 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Assembly: Semi-Supervised Multi-Task Learning from Multiple Datasets with Disjoint Labels
Jun 15, 2023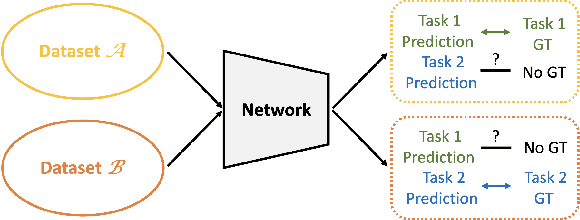



In real-world scenarios we often need to perform multiple tasks simultaneously. Multi-Task Learning (MTL) is an adequate method to do so, but usually requires datasets labeled for all tasks. We propose a method that can leverage datasets labeled for only some of the tasks in the MTL framework. Our work, Knowledge Assembly (KA), learns multiple tasks from disjoint datasets by leveraging the unlabeled data in a semi-supervised manner, using model augmentation for pseudo-supervision. Whilst KA can be implemented on any existing MTL networks, we test our method on jointly learning person re-identification (reID) and pedestrian attribute recognition (PAR). We surpass the single task fully-supervised performance by $4.2\%$ points for reID and $0.9\%$ points for PAR.
Booster-SHOT: Boosting Stacked Homography Transformations for Multiview Pedestrian Detection with Attention
Aug 19, 2022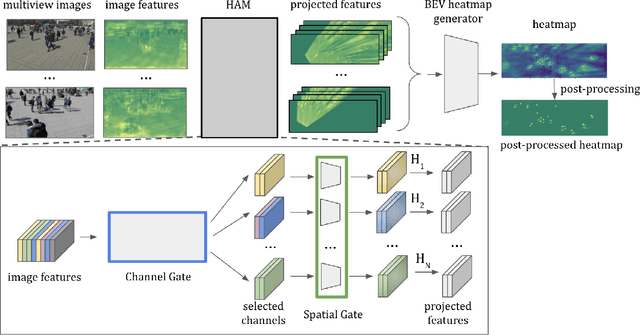
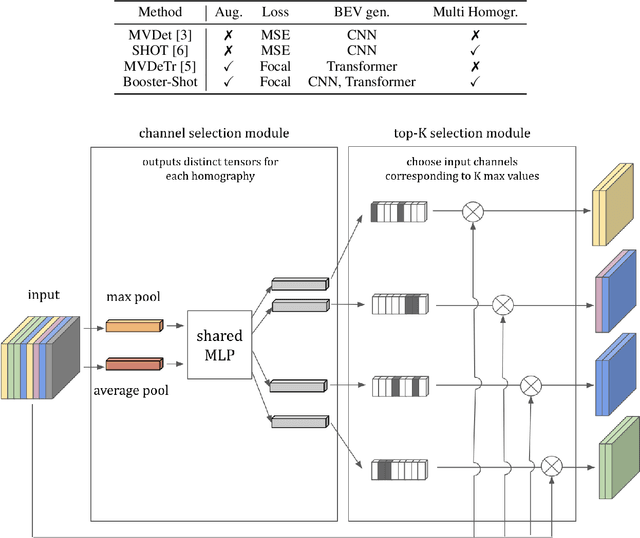
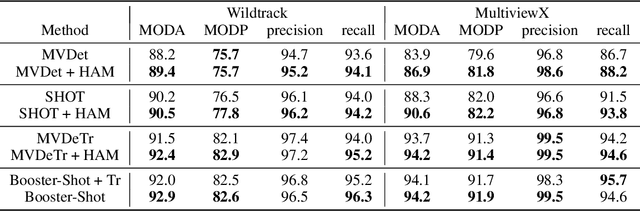
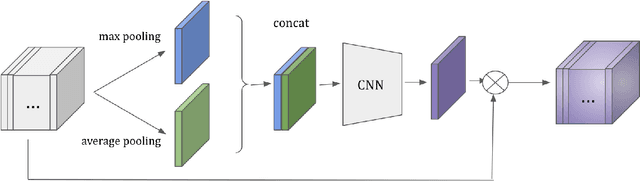
Improving multi-view aggregation is integral for multi-view pedestrian detection, which aims to obtain a bird's-eye-view pedestrian occupancy map from images captured through a set of calibrated cameras. Inspired by the success of attention modules for deep neural networks, we first propose a Homography Attention Module (HAM) which is shown to boost the performance of existing end-to-end multiview detection approaches by utilizing a novel channel gate and spatial gate. Additionally, we propose Booster-SHOT, an end-to-end convolutional approach to multiview pedestrian detection incorporating our proposed HAM as well as elements from previous approaches such as view-coherent augmentation or stacked homography transformations. Booster-SHOT achieves 92.9% and 94.2% for MODA on Wildtrack and MultiviewX respectively, outperforming the state-of-the-art by 1.4% on Wildtrack and 0.5% on MultiviewX, achieving state-of-the-art performance overall for standard evaluation metrics used in multi-view pedestrian detection.
Privacy Safe Representation Learning via Frequency Filtering Encoder
Aug 04, 2022
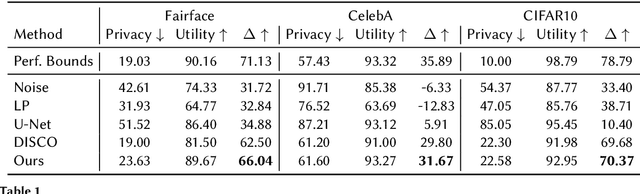

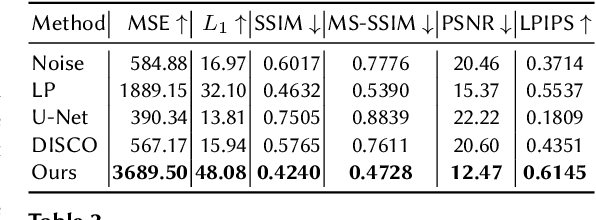
Deep learning models are increasingly deployed in real-world applications. These models are often deployed on the server-side and receive user data in an information-rich representation to solve a specific task, such as image classification. Since images can contain sensitive information, which users might not be willing to share, privacy protection becomes increasingly important. Adversarial Representation Learning (ARL) is a common approach to train an encoder that runs on the client-side and obfuscates an image. It is assumed, that the obfuscated image can safely be transmitted and used for the task on the server without privacy concerns. However, in this work, we find that training a reconstruction attacker can successfully recover the original image of existing ARL methods. To this end, we introduce a novel ARL method enhanced through low-pass filtering, limiting the available information amount to be encoded in the frequency domain. Our experimental results reveal that our approach withstands reconstruction attacks while outperforming previous state-of-the-art methods regarding the privacy-utility trade-off. We further conduct a user study to qualitatively assess our defense of the reconstruction attack.
Training with the Invisibles: Obfuscating Images to Share Safely for Learning Visual Recognition Models
Jan 01, 2019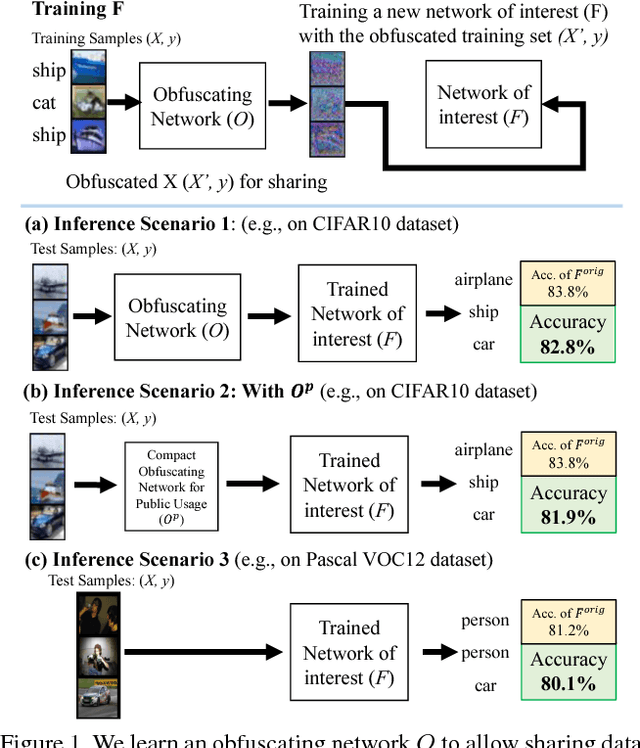


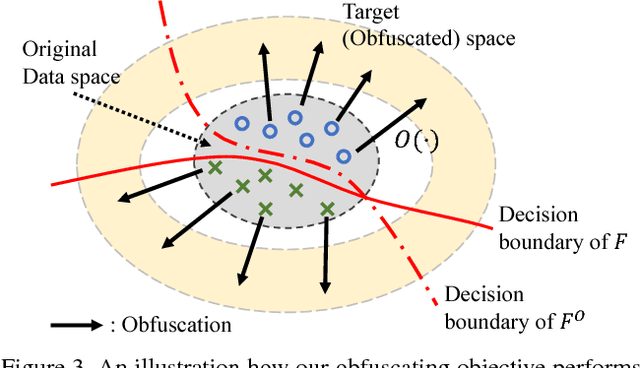
High-performance visual recognition systems generally require a large collection of labeled images to train. The expensive data curation can be an obstacle for improving recognition performance. Sharing more data allows training for better models. But personal and private information in the data prevent such sharing. To promote sharing visual data for learning a recognition model, we propose to obfuscate the images so that humans are not able to recognize their detailed contents, while machines can still utilize them to train new models. We validate our approach by comprehensive experiments on three challenging visual recognition tasks; image classification, attribute classification, and facial landmark detection on several datasets including SVHN, CIFAR10, Pascal VOC 2012, CelebA, and MTFL. Our method successfully obfuscates the images from humans recognition, but a machine model trained with them performs within about 1% margin (up to 0.48%) of the performance of a model trained with the original, non-obfuscated data.