 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElevating 3D Models: High-Quality Texture and Geometry Refinement from a Low-Quality Model
Jul 15, 2025



High-quality 3D assets are essential for various applications in computer graphics and 3D vision but remain scarce due to significant acquisition costs. To address this shortage, we introduce Elevate3D, a novel framework that transforms readily accessible low-quality 3D assets into higher quality. At the core of Elevate3D is HFS-SDEdit, a specialized texture enhancement method that significantly improves texture quality while preserving the appearance and geometry while fixing its degradations. Furthermore, Elevate3D operates in a view-by-view manner, alternating between texture and geometry refinement. Unlike previous methods that have largely overlooked geometry refinement, our framework leverages geometric cues from images refined with HFS-SDEdit by employing state-of-the-art monocular geometry predictors. This approach ensures detailed and accurate geometry that aligns seamlessly with the enhanced texture. Elevate3D outperforms recent competitors by achieving state-of-the-art quality in 3D model refinement, effectively addressing the scarcity of high-quality open-source 3D assets.
360$^\circ$ Reconstruction From a Single Image Using Space Carved Outpainting
Sep 19, 2023
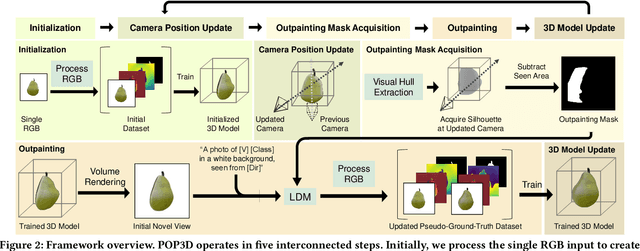

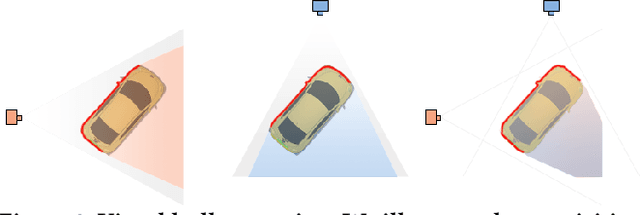
We introduce POP3D, a novel framework that creates a full $360^\circ$-view 3D model from a single image. POP3D resolves two prominent issues that limit the single-view reconstruction. Firstly, POP3D offers substantial generalizability to arbitrary categories, a trait that previous methods struggle to achieve. Secondly, POP3D further improves reconstruction fidelity and naturalness, a crucial aspect that concurrent works fall short of. Our approach marries the strengths of four primary components: (1) a monocular depth and normal predictor that serves to predict crucial geometric cues, (2) a space carving method capable of demarcating the potentially unseen portions of the target object, (3) a generative model pre-trained on a large-scale image dataset that can complete unseen regions of the target, and (4) a neural implicit surface reconstruction method tailored in reconstructing objects using RGB images along with monocular geometric cues. The combination of these components enables POP3D to readily generalize across various in-the-wild images and generate state-of-the-art reconstructions, outperforming similar works by a significant margin. Project page: \url{http://cg.postech.ac.kr/research/POP3D}
Speech Gesture Generation from the Trimodal Context of Text, Audio, and Speaker Identity
Sep 04, 2020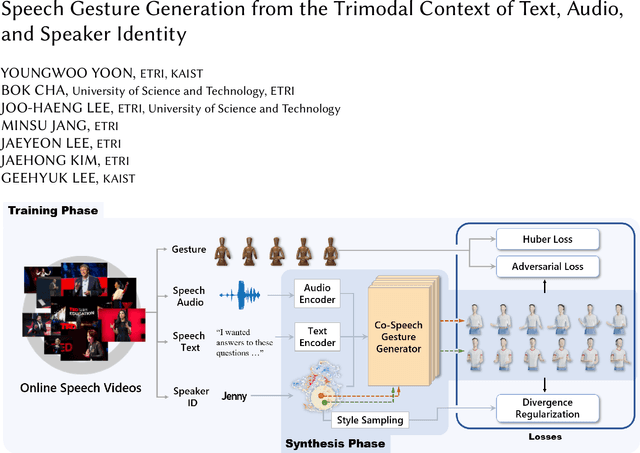
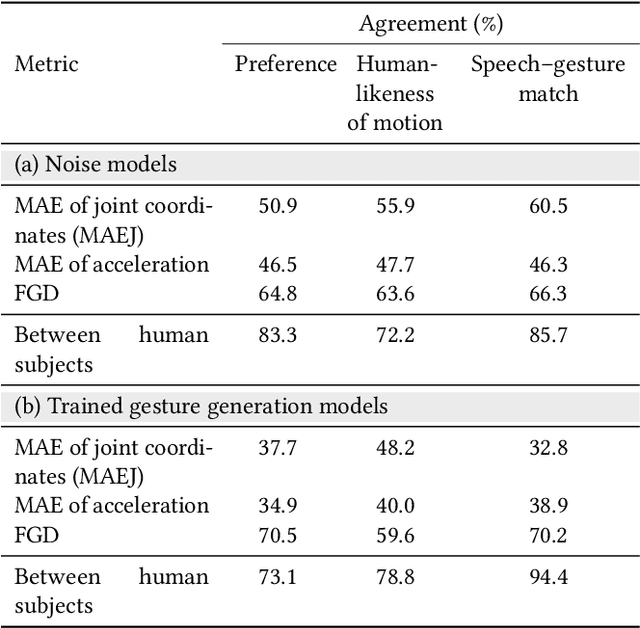
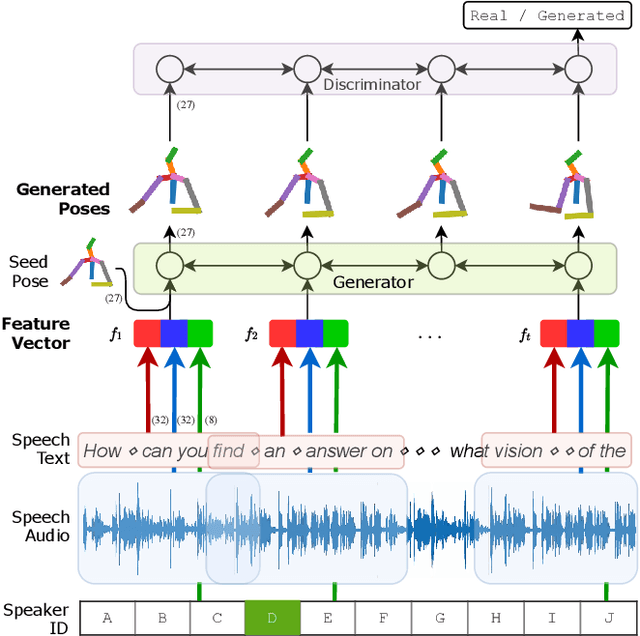

For human-like agents, including virtual avatars and social robots, making proper gestures while speaking is crucial in human--agent interaction. Co-speech gestures enhance interaction experiences and make the agents look alive. However, it is difficult to generate human-like gestures due to the lack of understanding of how people gesture. Data-driven approaches attempt to learn gesticulation skills from human demonstrations, but the ambiguous and individual nature of gestures hinders learning. In this paper, we present an automatic gesture generation model that uses the multimodal context of speech text, audio, and speaker identity to reliably generate gestures. By incorporating a multimodal context and an adversarial training scheme, the proposed model outputs gestures that are human-like and that match with speech content and rhythm. We also introduce a new quantitative evaluation metric for gesture generation models. Experiments with the introduced metric and subjective human evaluation showed that the proposed gesture generation model is better than existing end-to-end generation models. We further confirm that our model is able to work with synthesized audio in a scenario where contexts are constrained, and show that different gesture styles can be generated for the same speech by specifying different speaker identities in the style embedding space that is learned from videos of various speakers. All the code and data is available at https://github.com/ai4r/Gesture-Generation-from-Trimodal-Context.
C-3PO: Cyclic-Three-Phase Optimization for Human-Robot Motion Retargeting based on Reinforcement Learning
Sep 26, 2019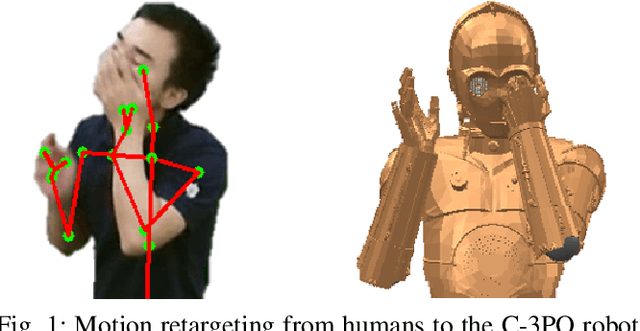
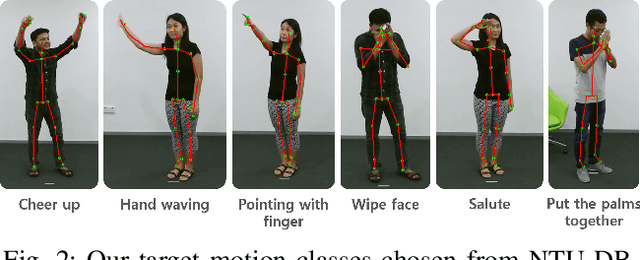
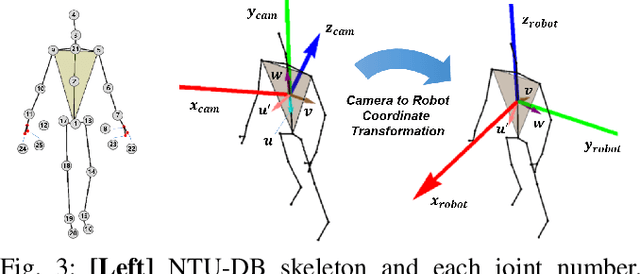
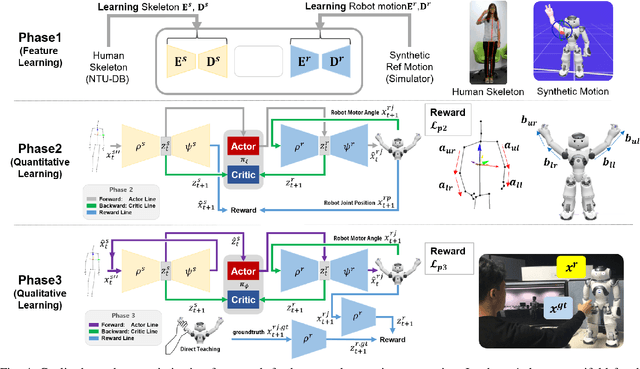
Motion retargeting between heterogeneous polymorphs with different sizes and kinematic configurations requires a comprehensive knowledge of kinematics and inverse kinematics. Moreover, it is non-trivial to provide a kinematic independent general solution. In this study, we developed a cyclic three-phase optimization method based on deep reinforcement learning for human-robot motion retargeting. The motion retargeting and reward calculations were performed using refined data in a latent space by the cyclic and filtering paths of our method. In addition, the human-in-the-loop based three-phase approach provides a framework for the improvement of the motion retargeting policy by both quantitative and qualitative manners. Using the proposed C-3PO method, we were successfully able to learn the motion retargeting skill between the human skeleton and the real NAO, Pepper, Baxter and C-3PO robot motions.