 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashion Style Editing with Generative Human Prior
Paper and Code
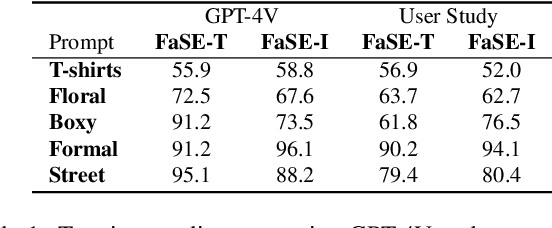
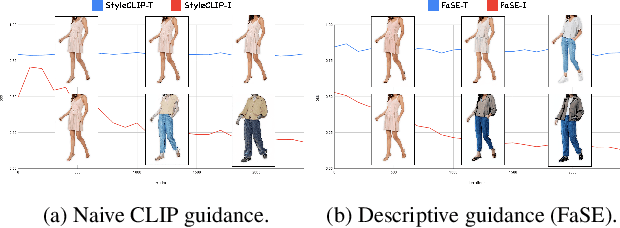
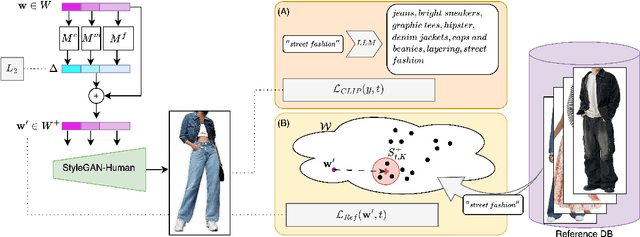
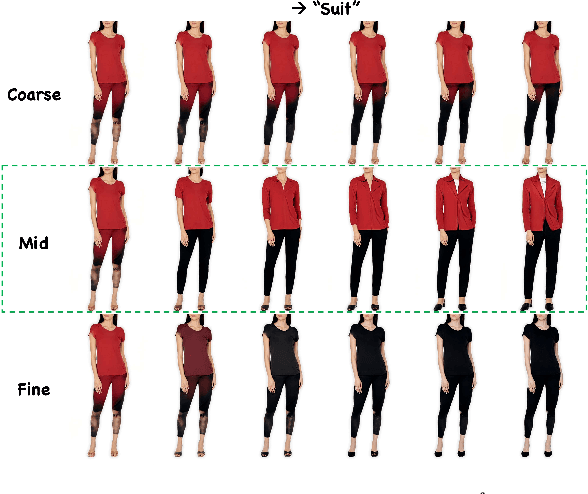
Image editing has been a long-standing challenge in the research community with its far-reaching impact on numerous applications. Recently, text-driven methods started to deliver promising results in domains like human faces, but their applications to more complex domains have been relatively limited. In this work, we explore the task of fashion style editing, where we aim to manipulate the fashion style of human imagery using text descriptions. Specifically, we leverage a generative human prior and achieve fashion style editing by navigating its learned latent space. We first verify that the existing text-driven editing methods fall short for our problem due to their overly simplified guidance signal, and propose two directions to reinforce the guidance: textual augmentation and visual referencing. Combined with our empirical findings on the latent space structure, our Fashion Style Editing framework (FaSE) successfully projects abstract fashion concepts onto human images and introduces exciting new applications to the field.