 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrouped Speculative Decoding for Autoregressive Image Generation
Aug 11, 2025Recently, autoregressive (AR) image models have demonstrated remarkable generative capabilities, positioning themselves as a compelling alternative to diffusion models. However, their sequential nature leads to long inference times, limiting their practical scalability. In this work, we introduce Grouped Speculative Decoding (GSD), a novel, training-free acceleration method for AR image models. While recent studies have explored Speculative Decoding (SD) as a means to speed up AR image generation, existing approaches either provide only modest acceleration or require additional training. Our in-depth analysis reveals a fundamental difference between language and image tokens: image tokens exhibit inherent redundancy and diversity, meaning multiple tokens can convey valid semantics. However, traditional SD methods are designed to accept only a single most-likely token, which fails to leverage this difference, leading to excessive false-negative rejections. To address this, we propose a new SD strategy that evaluates clusters of visually valid tokens rather than relying on a single target token. Additionally, we observe that static clustering based on embedding distance is ineffective, which motivates our dynamic GSD approach. Extensive experiments show that GSD accelerates AR image models by an average of 3.7x while preserving image quality-all without requiring any additional training. The source code is available at https://github.com/junhyukso/GSD
Merge-Friendly Post-Training Quantization for Multi-Target Domain Adaptation
May 29, 2025Model merging has emerged as a powerful technique for combining task-specific weights, achieving superior performance in multi-target domain adaptation. However, when applied to practical scenarios, such as quantized models, new challenges arise. In practical scenarios, quantization is often applied to target-specific data, but this process restricts the domain of interest and introduces discretization effects, making model merging highly non-trivial. In this study, we analyze the impact of quantization on model merging through the lens of error barriers. Leveraging these insights, we propose a novel post-training quantization, HDRQ - Hessian and distant regularizing quantization - that is designed to consider model merging for multi-target domain adaptation. Our approach ensures that the quantization process incurs minimal deviation from the source pre-trained model while flattening the loss surface to facilitate smooth model merging. To our knowledge, this is the first study on this challenge, and extensive experiments confirm its effectiveness.
HOT: Hadamard-based Optimized Training
Mar 27, 2025It has become increasingly important to optimize backpropagation to reduce memory usage and computational overhead. Achieving this goal is highly challenging, as multiple objectives must be considered jointly while maintaining training quality. In this paper, we focus on matrix multiplication, which accounts for the largest portion of training costs, and analyze its backpropagation in detail to identify lightweight techniques that offer the best benefits. Based on this analysis, we introduce a novel method, Hadamard-based Optimized Training (HOT). In this approach, we apply Hadamard-based optimizations, such as Hadamard quantization and Hadamard low-rank approximation, selectively and with awareness of the suitability of each optimization for different backward paths. Additionally, we introduce two enhancements: activation buffer compression and layer-wise quantizer selection. Our extensive analysis shows that HOT achieves up to 75% memory savings and a 2.6 times acceleration on real GPUs, with negligible accuracy loss compared to FP32 precision.
NIPQ: Noise Injection Pseudo Quantization for Automated DNN Optimization
Jun 02, 2022
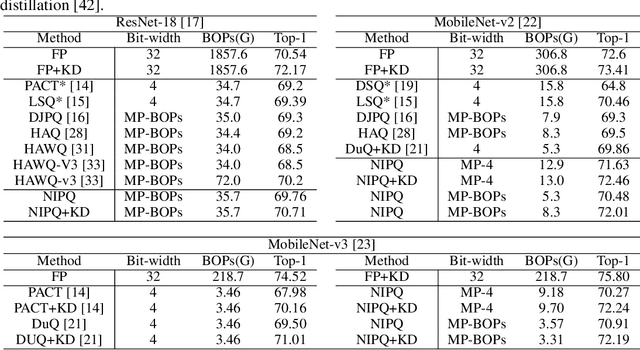
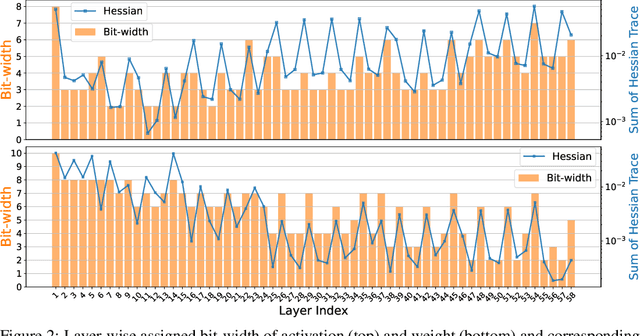

The optimization of neural networks in terms of computation cost and memory footprint is crucial for their practical deployment on edge devices. In this work, we propose a novel quantization-aware training (QAT) scheme called noise injection pseudo quantization (NIPQ). NIPQ is implemented based on pseudo quantization noise (PQN) and has several advantages. First, both activation and weight can be quantized based on a unified framework. Second, the hyper-parameters of quantization (e.g., layer-wise bit-width and quantization interval) are automatically tuned. Third, after QAT, the network has robustness against quantization, thereby making it easier to deploy in practice. To validate the superiority of the proposed algorithm, we provide extensive analysis and conduct diverse experiments for various vision applications. Our comprehensive experiments validate the outstanding performance of the proposed algorithm in several aspects.