 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera Splatting for Continuous View Optimization
Sep 19, 2025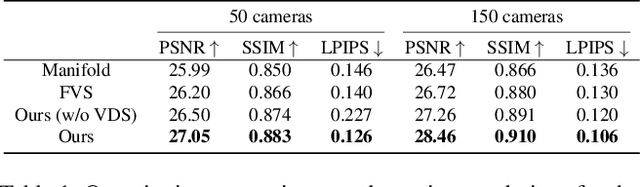
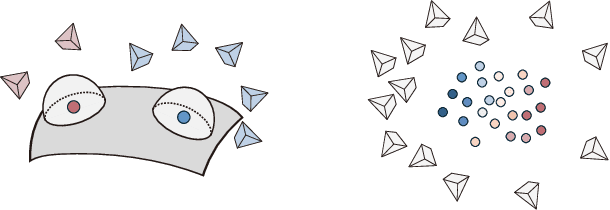
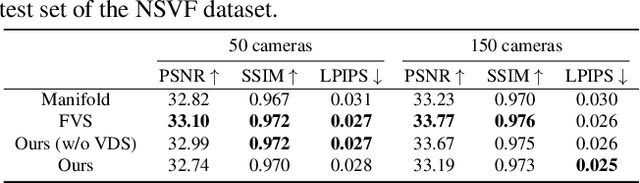
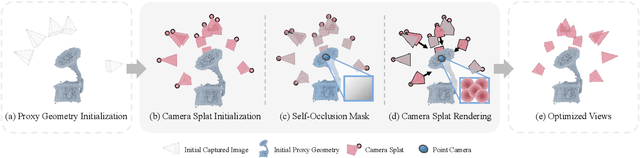
We propose Camera Splatting, a novel view optimization framework for novel view synthesis. Each camera is modeled as a 3D Gaussian, referred to as a camera splat, and virtual cameras, termed point cameras, are placed at 3D points sampled near the surface to observe the distribution of camera splats. View optimization is achieved by continuously and differentiably refining the camera splats so that desirable target distributions are observed from the point cameras, in a manner similar to the original 3D Gaussian splatting. Compared to the Farthest View Sampling (FVS) approach, our optimized views demonstrate superior performance in capturing complex view-dependent phenomena, including intense metallic reflections and intricate textures such as text.
Voost: A Unified and Scalable Diffusion Transformer for Bidirectional Virtual Try-On and Try-Off
Aug 06, 2025Virtual try-on aims to synthesize a realistic image of a person wearing a target garment, but accurately modeling garment-body correspondence remains a persistent challenge, especially under pose and appearance variation. In this paper, we propose Voost - a unified and scalable framework that jointly learns virtual try-on and try-off with a single diffusion transformer. By modeling both tasks jointly, Voost enables each garment-person pair to supervise both directions and supports flexible conditioning over generation direction and garment category, enhancing garment-body relational reasoning without task-specific networks, auxiliary losses, or additional labels. In addition, we introduce two inference-time techniques: attention temperature scaling for robustness to resolution or mask variation, and self-corrective sampling that leverages bidirectional consistency between tasks. Extensive experiments demonstrate that Voost achieves state-of-the-art results on both try-on and try-off benchmarks, consistently outperforming strong baselines in alignment accuracy, visual fidelity, and generalization.
Multiview Geometric Regularization of Gaussian Splatting for Accurate Radiance Fields
Jun 16, 2025Recent methods, such as 2D Gaussian Splatting and Gaussian Opacity Fields, have aimed to address the geometric inaccuracies of 3D Gaussian Splatting while retaining its superior rendering quality. However, these approaches still struggle to reconstruct smooth and reliable geometry, particularly in scenes with significant color variation across viewpoints, due to their per-point appearance modeling and single-view optimization constraints. In this paper, we propose an effective multiview geometric regularization strategy that integrates multiview stereo (MVS) depth, RGB, and normal constraints into Gaussian Splatting initialization and optimization. Our key insight is the complementary relationship between MVS-derived depth points and Gaussian Splatting-optimized positions: MVS robustly estimates geometry in regions of high color variation through local patch-based matching and epipolar constraints, whereas Gaussian Splatting provides more reliable and less noisy depth estimates near object boundaries and regions with lower color variation. To leverage this insight, we introduce a median depth-based multiview relative depth loss with uncertainty estimation, effectively integrating MVS depth information into Gaussian Splatting optimization. We also propose an MVS-guided Gaussian Splatting initialization to avoid Gaussians falling into suboptimal positions. Extensive experiments validate that our approach successfully combines these strengths, enhancing both geometric accuracy and rendering quality across diverse indoor and outdoor scenes.
HPU: High-Bandwidth Processing Unit for Scalable, Cost-effective LLM Inference via GPU Co-processing
Apr 18, 2025The attention layer, a core component of Transformer-based LLMs, brings out inefficiencies in current GPU systems due to its low operational intensity and the substantial memory requirements of KV caches. We propose a High-bandwidth Processing Unit (HPU), a memoryintensive co-processor that enhances GPU resource utilization during large-batched LLM inference. By offloading memory-bound operations, the HPU allows the GPU to focus on compute-intensive tasks, increasing overall efficiency. Also, the HPU, as an add-on card, scales out to accommodate surging memory demands driven by large batch sizes and extended sequence lengths. In this paper, we show the HPU prototype implemented with PCIe-based FPGA cards mounted on a GPU system. Our novel GPU-HPU heterogeneous system demonstrates up to 4.1x performance gains and 4.6x energy efficiency improvements over a GPUonly system, providing scalability without increasing the number of GPUs.
Deep Polycuboid Fitting for Compact 3D Representation of Indoor Scenes
Mar 19, 2025



This paper presents a novel framework for compactly representing a 3D indoor scene using a set of polycuboids through a deep learning-based fitting method. Indoor scenes mainly consist of man-made objects, such as furniture, which often exhibit rectilinear geometry. This property allows indoor scenes to be represented using combinations of polycuboids, providing a compact representation that benefits downstream applications like furniture rearrangement. Our framework takes a noisy point cloud as input and first detects six types of cuboid faces using a transformer network. Then, a graph neural network is used to validate the spatial relationships of the detected faces to form potential polycuboids. Finally, each polycuboid instance is reconstructed by forming a set of boxes based on the aggregated face labels. To train our networks, we introduce a synthetic dataset encompassing a diverse range of cuboid and polycuboid shapes that reflect the characteristics of indoor scenes. Our framework generalizes well to real-world indoor scene datasets, including Replica, ScanNet, and scenes captured with an iPhone. The versatility of our method is demonstrated through practical applications, such as virtual room tours and scene editing.
Gyro-based Neural Single Image Deblurring
Apr 08, 2024



In this paper, we present GyroDeblurNet, a novel single image deblurring method that utilizes a gyro sensor to effectively resolve the ill-posedness of image deblurring. The gyro sensor provides valuable information about camera motion during exposure time that can significantly improve deblurring quality. However, effectively exploiting real-world gyro data is challenging due to significant errors from various sources including sensor noise, the disparity between the positions of a camera module and a gyro sensor, the absence of translational motion information, and moving objects whose motions cannot be captured by a gyro sensor. To handle gyro error, GyroDeblurNet is equipped with two novel neural network blocks: a gyro refinement block and a gyro deblurring block. The gyro refinement block refines the error-ridden gyro data using the blur information from the input image. On the other hand, the gyro deblurring block removes blur from the input image using the refined gyro data and further compensates for gyro error by leveraging the blur information from the input image. For training a neural network with erroneous gyro data, we propose a training strategy based on the curriculum learning. We also introduce a novel gyro data embedding scheme to represent real-world intricate camera shakes. Finally, we present a synthetic dataset and a real dataset for the training and evaluation of gyro-based single image deblurring. Our experiments demonstrate that our approach achieves state-of-the-art deblurring quality by effectively utilizing erroneous gyro data.
Discontinuity-preserving Normal Integration with Auxiliary Edges
Apr 04, 2024Many surface reconstruction methods incorporate normal integration, which is a process to obtain a depth map from surface gradients. In this process, the input may represent a surface with discontinuities, e.g., due to self-occlusion. To reconstruct an accurate depth map from the input normal map, hidden surface gradients occurring from the jumps must be handled. To model these jumps correctly, we design a novel discretization scheme for the domain of normal integration. Our key idea is to introduce auxiliary edges, which bridge between piecewise-smooth patches in the domain so that the magnitude of hidden jumps can be explicitly expressed. Using the auxiliary edges, we design a novel algorithm to optimize the discontinuity and the depth map from the input normal map. Our method optimizes discontinuities by using a combination of iterative re-weighted least squares and iterative filtering of the jump magnitudes on auxiliary edges to provide strong sparsity regularization. Compared to previous discontinuity-preserving normal integration methods, which model the magnitudes of jumps only implicitly, our method reconstructs subtle discontinuities accurately thanks to our explicit representation of jumps allowing for strong sparsity regularization.
Fashion Style Editing with Generative Human Prior
Apr 02, 2024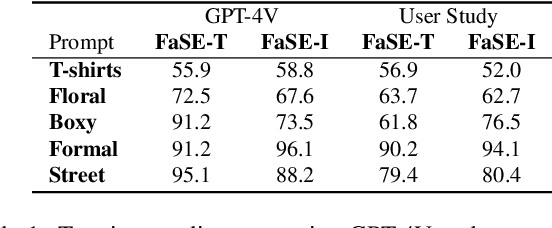
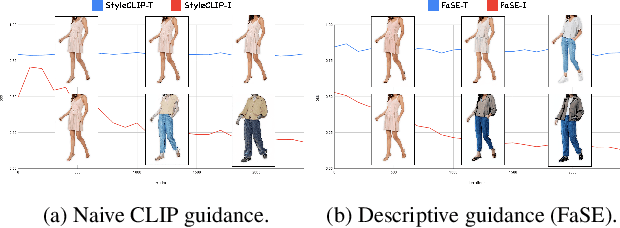
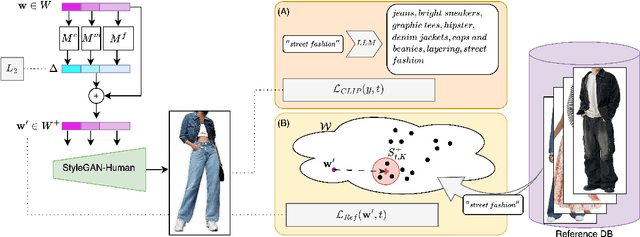
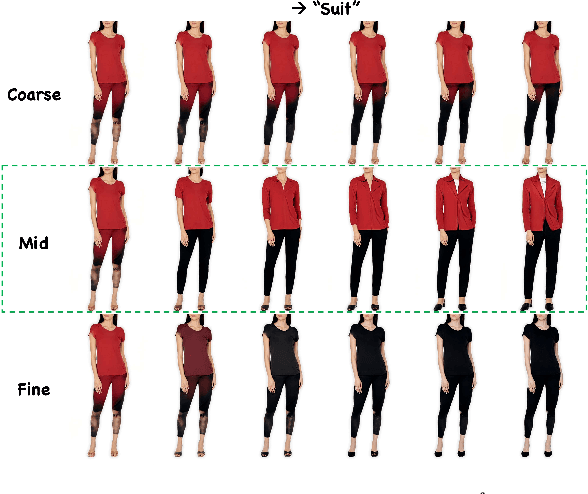
Image editing has been a long-standing challenge in the research community with its far-reaching impact on numerous applications. Recently, text-driven methods started to deliver promising results in domains like human faces, but their applications to more complex domains have been relatively limited. In this work, we explore the task of fashion style editing, where we aim to manipulate the fashion style of human imagery using text descriptions. Specifically, we leverage a generative human prior and achieve fashion style editing by navigating its learned latent space. We first verify that the existing text-driven editing methods fall short for our problem due to their overly simplified guidance signal, and propose two directions to reinforce the guidance: textual augmentation and visual referencing. Combined with our empirical findings on the latent space structure, our Fashion Style Editing framework (FaSE) successfully projects abstract fashion concepts onto human images and introduces exciting new applications to the field.
ParamISP: Learned Forward and Inverse ISPs using Camera Parameters
Dec 20, 2023



RAW images are rarely shared mainly due to its excessive data size compared to their sRGB counterparts obtained by camera ISPs. Learning the forward and inverse processes of camera ISPs has been recently demonstrated, enabling physically-meaningful RAW-level image processing on input sRGB images. However, existing learning-based ISP methods fail to handle the large variations in the ISP processes with respect to camera parameters such as ISO and exposure time, and have limitations when used for various applications. In this paper, we propose ParamISP, a learning-based method for forward and inverse conversion between sRGB and RAW images, that adopts a novel neural-network module to utilize camera parameters, which is dubbed as ParamNet. Given the camera parameters provided in the EXIF data, ParamNet converts them into a feature vector to control the ISP networks. Extensive experiments demonstrate that ParamISP achieve superior RAW and sRGB reconstruction results compared to previous methods and it can be effectively used for a variety of applications such as deblurring dataset synthesis, raw deblurring, HDR reconstruction, and camera-to-camera transfer.
Mesh Density Adaptation for Template-based Shape Reconstruction
Jul 30, 2023In 3D shape reconstruction based on template mesh deformation, a regularization, such as smoothness energy, is employed to guide the reconstruction into a desirable direction. In this paper, we highlight an often overlooked property in the regularization: the vertex density in the mesh. Without careful control on the density, the reconstruction may suffer from under-sampling of vertices near shape details. We propose a novel mesh density adaptation method to resolve the under-sampling problem. Our mesh density adaptation energy increases the density of vertices near complex structures via deformation to help reconstruction of shape details. We demonstrate the usability and performance of mesh density adaptation with two tasks, inverse rendering and non-rigid surface registration. Our method produces more accurate reconstruction results compared to the cases without mesh density adaptation.