 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC-VSR: Spatially and Temporally Consistent Video Super-Resolution with Video Diffusion Prior
Feb 05, 2025Video super-resolution (VSR) aims to reconstruct a high-resolution (HR) video from a low-resolution (LR) counterpart. Achieving successful VSR requires producing realistic HR details and ensuring both spatial and temporal consistency. To restore realistic details, diffusion-based VSR approaches have recently been proposed. However, the inherent randomness of diffusion, combined with their tile-based approach, often leads to spatio-temporal inconsistencies. In this paper, we propose DC-VSR, a novel VSR approach to produce spatially and temporally consistent VSR results with realistic textures. To achieve spatial and temporal consistency, DC-VSR adopts a novel Spatial Attention Propagation (SAP) scheme and a Temporal Attention Propagation (TAP) scheme that propagate information across spatio-temporal tiles based on the self-attention mechanism. To enhance high-frequency details, we also introduce Detail-Suppression Self-Attention Guidance (DSSAG), a novel diffusion guidance scheme. Comprehensive experiments demonstrate that DC-VSR achieves spatially and temporally consistent, high-quality VSR results, outperforming previous approaches.
LayeringDiff: Layered Image Synthesis via Generation, then Disassembly with Generative Knowledge
Jan 02, 2025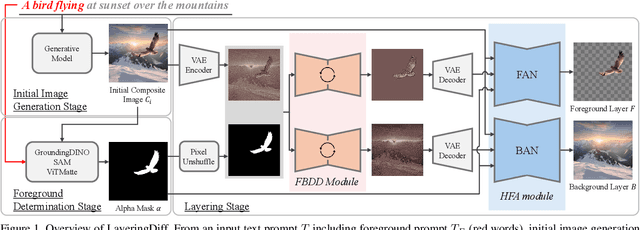

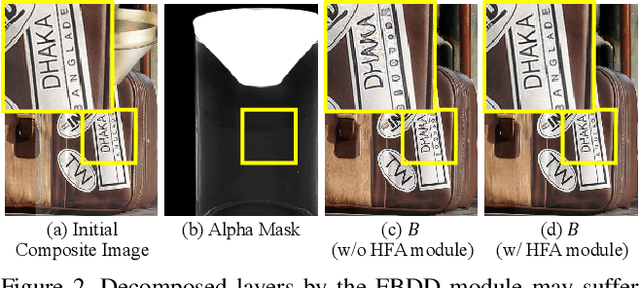

Layers have become indispensable tools for professional artists, allowing them to build a hierarchical structure that enables independent control over individual visual elements. In this paper, we propose LayeringDiff, a novel pipeline for the synthesis of layered images, which begins by generating a composite image using an off-the-shelf image generative model, followed by disassembling the image into its constituent foreground and background layers. By extracting layers from a composite image, rather than generating them from scratch, LayeringDiff bypasses the need for large-scale training to develop generative capabilities for individual layers. Furthermore, by utilizing a pretrained off-the-shelf generative model, our method can produce diverse contents and object scales in synthesized layers. For effective layer decomposition, we adapt a large-scale pretrained generative prior to estimate foreground and background layers. We also propose high-frequency alignment modules to refine the fine-details of the estimated layers. Our comprehensive experiments demonstrate that our approach effectively synthesizes layered images and supports various practical applications.