 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality Invariant Multimodal Learning to Handle Missing Modalities: A Single-Branch Approach
Paper and Code
Aug 14, 2024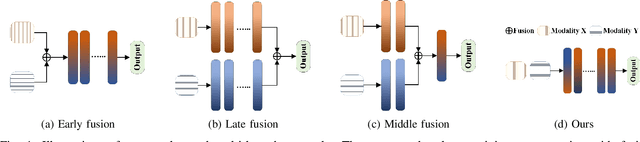
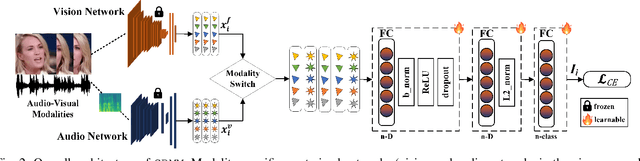


Multimodal networks have demonstrated remarkable performance improvements over their unimodal counterparts. Existing multimodal networks are designed in a multi-branch fashion that, due to the reliance on fusion strategies, exhibit deteriorated performance if one or more modalities are missing. In this work, we propose a modality invariant multimodal learning method, which is less susceptible to the impact of missing modalities. It consists of a single-branch network sharing weights across multiple modalities to learn inter-modality representations to maximize performance as well as robustness to missing modalities. Extensive experiments are performed on four challenging datasets including textual-visual (UPMC Food-101, Hateful Memes, Ferramenta) and audio-visual modalities (VoxCeleb1). Our proposed method achieves superior performance when all modalities are present as well as in the case of missing modalities during training or testing compared to the existing state-of-the-art methods.