 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Geometric Regularization of Gaussian Splatting for Accurate Radiance Fields
Jun 16, 2025Recent methods, such as 2D Gaussian Splatting and Gaussian Opacity Fields, have aimed to address the geometric inaccuracies of 3D Gaussian Splatting while retaining its superior rendering quality. However, these approaches still struggle to reconstruct smooth and reliable geometry, particularly in scenes with significant color variation across viewpoints, due to their per-point appearance modeling and single-view optimization constraints. In this paper, we propose an effective multiview geometric regularization strategy that integrates multiview stereo (MVS) depth, RGB, and normal constraints into Gaussian Splatting initialization and optimization. Our key insight is the complementary relationship between MVS-derived depth points and Gaussian Splatting-optimized positions: MVS robustly estimates geometry in regions of high color variation through local patch-based matching and epipolar constraints, whereas Gaussian Splatting provides more reliable and less noisy depth estimates near object boundaries and regions with lower color variation. To leverage this insight, we introduce a median depth-based multiview relative depth loss with uncertainty estimation, effectively integrating MVS depth information into Gaussian Splatting optimization. We also propose an MVS-guided Gaussian Splatting initialization to avoid Gaussians falling into suboptimal positions. Extensive experiments validate that our approach successfully combines these strengths, enhancing both geometric accuracy and rendering quality across diverse indoor and outdoor scenes.
Deep Polycuboid Fitting for Compact 3D Representation of Indoor Scenes
Mar 19, 2025



This paper presents a novel framework for compactly representing a 3D indoor scene using a set of polycuboids through a deep learning-based fitting method. Indoor scenes mainly consist of man-made objects, such as furniture, which often exhibit rectilinear geometry. This property allows indoor scenes to be represented using combinations of polycuboids, providing a compact representation that benefits downstream applications like furniture rearrangement. Our framework takes a noisy point cloud as input and first detects six types of cuboid faces using a transformer network. Then, a graph neural network is used to validate the spatial relationships of the detected faces to form potential polycuboids. Finally, each polycuboid instance is reconstructed by forming a set of boxes based on the aggregated face labels. To train our networks, we introduce a synthetic dataset encompassing a diverse range of cuboid and polycuboid shapes that reflect the characteristics of indoor scenes. Our framework generalizes well to real-world indoor scene datasets, including Replica, ScanNet, and scenes captured with an iPhone. The versatility of our method is demonstrated through practical applications, such as virtual room tours and scene editing.
Realistic Blur Synthesis for Learning Image Deblurring
Feb 17, 2022
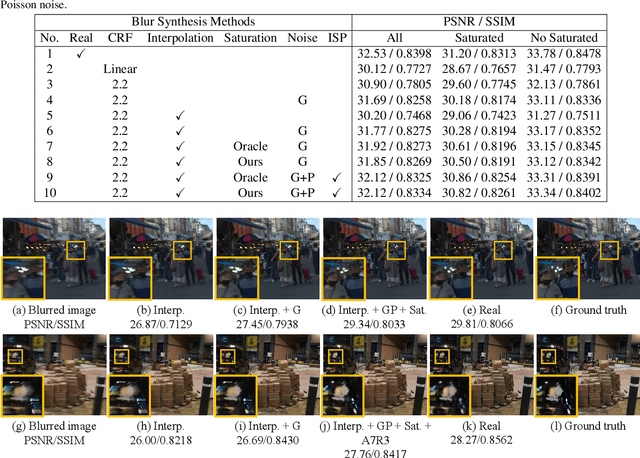
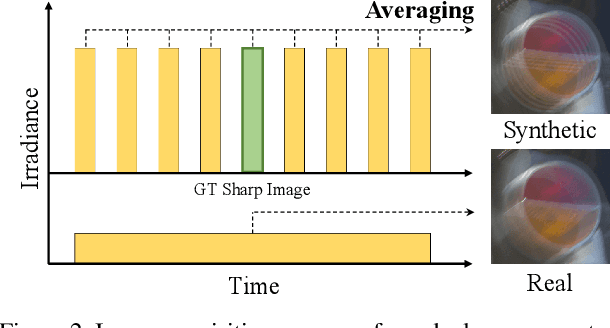

Training learning-based deblurring methods demands a significant amount of blurred and sharp image pairs. Unfortunately, existing synthetic datasets are not realistic enough, and existing real-world blur datasets provide limited diversity of scenes and camera settings. As a result, deblurring models trained on them still suffer from the lack of generalization ability for handling real blurred images. In this paper, we analyze various factors that introduce differences between real and synthetic blurred images, and present a novel blur synthesis pipeline that can synthesize more realistic blur. We also present RSBlur, a novel dataset that contains real blurred images and the corresponding sequences of sharp images. The RSBlur dataset can be used for generating synthetic blurred images to enable detailed analysis on the differences between real and synthetic blur. With our blur synthesis pipeline and RSBlur dataset, we reveal the effects of different factors in the blur synthesis. We also show that our synthesis method can improve the deblurring performance on real blurred images.
Spatiotemporal Texture Reconstruction for Dynamic Objects Using a Single RGB-D Camera
Aug 20, 2021This paper presents an effective method for generating a spatiotemporal (time-varying) texture map for a dynamic object using a single RGB-D camera. The input of our framework is a 3D template model and an RGB-D image sequence. Since there are invisible areas of the object at a frame in a single-camera setup, textures of such areas need to be borrowed from other frames. We formulate the problem as an MRF optimization and define cost functions to reconstruct a plausible spatiotemporal texture for a dynamic object. Experimental results demonstrate that our spatiotemporal textures can reproduce the active appearances of captured objects better than approaches using a single texture map.
Deep Virtual Markers for Articulated 3D Shapes
Aug 20, 2021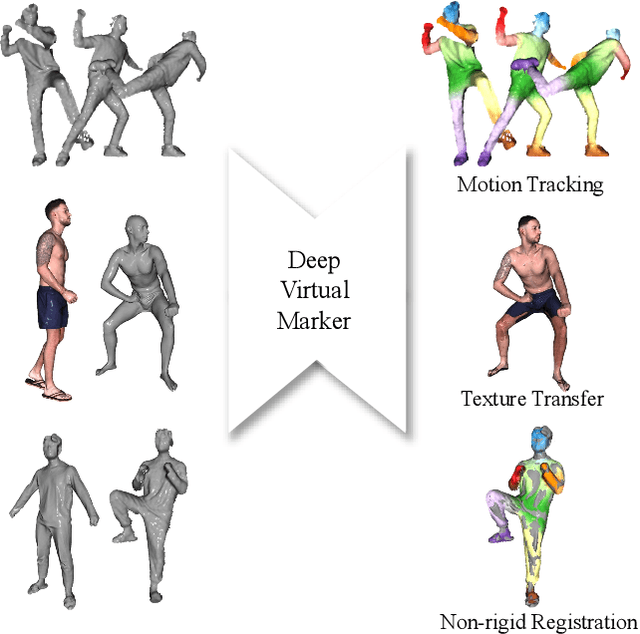
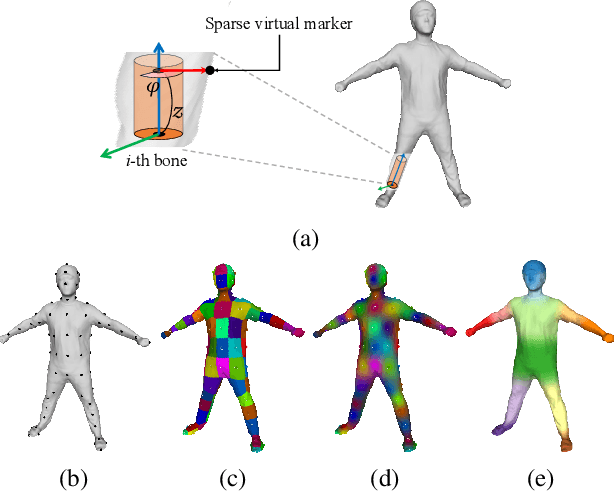
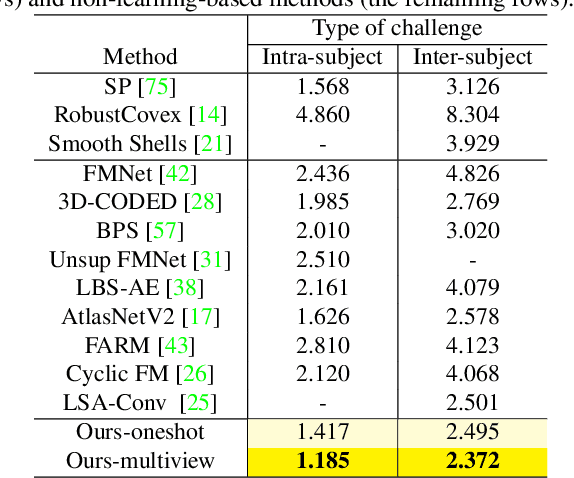
We propose deep virtual markers, a framework for estimating dense and accurate positional information for various types of 3D data. We design a concept and construct a framework that maps 3D points of 3D articulated models, like humans, into virtual marker labels. To realize the framework, we adopt a sparse convolutional neural network and classify 3D points of an articulated model into virtual marker labels. We propose to use soft labels for the classifier to learn rich and dense interclass relationships based on geodesic distance. To measure the localization accuracy of the virtual markers, we test FAUST challenge, and our result outperforms the state-of-the-art. We also observe outstanding performance on the generalizability test, unseen data evaluation, and different 3D data types (meshes and depth maps). We show additional applications using the estimated virtual markers, such as non-rigid registration, texture transfer, and realtime dense marker prediction from depth maps.