 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Live the Librarian! A Persistent Search Sub-Agent for Energy-Efficient Multi-Agent Software Engineering Systems
May 27, 2026Multi-agent systems (MAS) have substantially advanced autonomous software engineering (SWE), but their growing inference energy demands raise sustainability concerns. In this paper, we demonstrate that this cost is concentrated in an overlooked source: redundant output tokens generated across agents. Two empirical findings ground this claim. First, our per-token energy attribution for MAS reveals a sharp asymmetry: an output token consumes 30 to 1,000 times more energy than an input or cached token. Second, MAS inflate per-episode output because agents repeatedly re-explore overlapping repository regions. To address this inefficiency, we propose Librarian, a persistent search sub-agent that tracks repository-search history and suppresses redundant exploration actions across agents. By returning short references to file regions instead of full file excerpts, Librarian further reduces output-token volume. On SWE-Bench Verified, Librarian reduces per-episode GPU energy consumption of existing multi-agent SWE systems by up to 25% while preserving task performance.
Transductive Generalization via Optimal Transport and Its Application to Graph Node Classification
Mar 10, 2026Many existing transductive bounds rely on classical complexity measures that are computationally intractable and often misaligned with empirical behavior. In this work, we establish new representation-based generalization bounds in a distribution-free transductive setting, where learned representations are dependent, and test features are accessible during training. We derive global and class-wise bounds via optimal transport, expressed in terms of Wasserstein distances between encoded feature distributions. We demonstrate that our bounds are efficiently computable and strongly correlate with empirical generalization in graph node classification, improving upon classical complexity measures. Additionally, our analysis reveals how the GNN aggregation process transforms the representation distributions, inducing a trade-off between intra-class concentration and inter-class separation. This yields depth-dependent characterizations that capture the non-monotonic relationship between depth and generalization error observed in practice. The code is available at https://github.com/ml-postech/Transductive-OT-Gen-Bound.
Influence Functions for Edge Edits in Non-Convex Graph Neural Networks
Jun 05, 2025Understanding how individual edges influence the behavior of graph neural networks (GNNs) is essential for improving their interpretability and robustness. Graph influence functions have emerged as promising tools to efficiently estimate the effects of edge deletions without retraining. However, existing influence prediction methods rely on strict convexity assumptions, exclusively consider the influence of edge deletions while disregarding edge insertions, and fail to capture changes in message propagation caused by these modifications. In this work, we propose a proximal Bregman response function specifically tailored for GNNs, relaxing the convexity requirement and enabling accurate influence prediction for standard neural network architectures. Furthermore, our method explicitly accounts for message propagation effects and extends influence prediction to both edge deletions and insertions in a principled way. Experiments with real-world datasets demonstrate accurate influence predictions for different characteristics of GNNs. We further demonstrate that the influence function is versatile in applications such as graph rewiring and adversarial attacks.
The Oversmoothing Fallacy: A Misguided Narrative in GNN Research
Jun 05, 2025Oversmoothing has been recognized as a main obstacle to building deep Graph Neural Networks (GNNs), limiting the performance. This position paper argues that the influence of oversmoothing has been overstated and advocates for a further exploration of deep GNN architectures. Given the three core operations of GNNs, aggregation, linear transformation, and non-linear activation, we show that prior studies have mistakenly confused oversmoothing with the vanishing gradient, caused by transformation and activation rather than aggregation. Our finding challenges prior beliefs about oversmoothing being unique to GNNs. Furthermore, we demonstrate that classical solutions such as skip connections and normalization enable the successful stacking of deep GNN layers without performance degradation. Our results clarify misconceptions about oversmoothing and shed new light on the potential of deep GNNs.
Posterior Label Smoothing for Node Classification
Jun 01, 2024Soft labels can improve the generalization of a neural network classifier in many domains, such as image classification. Despite its success, the current literature has overlooked the efficiency of label smoothing in node classification with graph-structured data. In this work, we propose a simple yet effective label smoothing for the transductive node classification task. We design the soft label to encapsulate the local context of the target node through the neighborhood label distribution. We apply the smoothing method for seven baseline models to show its effectiveness. The label smoothing methods improve the classification accuracy in 10 node classification datasets in most cases. In the following analysis, we find that incorporating global label statistics in posterior computation is the key to the success of label smoothing. Further investigation reveals that the soft labels mitigate overfitting during training, leading to better generalization performance.
Distinguishing Neighborhood Representations Through Reverse Process of GNNs for Heterophilic Graphs
Mar 11, 2024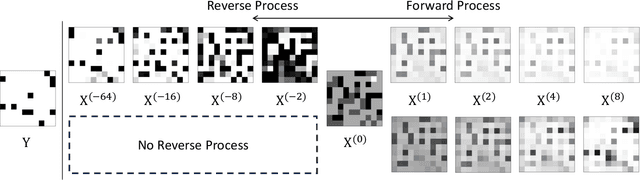

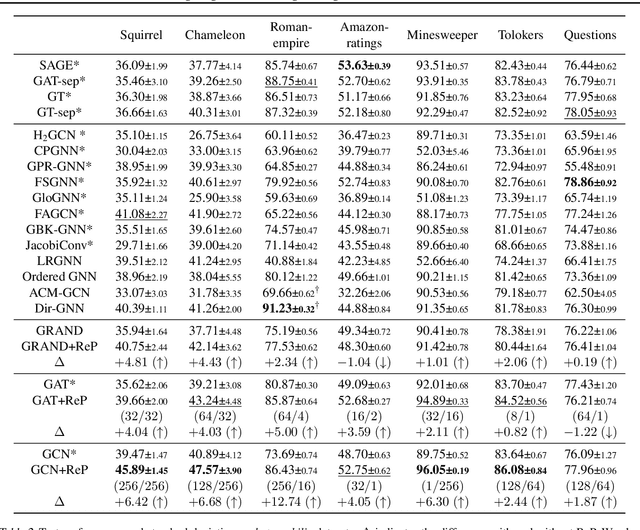
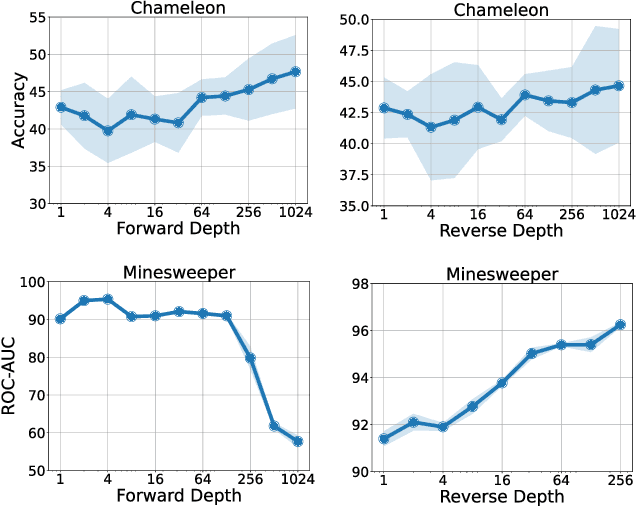
Graph Neural Network (GNN) resembles the diffusion process, leading to the over-smoothing of learned representations when stacking many layers. Hence, the reverse process of message passing can sharpen the node representations by inverting the forward message propagation. The sharpened representations can help us to better distinguish neighboring nodes with different labels, such as in heterophilic graphs. In this work, we apply the design principle of the reverse process to the three variants of the GNNs. Through the experiments on heterophilic graph data, where adjacent nodes need to have different representations for successful classification, we show that the reverse process significantly improves the prediction performance in many cases. Additional analysis reveals that the reverse mechanism can mitigate the over-smoothing over hundreds of layers.
EPIC: Graph Augmentation with Edit Path Interpolation via Learnable Cost
Jun 02, 2023



Graph-based models have become increasingly important in various domains, but the limited size and diversity of existing graph datasets often limit their performance. To address this issue, we propose EPIC (Edit Path Interpolation via learnable Cost), a novel interpolation-based method for augmenting graph datasets. Our approach leverages graph edit distance to generate new graphs that are similar to the original ones but exhibit some variation in their structures. To achieve this, we learn the graph edit distance through a comparison of labeled graphs and utilize this knowledge to create graph edit paths between pairs of original graphs. With randomly sampled graphs from a graph edit path, we enrich the training set to enhance the generalization capability of classification models. We demonstrate the effectiveness of our approach on several benchmark datasets and show that it outperforms existing augmentation methods in graph classification tasks.