 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeo: Real-Time On-Device 3D Gaussian Splatting with Reuse-and-Update Sorting Acceleration
Nov 17, 2025



3D Gaussian Splatting (3DGS) rendering in real-time on resource-constrained devices is essential for delivering immersive augmented and virtual reality (AR/VR) experiences. However, existing solutions struggle to achieve high frame rates, especially for high-resolution rendering. Our analysis identifies the sorting stage in the 3DGS rendering pipeline as the major bottleneck due to its high memory bandwidth demand. This paper presents Neo, which introduces a reuse-and-update sorting algorithm that exploits temporal redundancy in Gaussian ordering across consecutive frames, and devises a hardware accelerator optimized for this algorithm. By efficiently tracking and updating Gaussian depth ordering instead of re-sorting from scratch, Neo significantly reduces redundant computations and memory bandwidth pressure. Experimental results show that Neo achieves up to 10.0x and 5.6x higher throughput than state-of-the-art edge GPU and ASIC solution, respectively, while reducing DRAM traffic by 94.5% and 81.3%. These improvements make high-quality and low-latency on-device 3D rendering more practical.
Déjà Vu: Efficient Video-Language Query Engine with Learning-based Inter-Frame Computation Reuse
Jun 17, 2025Recently, Video-Language Models (VideoLMs) have demonstrated remarkable capabilities, offering significant potential for flexible and powerful video query systems. These models typically rely on Vision Transformers (ViTs), which process video frames individually to extract visual embeddings. However, generating embeddings for large-scale videos requires ViT inferencing across numerous frames, posing a major hurdle to real-world deployment and necessitating solutions for integration into scalable video data management systems. This paper introduces D\'ej\`a Vu, a video-language query engine that accelerates ViT-based VideoLMs by reusing computations across consecutive frames. At its core is ReuseViT, a modified ViT model specifically designed for VideoLM tasks, which learns to detect inter-frame reuse opportunities, striking an effective balance between accuracy and reuse. Although ReuseViT significantly reduces computation, these savings do not directly translate into performance gains on GPUs. To overcome this, D\'ej\`a Vu integrates memory-compute joint compaction techniques that convert the FLOP savings into tangible performance gains. Evaluations on three VideoLM tasks show that D\'ej\`a Vu accelerates embedding generation by up to a 2.64x within a 2% error bound, dramatically enhancing the practicality of VideoLMs for large-scale video analytics.
MixDiT: Accelerating Image Diffusion Transformer Inference with Mixed-Precision MX Quantization
Apr 11, 2025Diffusion Transformer (DiT) has driven significant progress in image generation tasks. However, DiT inferencing is notoriously compute-intensive and incurs long latency even on datacenter-scale GPUs, primarily due to its iterative nature and heavy reliance on GEMM operations inherent to its encoder-based structure. To address the challenge, prior work has explored quantization, but achieving low-precision quantization for DiT inferencing with both high accuracy and substantial speedup remains an open problem. To this end, this paper proposes MixDiT, an algorithm-hardware co-designed acceleration solution that exploits mixed Microscaling (MX) formats to quantize DiT activation values. MixDiT quantizes the DiT activation tensors by selectively applying higher precision to magnitude-based outliers, which produce mixed-precision GEMM operations. To achieve tangible speedup from the mixed-precision arithmetic, we design a MixDiT accelerator that enables precision-flexible multiplications and efficient MX precision conversions. Our experimental results show that MixDiT delivers a speedup of 2.10-5.32 times over RTX 3090, with no loss in FID.
DaCapo: Accelerating Continuous Learning in Autonomous Systems for Video Analytics
Mar 21, 2024Deep neural network (DNN) video analytics is crucial for autonomous systems such as self-driving vehicles, unmanned aerial vehicles (UAVs), and security robots. However, real-world deployment faces challenges due to their limited computational resources and battery power. To tackle these challenges, continuous learning exploits a lightweight "student" model at deployment (inference), leverages a larger "teacher" model for labeling sampled data (labeling), and continuously retrains the student model to adapt to changing scenarios (retraining). This paper highlights the limitations in state-of-the-art continuous learning systems: (1) they focus on computations for retraining, while overlooking the compute needs for inference and labeling, (2) they rely on power-hungry GPUs, unsuitable for battery-operated autonomous systems, and (3) they are located on a remote centralized server, intended for multi-tenant scenarios, again unsuitable for autonomous systems due to privacy, network availability, and latency concerns. We propose a hardware-algorithm co-designed solution for continuous learning, DaCapo, that enables autonomous systems to perform concurrent executions of inference, labeling, and training in a performant and energy-efficient manner. DaCapo comprises (1) a spatially-partitionable and precision-flexible accelerator enabling parallel execution of kernels on sub-accelerators at their respective precisions, and (2) a spatiotemporal resource allocation algorithm that strategically navigates the resource-accuracy tradeoff space, facilitating optimal decisions for resource allocation to achieve maximal accuracy. Our evaluation shows that DaCapo achieves 6.5% and 5.5% higher accuracy than a state-of-the-art GPU-based continuous learning systems, Ekya and EOMU, respectively, while consuming 254x less power.
Accelerating String-Key Learned Index Structures via Memoization-based Incremental Training
Mar 18, 2024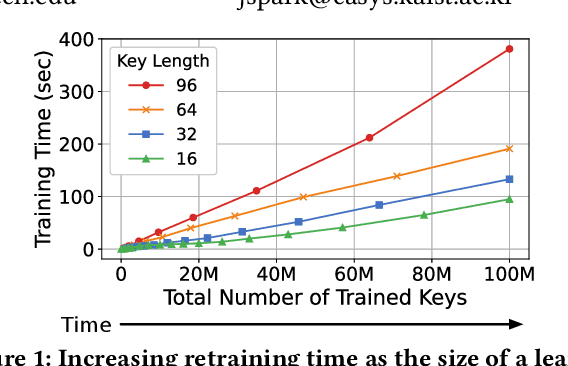
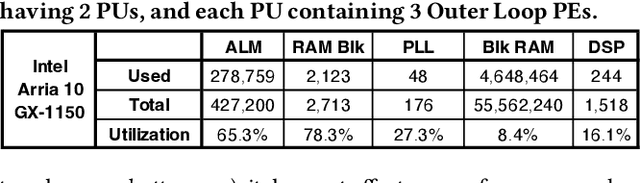
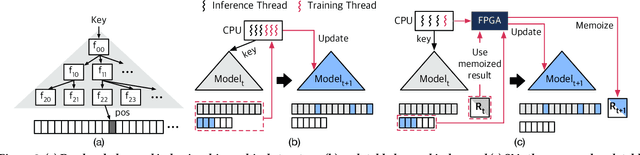
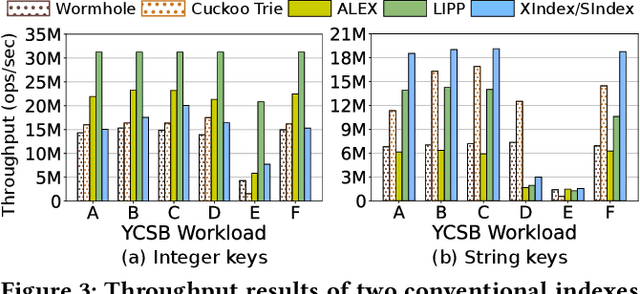
Learned indexes use machine learning models to learn the mappings between keys and their corresponding positions in key-value indexes. These indexes use the mapping information as training data. Learned indexes require frequent retrainings of their models to incorporate the changes introduced by update queries. To efficiently retrain the models, existing learned index systems often harness a linear algebraic QR factorization technique that performs matrix decomposition. This factorization approach processes all key-position pairs during each retraining, resulting in compute operations that grow linearly with the total number of keys and their lengths. Consequently, the retrainings create a severe performance bottleneck, especially for variable-length string keys, while the retrainings are crucial for maintaining high prediction accuracy and in turn, ensuring low query service latency. To address this performance problem, we develop an algorithm-hardware co-designed string-key learned index system, dubbed SIA. In designing SIA, we leverage a unique algorithmic property of the matrix decomposition-based training method. Exploiting the property, we develop a memoization-based incremental training scheme, which only requires computation over updated keys, while decomposition results of non-updated keys from previous computations can be reused. We further enhance SIA to offload a portion of this training process to an FPGA accelerator to not only relieve CPU resources for serving index queries (i.e., inference), but also accelerate the training itself. Our evaluation shows that compared to ALEX, LIPP, and SIndex, a state-of-the-art learned index systems, SIA-accelerated learned indexes offer 2.6x and 3.4x higher throughput on the two real-world benchmark suites, YCSB and Twitter cache trace, respectively.
Booster-SHOT: Boosting Stacked Homography Transformations for Multiview Pedestrian Detection with Attention
Aug 19, 2022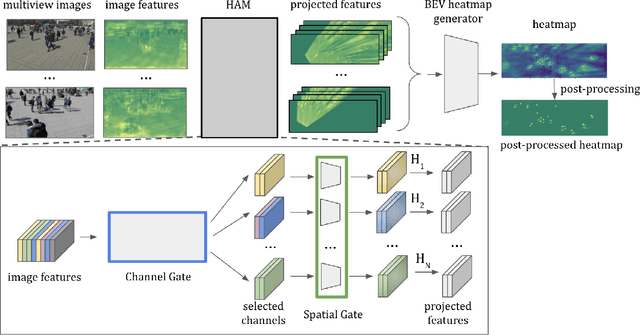
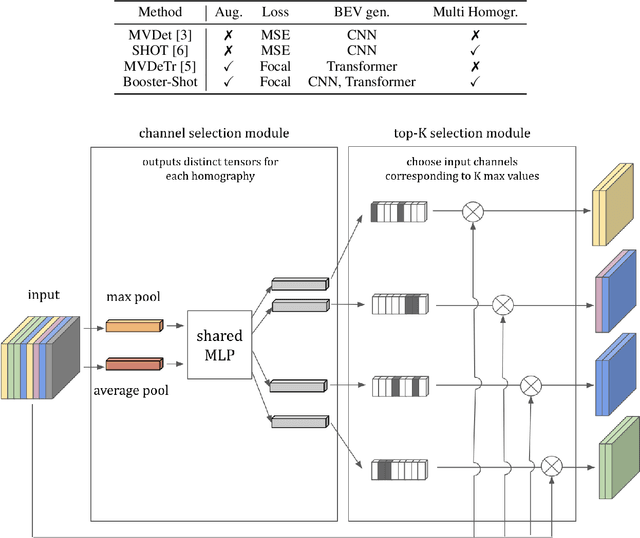
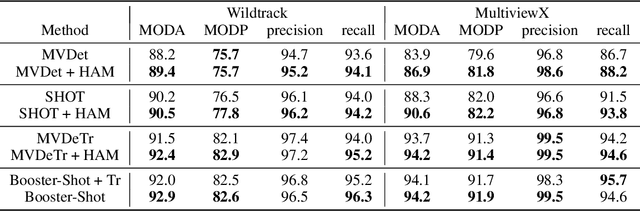
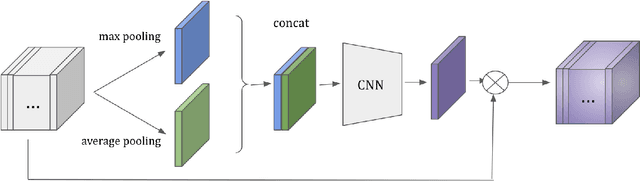
Improving multi-view aggregation is integral for multi-view pedestrian detection, which aims to obtain a bird's-eye-view pedestrian occupancy map from images captured through a set of calibrated cameras. Inspired by the success of attention modules for deep neural networks, we first propose a Homography Attention Module (HAM) which is shown to boost the performance of existing end-to-end multiview detection approaches by utilizing a novel channel gate and spatial gate. Additionally, we propose Booster-SHOT, an end-to-end convolutional approach to multiview pedestrian detection incorporating our proposed HAM as well as elements from previous approaches such as view-coherent augmentation or stacked homography transformations. Booster-SHOT achieves 92.9% and 94.2% for MODA on Wildtrack and MultiviewX respectively, outperforming the state-of-the-art by 1.4% on Wildtrack and 0.5% on MultiviewX, achieving state-of-the-art performance overall for standard evaluation metrics used in multi-view pedestrian detection.
Privacy Safe Representation Learning via Frequency Filtering Encoder
Aug 04, 2022
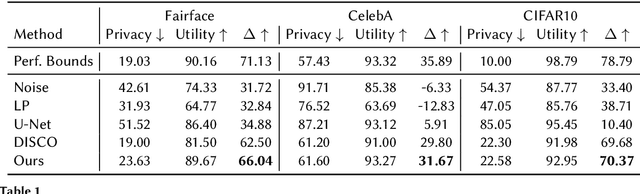

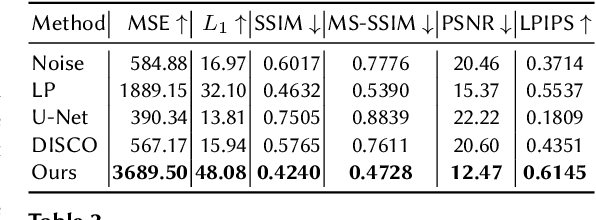
Deep learning models are increasingly deployed in real-world applications. These models are often deployed on the server-side and receive user data in an information-rich representation to solve a specific task, such as image classification. Since images can contain sensitive information, which users might not be willing to share, privacy protection becomes increasingly important. Adversarial Representation Learning (ARL) is a common approach to train an encoder that runs on the client-side and obfuscates an image. It is assumed, that the obfuscated image can safely be transmitted and used for the task on the server without privacy concerns. However, in this work, we find that training a reconstruction attacker can successfully recover the original image of existing ARL methods. To this end, we introduce a novel ARL method enhanced through low-pass filtering, limiting the available information amount to be encoded in the frequency domain. Our experimental results reveal that our approach withstands reconstruction attacks while outperforming previous state-of-the-art methods regarding the privacy-utility trade-off. We further conduct a user study to qualitatively assess our defense of the reconstruction attack.
CoVA: Exploiting Compressed-Domain Analysis to Accelerate Video Analytics
Jul 02, 2022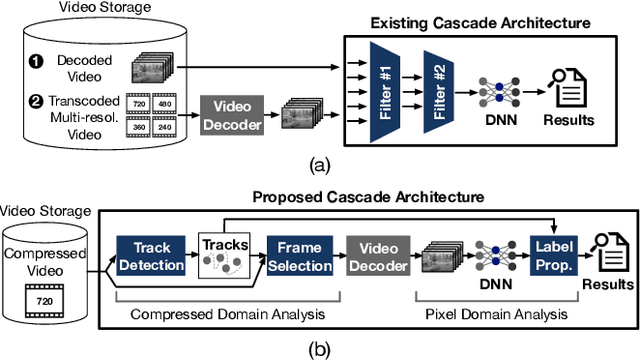
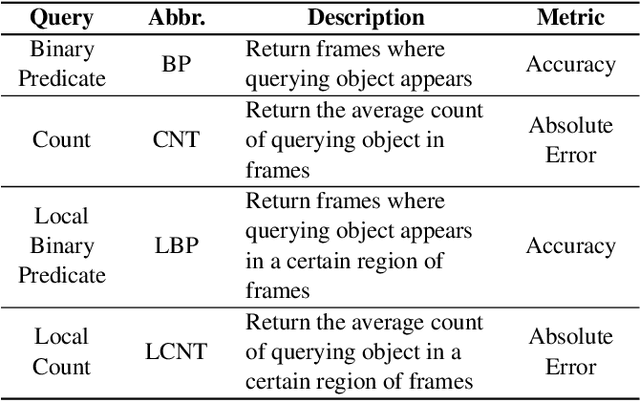
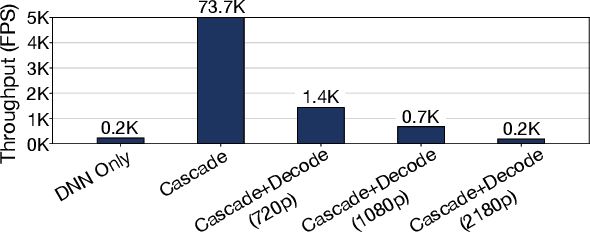

Modern retrospective analytics systems leverage cascade architecture to mitigate bottleneck for computing deep neural networks (DNNs). However, the existing cascades suffer two limitations: (1) decoding bottleneck is either neglected or circumvented, paying significant compute and storage cost for pre-processing; and (2) the systems are specialized for temporal queries and lack spatial query support. This paper presents CoVA, a novel cascade architecture that splits the cascade computation between compressed domain and pixel domain to address the decoding bottleneck, supporting both temporal and spatial queries. CoVA cascades analysis into three major stages where the first two stages are performed in compressed domain while the last one in pixel domain. First, CoVA detects occurrences of moving objects (called blobs) over a set of compressed frames (called tracks). Then, using the track results, CoVA prudently selects a minimal set of frames to obtain the label information and only decode them to compute the full DNNs, alleviating the decoding bottleneck. Lastly, CoVA associates tracks with labels to produce the final analysis results on which users can process both temporal and spatial queries. Our experiments demonstrate that CoVA offers 4.8x throughput improvement over modern cascade systems, while imposing modest accuracy loss.