 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSFM: Hard-Set-Guided Feature-Space Meta-Learning for Robust Classification under Spurious Correlations
Mar 31, 2026Deep neural networks often rely on spurious features to make predictions, which makes them brittle under distribution shift and on samples where the spurious correlation does not hold (e.g., minority-group examples). Recent studies have shown that, even in such settings, the feature extractor of an Empirical Risk Minimization (ERM)-trained model can learn rich and informative representations, and that much of the failure may be attributed to the classifier head. In particular, retraining a lightweight head while keeping the backbone frozen can substantially improve performance on shifted distributions and minority groups. Motivated by this observation, we propose a bilevel meta-learning method that performs augmentation directly in feature space to improve spurious correlation handling in the classifier head. Our method learns support-side feature edits such that, after a small number of inner-loop updates on the edited features, the classifier achieves lower loss on hard examples and improved worst-group performance. By operating at the backbone output rather than in pixel space or through end-to-end optimization, the method is highly efficient and stable, requiring only a few minutes of training on a single GPU. We further validate our method with CLIP-based visualizations, showing that the learned feature-space updates induce semantically meaningful shifts aligned with spurious attributes.
EdgeDAM: Real-time Object Tracking for Mobile Devices
Mar 05, 2026Single-object tracking (SOT) on edge devices is a critical computer vision task, requiring accurate and continuous target localization across video frames under occlusion, distractor interference, and fast motion. However, recent state-of-the-art distractor-aware memory mechanisms are largely built on segmentation-based trackers and rely on mask prediction and attention-driven memory updates, which introduce substantial computational overhead and limit real-time deployment on resource-constrained hardware; meanwhile, lightweight trackers sustain high throughput but are prone to drift when visually similar distractors appear. To address these challenges, we propose EdgeDAM, a lightweight detection-guided tracking framework that reformulates distractor-aware memory for bounding-box tracking under strict edge constraints. EdgeDAM introduces two key strategies: (1) Dual-Buffer Distractor-Aware Memory (DAM), which integrates a Recent-Aware Memory to preserve temporally consistent target hypotheses and a Distractor-Resolving Memory to explicitly store hard negative candidates and penalize their re-selection during recovery; and (2) Confidence-Driven Switching with Held-Box Stabilization, where tracker reliability and temporal consistency criteria adaptively activate detection and memory-guided re-identification during occlusion, while a held-box mechanism temporarily freezes and expands the estimate to suppress distractor contamination. Extensive experiments on five benchmarks, including the distractor-focused DiDi dataset, demonstrate improved robustness under occlusion and fast motion while maintaining real-time performance on mobile devices, achieving 88.2% accuracy on DiDi and 25 FPS on an iPhone 15. Code will be released.
GenMix: Effective Data Augmentation with Generative Diffusion Model Image Editing
Dec 03, 2024



Data augmentation is widely used to enhance generalization in visual classification tasks. However, traditional methods struggle when source and target domains differ, as in domain adaptation, due to their inability to address domain gaps. This paper introduces GenMix, a generalizable prompt-guided generative data augmentation approach that enhances both in-domain and cross-domain image classification. Our technique leverages image editing to generate augmented images based on custom conditional prompts, designed specifically for each problem type. By blending portions of the input image with its edited generative counterpart and incorporating fractal patterns, our approach mitigates unrealistic images and label ambiguity, improving the performance and adversarial robustness of the resulting models. Efficacy of our method is established with extensive experiments on eight public datasets for general and fine-grained classification, in both in-domain and cross-domain settings. Additionally, we demonstrate performance improvements for self-supervised learning, learning with data scarcity, and adversarial robustness. As compared to the existing state-of-the-art methods, our technique achieves stronger performance across the board.
Deep Learning for Video-based Person Re-Identification: A Survey
Mar 21, 2023Video-based person re-identification (video re-ID) has lately fascinated growing attention due to its broad practical applications in various areas, such as surveillance, smart city, and public safety. Nevertheless, video re-ID is quite difficult and is an ongoing stage due to numerous uncertain challenges such as viewpoint, occlusion, pose variation, and uncertain video sequence, etc. In the last couple of years, deep learning on video re-ID has continuously achieved surprising results on public datasets, with various approaches being developed to handle diverse problems in video re-ID. Compared to image-based re-ID, video re-ID is much more challenging and complex. To encourage future research and challenges, this first comprehensive paper introduces a review of up-to-date advancements in deep learning approaches for video re-ID. It broadly covers three important aspects, including brief video re-ID methods with their limitations, major milestones with technical challenges, and architectural design. It offers comparative performance analysis on various available datasets, guidance to improve video re-ID with valuable thoughts, and exciting research directions.
Recent Advances in Vision Transformer: A Survey and Outlook of Recent Work
Mar 10, 2022



Vision Transformers (ViTs) are becoming more popular and dominating technique for various vision tasks, compare to Convolutional Neural Networks (CNNs). As a demanding technique in computer vision, ViTs have been successfully solved various vision problems while focusing on long-range relationships. In this paper, we begin by introducing the fundamental concepts and background of the self-attention mechanism. Next, we provide a comprehensive overview of recent top-performing ViT methods describing in terms of strength and weakness, computational cost as well as training and testing dataset. We thoroughly compare the performance of various ViT algorithms and most representative CNN methods on popular benchmark datasets. Finally, we explore some limitations with insightful observations and provide further research direction. The project page along with the collections of papers are available at https://github.com/khawar512/ViT-Survey
Image Compression with Recurrent Neural Network and Generalized Divisive Normalization
Sep 05, 2021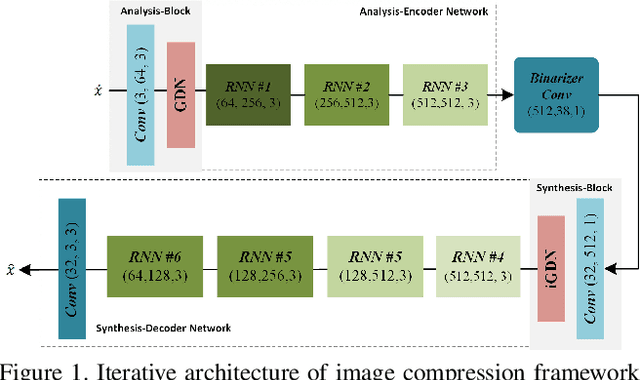
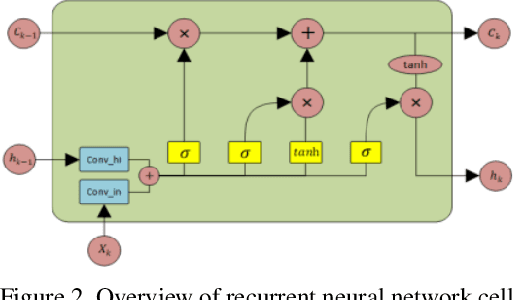
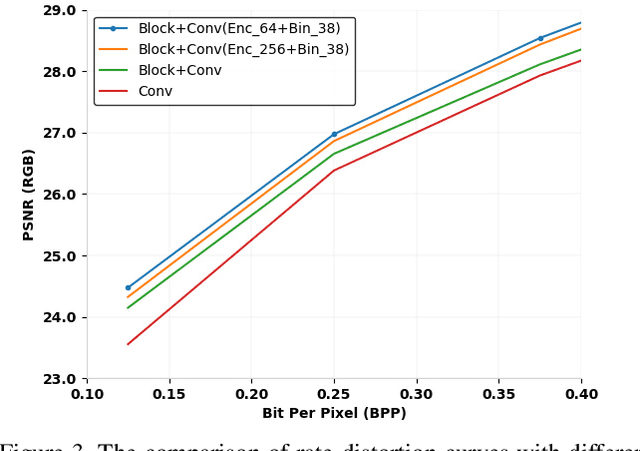
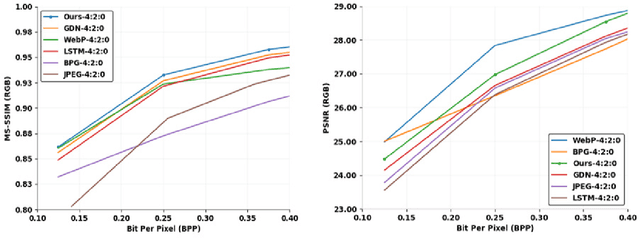
Image compression is a method to remove spatial redundancy between adjacent pixels and reconstruct a high-quality image. In the past few years, deep learning has gained huge attention from the research community and produced promising image reconstruction results. Therefore, recent methods focused on developing deeper and more complex networks, which significantly increased network complexity. In this paper, two effective novel blocks are developed: analysis and synthesis block that employs the convolution layer and Generalized Divisive Normalization (GDN) in the variable-rate encoder and decoder side. Our network utilizes a pixel RNN approach for quantization. Furthermore, to improve the whole network, we encode a residual image using LSTM cells to reduce unnecessary information. Experimental results demonstrated that the proposed variable-rate framework with novel blocks outperforms existing methods and standard image codecs, such as George's ~\cite{002} and JPEG in terms of image similarity. The project page along with code and models are available at https://khawar512.github.io/cvpr/
Framework for Passenger Seat Availability Using Face Detection in Passenger Bus
Jul 12, 2020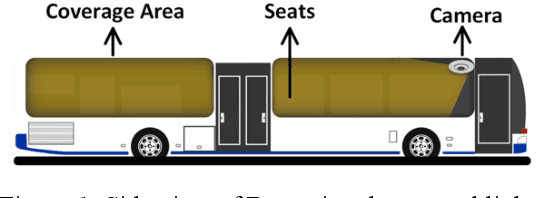



Advancements in Intelligent Transportation System (IES) improve passenger traveling by providing information systems for bus arrival time and counting the number of passengers and buses in cities. Passengers still face bus waiting and seat unavailability issues which have adverse effects on traffic management and controlling authority. We propose a Face Detection based Framework (FDF) to determine passenger seat availability in a camera-equipped bus through face detection which is based on background subtraction to count empty, filled, and total seats. FDF has an integrated smartphone Passenger Application (PA) to identify the nearest bus stop. We evaluate FDF in a live test environment and results show that it gives 90% accuracy. We believe our results have the potential to address traffic management concerns and assist passengers to save their valuable time