing a discriminative joint embedding space for face-voice association tasks. To this end, we propose a light-weight, plug-and-play mechanism that exploits the complementary cues in both modalities to form enriched fused embeddings and clusters them based on their identity labels via orthogonality constraints. We coin our proposed mechanism as fusion and orthogonal projection (FOP) and instantiate in a two-stream network. The overall resulting framework is evaluated on VoxCeleb1 and MAV-Celeb datasets with a multitude of tasks, including cross-modal verification and matching. Results reveal that our method performs favourably against the current state-of-the-art methods and our proposed formulation of supervision is more effective and efficient than the ones employed by the contemporary methods. In addition, we leverage cross-modal verification and matching tasks to analyze the impact of multiple languages on face-voice association. Code is available: \url{https://github.com/msaadsaeed/FOP}
Fusion and Orthogonal Projection for Improved Face-Voice Association
Dec 20, 2021
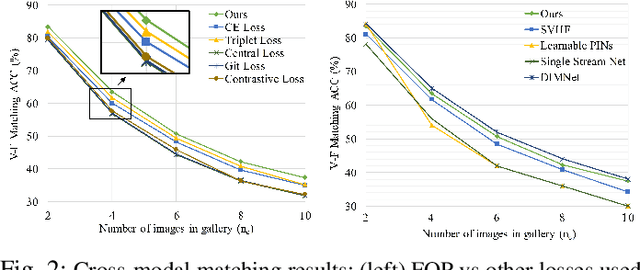


We study the problem of learning association between face and voice, which is gaining interest in the computer vision community lately. Prior works adopt pairwise or triplet loss formulations to learn an embedding space amenable for associated matching and verification tasks. Albeit showing some progress, such loss formulations are, however, restrictive due to dependency on distance-dependent margin parameter, poor run-time training complexity, and reliance on carefully crafted negative mining procedures. In this work, we hypothesize that enriched feature representation coupled with an effective yet efficient supervision is necessary in realizing a discriminative joint embedding space for improved face-voice association. To this end, we propose a light-weight, plug-and-play mechanism that exploits the complementary cues in both modalities to form enriched fused embeddings and clusters them based on their identity labels via orthogonality constraints. We coin our proposed mechanism as fusion and orthogonal projection (FOP) and instantiate in a two-stream pipeline. The overall resulting framework is evaluated on a large-scale VoxCeleb dataset with a multitude of tasks, including cross-modal verification and matching. Results show that our method performs favourably against the current state-of-the-art methods and our proposed supervision formulation is more effective and efficient than the ones employed by the contemporary methods.
Cross-modal Speaker Verification and Recognition: A Multilingual Perspective
Apr 28, 2020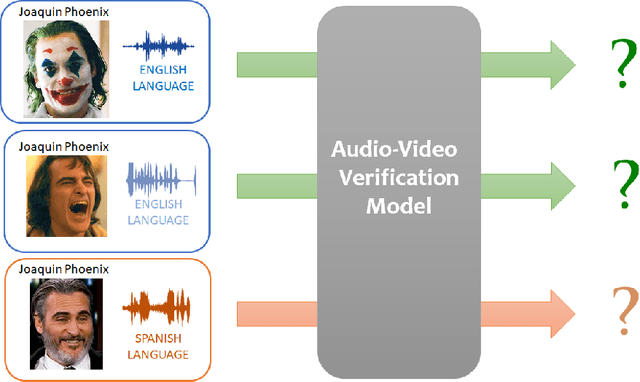


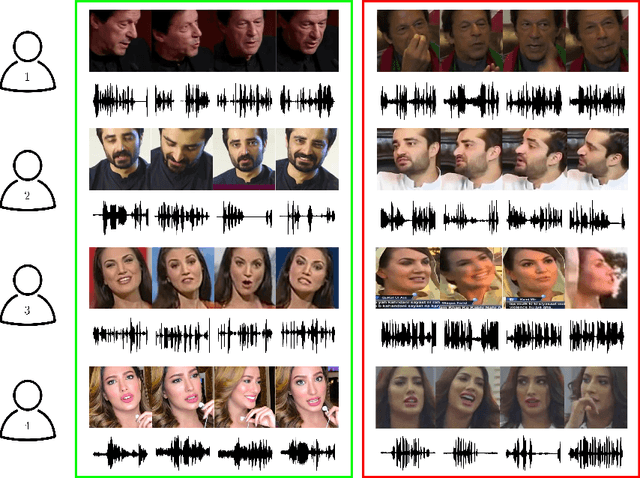
Recent years have seen a surge in finding association between faces and voices within a cross-modal biometric application along with speaker recognition. Inspired from this, we introduce a challenging task in establishing association between faces and voices across multiple languages spoken by the same set of persons. The aim of this paper is to answer two closely related questions: \textit{"Is face-voice association language independent?"} and \textit{"Can a speaker be recognised irrespective of the spoken language?"}. These two questions are very important to understand effectiveness and to boost development of multilingual biometric systems. To answer them, we collected a Multilingual Audio-Visual dataset, containing human speech clips of $154$ identities with $3$ language annotations extracted from various videos uploaded online. Extensive experiments on the three splits of the proposed dataset have been performed to investigate and answer these novel research questions that clearly point out the relevance of the multilingual problem.