 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC-VSR: Spatially and Temporally Consistent Video Super-Resolution with Video Diffusion Prior
Feb 05, 2025Video super-resolution (VSR) aims to reconstruct a high-resolution (HR) video from a low-resolution (LR) counterpart. Achieving successful VSR requires producing realistic HR details and ensuring both spatial and temporal consistency. To restore realistic details, diffusion-based VSR approaches have recently been proposed. However, the inherent randomness of diffusion, combined with their tile-based approach, often leads to spatio-temporal inconsistencies. In this paper, we propose DC-VSR, a novel VSR approach to produce spatially and temporally consistent VSR results with realistic textures. To achieve spatial and temporal consistency, DC-VSR adopts a novel Spatial Attention Propagation (SAP) scheme and a Temporal Attention Propagation (TAP) scheme that propagate information across spatio-temporal tiles based on the self-attention mechanism. To enhance high-frequency details, we also introduce Detail-Suppression Self-Attention Guidance (DSSAG), a novel diffusion guidance scheme. Comprehensive experiments demonstrate that DC-VSR achieves spatially and temporally consistent, high-quality VSR results, outperforming previous approaches.
LayeringDiff: Layered Image Synthesis via Generation, then Disassembly with Generative Knowledge
Jan 02, 2025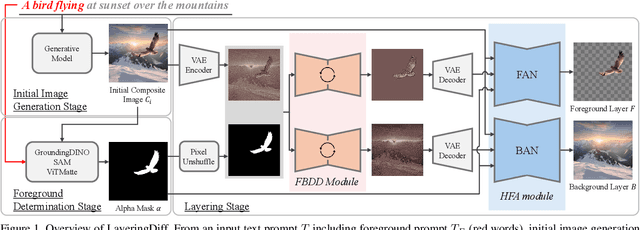

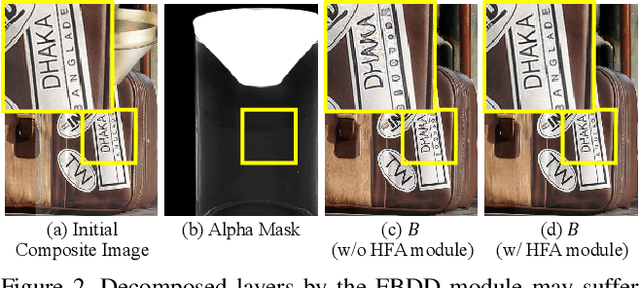

Layers have become indispensable tools for professional artists, allowing them to build a hierarchical structure that enables independent control over individual visual elements. In this paper, we propose LayeringDiff, a novel pipeline for the synthesis of layered images, which begins by generating a composite image using an off-the-shelf image generative model, followed by disassembling the image into its constituent foreground and background layers. By extracting layers from a composite image, rather than generating them from scratch, LayeringDiff bypasses the need for large-scale training to develop generative capabilities for individual layers. Furthermore, by utilizing a pretrained off-the-shelf generative model, our method can produce diverse contents and object scales in synthesized layers. For effective layer decomposition, we adapt a large-scale pretrained generative prior to estimate foreground and background layers. We also propose high-frequency alignment modules to refine the fine-details of the estimated layers. Our comprehensive experiments demonstrate that our approach effectively synthesizes layered images and supports various practical applications.
RNA: Video Editing with ROI-based Neural Atlas
Oct 10, 2024
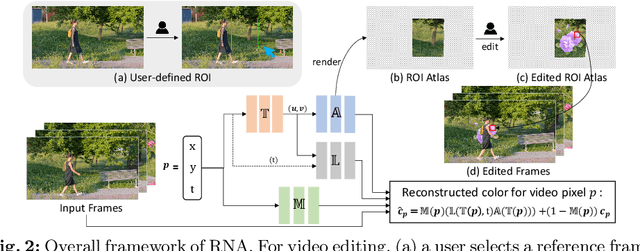


With the recent growth of video-based Social Network Service (SNS) platforms, the demand for video editing among common users has increased. However, video editing can be challenging due to the temporally-varying factors such as camera movement and moving objects. While modern atlas-based video editing methods have addressed these issues, they often fail to edit videos including complex motion or multiple moving objects, and demand excessive computational cost, even for very simple edits. In this paper, we propose a novel region-of-interest (ROI)-based video editing framework: ROI-based Neural Atlas (RNA). Unlike prior work, RNA allows users to specify editing regions, simplifying the editing process by removing the need for foreground separation and atlas modeling for foreground objects. However, this simplification presents a unique challenge: acquiring a mask that effectively handles occlusions in the edited area caused by moving objects, without relying on an additional segmentation model. To tackle this, we propose a novel mask refinement approach designed for this specific challenge. Moreover, we introduce a soft neural atlas model for video reconstruction to ensure high-quality editing results. Extensive experiments show that RNA offers a more practical and efficient editing solution, applicable to a wider range of videos with superior quality compared to prior methods.
Task-Oriented Diffusion Model Compression
Jan 31, 2024



As recent advancements in large-scale Text-to-Image (T2I) diffusion models have yielded remarkable high-quality image generation, diverse downstream Image-to-Image (I2I) applications have emerged. Despite the impressive results achieved by these I2I models, their practical utility is hampered by their large model size and the computational burden of the iterative denoising process. In this paper, we explore the compression potential of these I2I models in a task-oriented manner and introduce a novel method for reducing both model size and the number of timesteps. Through extensive experiments, we observe key insights and use our empirical knowledge to develop practical solutions that aim for near-optimal results with minimal exploration costs. We validate the effectiveness of our method by applying it to InstructPix2Pix for image editing and StableSR for image restoration. Our approach achieves satisfactory output quality with 39.2% and 56.4% reduction in model footprint and 81.4% and 68.7% decrease in latency to InstructPix2Pix and StableSR, respectively.
360$^\circ$ Reconstruction From a Single Image Using Space Carved Outpainting
Sep 19, 2023
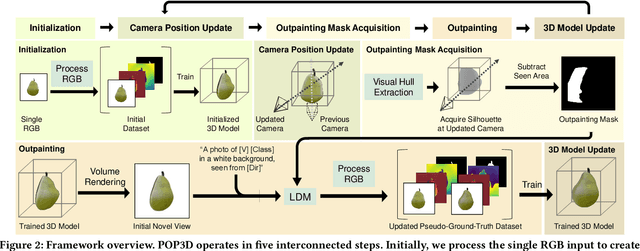

We introduce POP3D, a novel framework that creates a full $360^\circ$-view 3D model from a single image. POP3D resolves two prominent issues that limit the single-view reconstruction. Firstly, POP3D offers substantial generalizability to arbitrary categories, a trait that previous methods struggle to achieve. Secondly, POP3D further improves reconstruction fidelity and naturalness, a crucial aspect that concurrent works fall short of. Our approach marries the strengths of four primary components: (1) a monocular depth and normal predictor that serves to predict crucial geometric cues, (2) a space carving method capable of demarcating the potentially unseen portions of the target object, (3) a generative model pre-trained on a large-scale image dataset that can complete unseen regions of the target, and (4) a neural implicit surface reconstruction method tailored in reconstructing objects using RGB images along with monocular geometric cues. The combination of these components enables POP3D to readily generalize across various in-the-wild images and generate state-of-the-art reconstructions, outperforming similar works by a significant margin. Project page: \url{http://cg.postech.ac.kr/research/POP3D}
Dr.3D: Adapting 3D GANs to Artistic Drawings
Nov 30, 2022



While 3D GANs have recently demonstrated the high-quality synthesis of multi-view consistent images and 3D shapes, they are mainly restricted to photo-realistic human portraits. This paper aims to extend 3D GANs to a different, but meaningful visual form: artistic portrait drawings. However, extending existing 3D GANs to drawings is challenging due to the inevitable geometric ambiguity present in drawings. To tackle this, we present Dr.3D, a novel adaptation approach that adapts an existing 3D GAN to artistic drawings. Dr.3D is equipped with three novel components to handle the geometric ambiguity: a deformation-aware 3D synthesis network, an alternating adaptation of pose estimation and image synthesis, and geometric priors. Experiments show that our approach can successfully adapt 3D GANs to drawings and enable multi-view consistent semantic editing of drawings.
DynaGAN: Dynamic Few-shot Adaptation of GANs to Multiple Domains
Nov 26, 2022Few-shot domain adaptation to multiple domains aims to learn a complex image distribution across multiple domains from a few training images. A na\"ive solution here is to train a separate model for each domain using few-shot domain adaptation methods. Unfortunately, this approach mandates linearly-scaled computational resources both in memory and computation time and, more importantly, such separate models cannot exploit the shared knowledge between target domains. In this paper, we propose DynaGAN, a novel few-shot domain-adaptation method for multiple target domains. DynaGAN has an adaptation module, which is a hyper-network that dynamically adapts a pretrained GAN model into the multiple target domains. Hence, we can fully exploit the shared knowledge across target domains and avoid the linearly-scaled computational requirements. As it is still computationally challenging to adapt a large-size GAN model, we design our adaptation module light-weight using the rank-1 tensor decomposition. Lastly, we propose a contrastive-adaptation loss suitable for multi-domain few-shot adaptation. We validate the effectiveness of our method through extensive qualitative and quantitative evaluations.
BigColor: Colorization using a Generative Color Prior for Natural Images
Jul 20, 2022
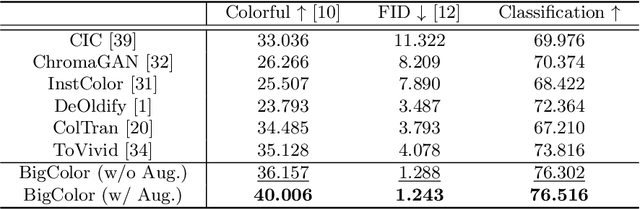
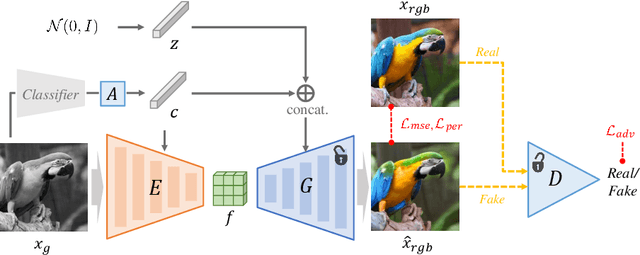
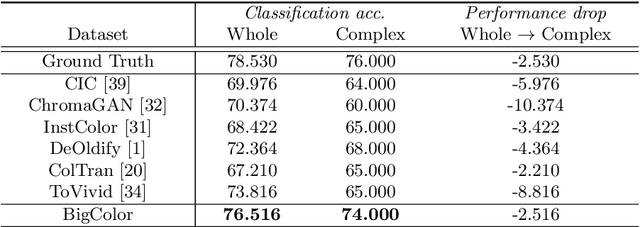
For realistic and vivid colorization, generative priors have recently been exploited. However, such generative priors often fail for in-the-wild complex images due to their limited representation space. In this paper, we propose BigColor, a novel colorization approach that provides vivid colorization for diverse in-the-wild images with complex structures. While previous generative priors are trained to synthesize both image structures and colors, we learn a generative color prior to focus on color synthesis given the spatial structure of an image. In this way, we reduce the burden of synthesizing image structures from the generative prior and expand its representation space to cover diverse images. To this end, we propose a BigGAN-inspired encoder-generator network that uses a spatial feature map instead of a spatially-flattened BigGAN latent code, resulting in an enlarged representation space. Our method enables robust colorization for diverse inputs in a single forward pass, supports arbitrary input resolutions, and provides multi-modal colorization results. We demonstrate that BigColor significantly outperforms existing methods especially on in-the-wild images with complex structures.
Realistic Blur Synthesis for Learning Image Deblurring
Feb 17, 2022
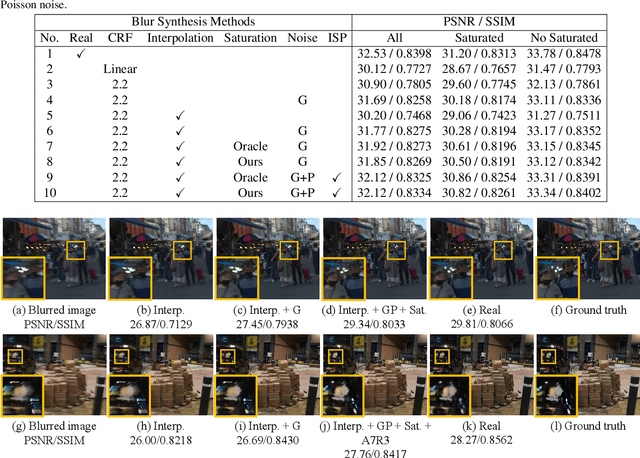
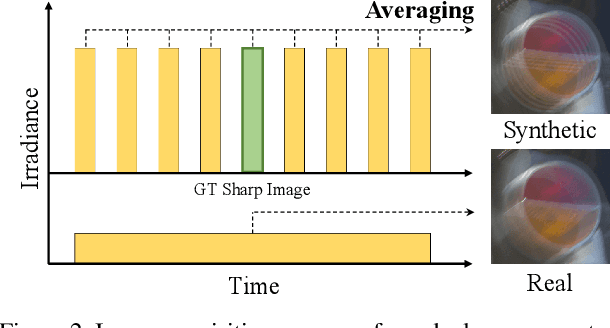

Training learning-based deblurring methods demands a significant amount of blurred and sharp image pairs. Unfortunately, existing synthetic datasets are not realistic enough, and existing real-world blur datasets provide limited diversity of scenes and camera settings. As a result, deblurring models trained on them still suffer from the lack of generalization ability for handling real blurred images. In this paper, we analyze various factors that introduce differences between real and synthetic blurred images, and present a novel blur synthesis pipeline that can synthesize more realistic blur. We also present RSBlur, a novel dataset that contains real blurred images and the corresponding sequences of sharp images. The RSBlur dataset can be used for generating synthetic blurred images to enable detailed analysis on the differences between real and synthetic blur. With our blur synthesis pipeline and RSBlur dataset, we reveal the effects of different factors in the blur synthesis. We also show that our synthesis method can improve the deblurring performance on real blurred images.