 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaHOP: Fast and Accurate Low-Precision Training via Outlier-Pattern-Aware Rotation
Apr 02, 2026Low-precision training (LPT) commonly employs Hadamard transforms to suppress outliers and mitigate quantization error in large language models (LLMs). However, prior methods apply a fixed transform uniformly, despite substantial variation in outlier structures across tensors. Through the first systematic study of outlier patterns across weights, activations, and gradients of LLMs, we show that this strategy is fundamentally flawed: the effectiveness of Hadamard-based suppression depends on how the transform's smoothing direction aligns with the outlier structure of each operand -- a property that varies substantially across layers and computation paths. We characterize these patterns into three types: Row-wise, Column-wise, and None. Each pair requires a tailored transform direction or outlier handling strategy to minimize quantization error. Based on this insight, we propose AdaHOP (Adaptive Hadamard transform with Outlier-Pattern-aware strategy), which assigns each matrix multiplication its optimal strategy: Inner Hadamard Transform (IHT) where inner-dimension smoothing is effective, or IHT combined with selective Outlier Extraction (OE) -- routing dominant outliers to a high-precision path -- where it is not. Combined with hardware-aware Triton kernels, AdaHOP achieves BF16 training quality at MXFP4 precision while delivering up to 3.6X memory compression and 1.8X kernel acceleration} over BF16 full-precision training.
Stabilizing Direct Training of Spiking Neural Networks: Membrane Potential Initialization and Threshold-robust Surrogate Gradient
Nov 11, 2025


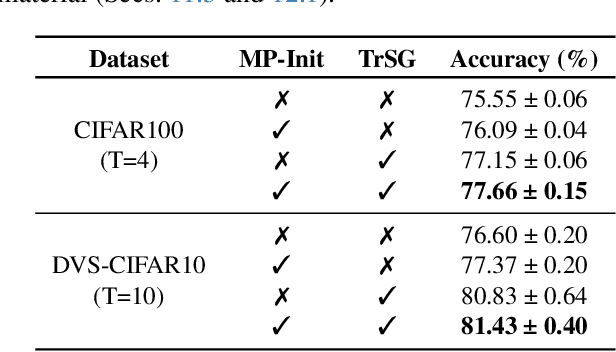
Recent advancements in the direct training of Spiking Neural Networks (SNNs) have demonstrated high-quality outputs even at early timesteps, paving the way for novel energy-efficient AI paradigms. However, the inherent non-linearity and temporal dependencies in SNNs introduce persistent challenges, such as temporal covariate shift (TCS) and unstable gradient flow with learnable neuron thresholds. In this paper, we present two key innovations: MP-Init (Membrane Potential Initialization) and TrSG (Threshold-robust Surrogate Gradient). MP-Init addresses TCS by aligning the initial membrane potential with its stationary distribution, while TrSG stabilizes gradient flow with respect to threshold voltage during training. Extensive experiments validate our approach, achieving state-of-the-art accuracy on both static and dynamic image datasets. The code is available at: https://github.com/kookhh0827/SNN-MP-Init-TRSG
Improving Generative Behavior Cloning via Self-Guidance and Adaptive Chunking
Oct 14, 2025Generative Behavior Cloning (GBC) is a simple yet effective framework for robot learning, particularly in multi-task settings. Recent GBC methods often employ diffusion policies with open-loop (OL) control, where actions are generated via a diffusion process and executed in multi-step chunks without replanning. While this approach has demonstrated strong success rates and generalization, its inherent stochasticity can result in erroneous action sampling, occasionally leading to unexpected task failures. Moreover, OL control suffers from delayed responses, which can degrade performance in noisy or dynamic environments. To address these limitations, we propose two novel techniques to enhance the consistency and reactivity of diffusion policies: (1) self-guidance, which improves action fidelity by leveraging past observations and implicitly promoting future-aware behavior; and (2) adaptive chunking, which selectively updates action sequences when the benefits of reactivity outweigh the need for temporal consistency. Extensive experiments show that our approach substantially improves GBC performance across a wide range of simulated and real-world robotic manipulation tasks. Our code is available at https://github.com/junhyukso/SGAC
Grouped Speculative Decoding for Autoregressive Image Generation
Aug 11, 2025Recently, autoregressive (AR) image models have demonstrated remarkable generative capabilities, positioning themselves as a compelling alternative to diffusion models. However, their sequential nature leads to long inference times, limiting their practical scalability. In this work, we introduce Grouped Speculative Decoding (GSD), a novel, training-free acceleration method for AR image models. While recent studies have explored Speculative Decoding (SD) as a means to speed up AR image generation, existing approaches either provide only modest acceleration or require additional training. Our in-depth analysis reveals a fundamental difference between language and image tokens: image tokens exhibit inherent redundancy and diversity, meaning multiple tokens can convey valid semantics. However, traditional SD methods are designed to accept only a single most-likely token, which fails to leverage this difference, leading to excessive false-negative rejections. To address this, we propose a new SD strategy that evaluates clusters of visually valid tokens rather than relying on a single target token. Additionally, we observe that static clustering based on embedding distance is ineffective, which motivates our dynamic GSD approach. Extensive experiments show that GSD accelerates AR image models by an average of 3.7x while preserving image quality-all without requiring any additional training. The source code is available at https://github.com/junhyukso/GSD
Déjà Vu: Efficient Video-Language Query Engine with Learning-based Inter-Frame Computation Reuse
Jun 17, 2025Recently, Video-Language Models (VideoLMs) have demonstrated remarkable capabilities, offering significant potential for flexible and powerful video query systems. These models typically rely on Vision Transformers (ViTs), which process video frames individually to extract visual embeddings. However, generating embeddings for large-scale videos requires ViT inferencing across numerous frames, posing a major hurdle to real-world deployment and necessitating solutions for integration into scalable video data management systems. This paper introduces D\'ej\`a Vu, a video-language query engine that accelerates ViT-based VideoLMs by reusing computations across consecutive frames. At its core is ReuseViT, a modified ViT model specifically designed for VideoLM tasks, which learns to detect inter-frame reuse opportunities, striking an effective balance between accuracy and reuse. Although ReuseViT significantly reduces computation, these savings do not directly translate into performance gains on GPUs. To overcome this, D\'ej\`a Vu integrates memory-compute joint compaction techniques that convert the FLOP savings into tangible performance gains. Evaluations on three VideoLM tasks show that D\'ej\`a Vu accelerates embedding generation by up to a 2.64x within a 2% error bound, dramatically enhancing the practicality of VideoLMs for large-scale video analytics.
The Oversmoothing Fallacy: A Misguided Narrative in GNN Research
Jun 05, 2025Oversmoothing has been recognized as a main obstacle to building deep Graph Neural Networks (GNNs), limiting the performance. This position paper argues that the influence of oversmoothing has been overstated and advocates for a further exploration of deep GNN architectures. Given the three core operations of GNNs, aggregation, linear transformation, and non-linear activation, we show that prior studies have mistakenly confused oversmoothing with the vanishing gradient, caused by transformation and activation rather than aggregation. Our finding challenges prior beliefs about oversmoothing being unique to GNNs. Furthermore, we demonstrate that classical solutions such as skip connections and normalization enable the successful stacking of deep GNN layers without performance degradation. Our results clarify misconceptions about oversmoothing and shed new light on the potential of deep GNNs.
Merge-Friendly Post-Training Quantization for Multi-Target Domain Adaptation
May 29, 2025Model merging has emerged as a powerful technique for combining task-specific weights, achieving superior performance in multi-target domain adaptation. However, when applied to practical scenarios, such as quantized models, new challenges arise. In practical scenarios, quantization is often applied to target-specific data, but this process restricts the domain of interest and introduces discretization effects, making model merging highly non-trivial. In this study, we analyze the impact of quantization on model merging through the lens of error barriers. Leveraging these insights, we propose a novel post-training quantization, HDRQ - Hessian and distant regularizing quantization - that is designed to consider model merging for multi-target domain adaptation. Our approach ensures that the quantization process incurs minimal deviation from the source pre-trained model while flattening the loss surface to facilitate smooth model merging. To our knowledge, this is the first study on this challenge, and extensive experiments confirm its effectiveness.
GraLoRA: Granular Low-Rank Adaptation for Parameter-Efficient Fine-Tuning
May 26, 2025Low-Rank Adaptation (LoRA) is a popular method for parameter-efficient fine-tuning (PEFT) of generative models, valued for its simplicity and effectiveness. Despite recent enhancements, LoRA still suffers from a fundamental limitation: overfitting when the bottleneck is widened. It performs best at ranks 32-64, yet its accuracy stagnates or declines at higher ranks, still falling short of full fine-tuning (FFT) performance. We identify the root cause as LoRA's structural bottleneck, which introduces gradient entanglement to the unrelated input channels and distorts gradient propagation. To address this, we introduce a novel structure, Granular Low-Rank Adaptation (GraLoRA) that partitions weight matrices into sub-blocks, each with its own low-rank adapter. With negligible computational or storage cost, GraLoRA overcomes LoRA's limitations, effectively increases the representational capacity, and more closely approximates FFT behavior. Experiments on code generation and commonsense reasoning benchmarks show that GraLoRA consistently outperforms LoRA and other baselines, achieving up to +8.5% absolute gain in Pass@1 on HumanEval+. These improvements hold across model sizes and rank settings, making GraLoRA a scalable and robust solution for PEFT. Code, data, and scripts are available at https://github.com/SqueezeBits/GraLoRA.git
HOT: Hadamard-based Optimized Training
Mar 27, 2025It has become increasingly important to optimize backpropagation to reduce memory usage and computational overhead. Achieving this goal is highly challenging, as multiple objectives must be considered jointly while maintaining training quality. In this paper, we focus on matrix multiplication, which accounts for the largest portion of training costs, and analyze its backpropagation in detail to identify lightweight techniques that offer the best benefits. Based on this analysis, we introduce a novel method, Hadamard-based Optimized Training (HOT). In this approach, we apply Hadamard-based optimizations, such as Hadamard quantization and Hadamard low-rank approximation, selectively and with awareness of the suitability of each optimization for different backward paths. Additionally, we introduce two enhancements: activation buffer compression and layer-wise quantizer selection. Our extensive analysis shows that HOT achieves up to 75% memory savings and a 2.6 times acceleration on real GPUs, with negligible accuracy loss compared to FP32 precision.
PCM : Picard Consistency Model for Fast Parallel Sampling of Diffusion Models
Mar 25, 2025



Recently, diffusion models have achieved significant advances in vision, text, and robotics. However, they still face slow generation speeds due to sequential denoising processes. To address this, a parallel sampling method based on Picard iteration was introduced, effectively reducing sequential steps while ensuring exact convergence to the original output. Nonetheless, Picard iteration does not guarantee faster convergence, which can still result in slow generation in practice. In this work, we propose a new parallelization scheme, the Picard Consistency Model (PCM), which significantly reduces the number of generation steps in Picard iteration. Inspired by the consistency model, PCM is directly trained to predict the fixed-point solution, or the final output, at any stage of the convergence trajectory. Additionally, we introduce a new concept called model switching, which addresses PCM's limitations and ensures exact convergence. Extensive experiments demonstrate that PCM achieves up to a 2.71x speedup over sequential sampling and a 1.77x speedup over Picard iteration across various tasks, including image generation and robotic control.