 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCM : Picard Consistency Model for Fast Parallel Sampling of Diffusion Models
Mar 25, 2025Recently, diffusion models have achieved significant advances in vision, text, and robotics. However, they still face slow generation speeds due to sequential denoising processes. To address this, a parallel sampling method based on Picard iteration was introduced, effectively reducing sequential steps while ensuring exact convergence to the original output. Nonetheless, Picard iteration does not guarantee faster convergence, which can still result in slow generation in practice. In this work, we propose a new parallelization scheme, the Picard Consistency Model (PCM), which significantly reduces the number of generation steps in Picard iteration. Inspired by the consistency model, PCM is directly trained to predict the fixed-point solution, or the final output, at any stage of the convergence trajectory. Additionally, we introduce a new concept called model switching, which addresses PCM's limitations and ensures exact convergence. Extensive experiments demonstrate that PCM achieves up to a 2.71x speedup over sequential sampling and a 1.77x speedup over Picard iteration across various tasks, including image generation and robotic control.
FRDiff: Feature Reuse for Exquisite Zero-shot Acceleration of Diffusion Models
Dec 06, 2023The substantial computational costs of diffusion models, particularly due to the repeated denoising steps crucial for high-quality image generation, present a major obstacle to their widespread adoption. While several studies have attempted to address this issue by reducing the number of score function evaluations using advanced ODE solvers without fine-tuning, the decreased number of denoising iterations misses the opportunity to update fine details, resulting in noticeable quality degradation. In our work, we introduce an advanced acceleration technique that leverages the temporal redundancy inherent in diffusion models. Reusing feature maps with high temporal similarity opens up a new opportunity to save computation without sacrificing output quality. To realize the practical benefits of this intuition, we conduct an extensive analysis and propose a novel method, FRDiff. FRDiff is designed to harness the advantages of both reduced NFE and feature reuse, achieving a Pareto frontier that balances fidelity and latency trade-offs in various generative tasks.
Temporal Dynamic Quantization for Diffusion Models
Jun 04, 2023The diffusion model has gained popularity in vision applications due to its remarkable generative performance and versatility. However, high storage and computation demands, resulting from the model size and iterative generation, hinder its use on mobile devices. Existing quantization techniques struggle to maintain performance even in 8-bit precision due to the diffusion model's unique property of temporal variation in activation. We introduce a novel quantization method that dynamically adjusts the quantization interval based on time step information, significantly improving output quality. Unlike conventional dynamic quantization techniques, our approach has no computational overhead during inference and is compatible with both post-training quantization (PTQ) and quantization-aware training (QAT). Our extensive experiments demonstrate substantial improvements in output quality with the quantized diffusion model across various datasets.
Learning Fair Representation via Distributional Contrastive Disentanglement
Jun 17, 2022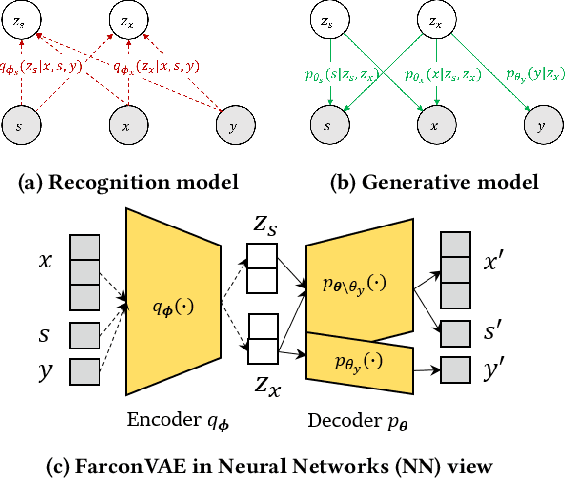
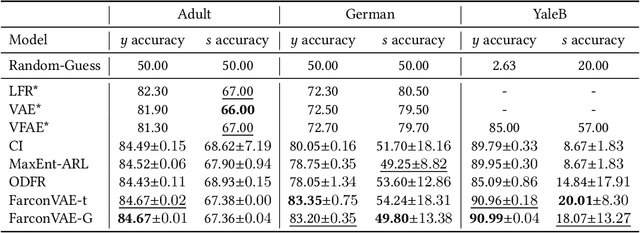
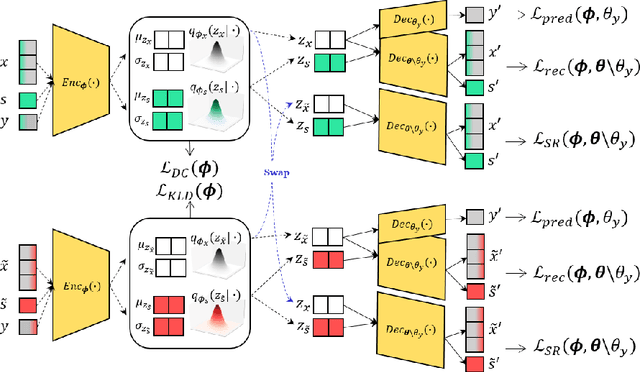
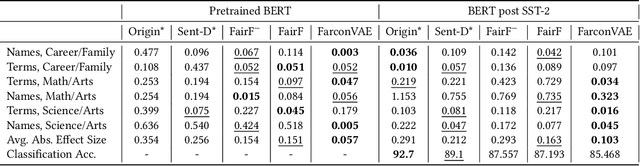
Learning fair representation is crucial for achieving fairness or debiasing sensitive information. Most existing works rely on adversarial representation learning to inject some invariance into representation. However, adversarial learning methods are known to suffer from relatively unstable training, and this might harm the balance between fairness and predictiveness of representation. We propose a new approach, learning FAir Representation via distributional CONtrastive Variational AutoEncoder (FarconVAE), which induces the latent space to be disentangled into sensitive and nonsensitive parts. We first construct the pair of observations with different sensitive attributes but with the same labels. Then, FarconVAE enforces each non-sensitive latent to be closer, while sensitive latents to be far from each other and also far from the non-sensitive latent by contrasting their distributions. We provide a new type of contrastive loss motivated by Gaussian and Student-t kernels for distributional contrastive learning with theoretical analysis. Besides, we adopt a new swap-reconstruction loss to boost the disentanglement further. FarconVAE shows superior performance on fairness, pretrained model debiasing, and domain generalization tasks from various modalities, including tabular, image, and text.
NIPQ: Noise Injection Pseudo Quantization for Automated DNN Optimization
Jun 02, 2022
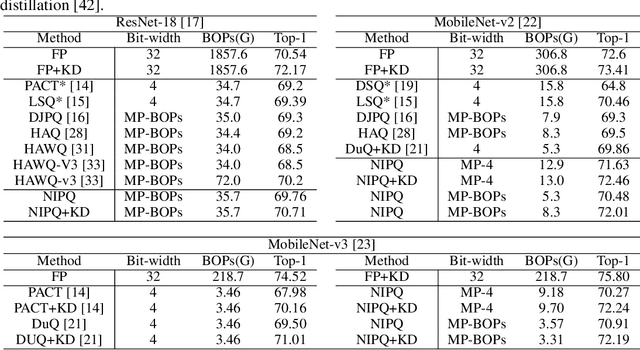
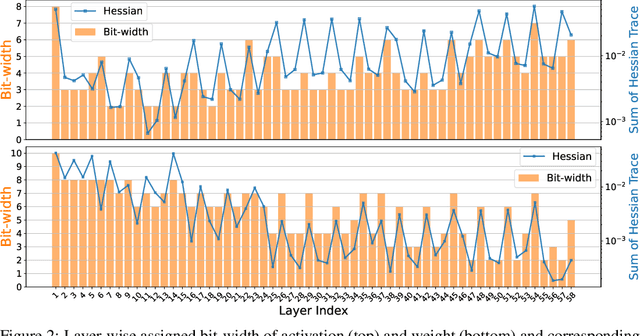

The optimization of neural networks in terms of computation cost and memory footprint is crucial for their practical deployment on edge devices. In this work, we propose a novel quantization-aware training (QAT) scheme called noise injection pseudo quantization (NIPQ). NIPQ is implemented based on pseudo quantization noise (PQN) and has several advantages. First, both activation and weight can be quantized based on a unified framework. Second, the hyper-parameters of quantization (e.g., layer-wise bit-width and quantization interval) are automatically tuned. Third, after QAT, the network has robustness against quantization, thereby making it easier to deploy in practice. To validate the superiority of the proposed algorithm, we provide extensive analysis and conduct diverse experiments for various vision applications. Our comprehensive experiments validate the outstanding performance of the proposed algorithm in several aspects.
Multi-Modal Mixup for Robust Fine-tuning
Mar 08, 2022
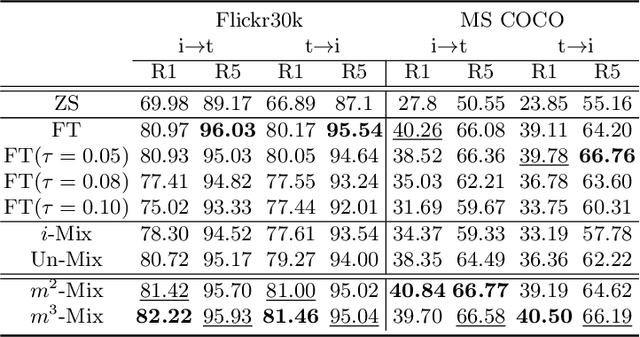


Pre-trained large-scale models provide a transferable embedding, and they show comparable performance on the diverse downstream task. However, the transferability of multi-modal learning is restricted, and the analysis of learned embedding has not been explored well. This paper provides a perspective to understand the multi-modal embedding in terms of uniformity and alignment. We newly find that the representation learned by multi-modal learning models such as CLIP has a two separated representation space for each heterogeneous dataset with less alignment. Besides, there are unexplored large intermediate areas between two modalities with less uniformity. Less robust embedding might restrict the transferability of the representation for the downstream task. This paper provides a new end-to-end fine-tuning method for robust representation that encourages better uniformity and alignment score. First, we propose a multi-modal Mixup, $m^{2}$-Mix that mixes the representation of image and text to generate the hard negative samples. Second, we fine-tune the multi-modal model on a hard negative sample as well as normal negative and positive samples with contrastive learning. Our multi-modal Mixup provides a robust representation, and we validate our methods on classification, retrieval, and structure-awareness task.