 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Mixup for Robust Fine-tuning
Paper and Code

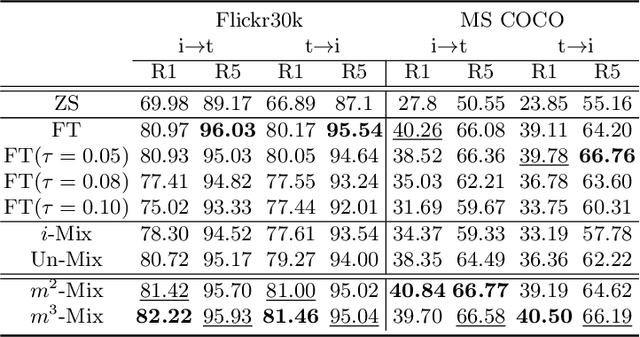


Pre-trained large-scale models provide a transferable embedding, and they show comparable performance on the diverse downstream task. However, the transferability of multi-modal learning is restricted, and the analysis of learned embedding has not been explored well. This paper provides a perspective to understand the multi-modal embedding in terms of uniformity and alignment. We newly find that the representation learned by multi-modal learning models such as CLIP has a two separated representation space for each heterogeneous dataset with less alignment. Besides, there are unexplored large intermediate areas between two modalities with less uniformity. Less robust embedding might restrict the transferability of the representation for the downstream task. This paper provides a new end-to-end fine-tuning method for robust representation that encourages better uniformity and alignment score. First, we propose a multi-modal Mixup, $m^{2}$-Mix that mixes the representation of image and text to generate the hard negative samples. Second, we fine-tune the multi-modal model on a hard negative sample as well as normal negative and positive samples with contrastive learning. Our multi-modal Mixup provides a robust representation, and we validate our methods on classification, retrieval, and structure-awareness task.