 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Culturally Aligned LLMs through Ontology-Guided Multi-Agent Reasoning
Jan 29, 2026Large Language Models (LLMs) increasingly support culturally sensitive decision making, yet often exhibit misalignment due to skewed pretraining data and the absence of structured value representations. Existing methods can steer outputs, but often lack demographic grounding and treat values as independent, unstructured signals, reducing consistency and interpretability. We propose OG-MAR, an Ontology-Guided Multi-Agent Reasoning framework. OG-MAR summarizes respondent-specific values from the World Values Survey (WVS) and constructs a global cultural ontology by eliciting relations over a fixed taxonomy via competency questions. At inference time, it retrieves ontology-consistent relations and demographically similar profiles to instantiate multiple value-persona agents, whose outputs are synthesized by a judgment agent that enforces ontology consistency and demographic proximity. Experiments on regional social-survey benchmarks across four LLM backbones show that OG-MAR improves cultural alignment and robustness over competitive baselines, while producing more transparent reasoning traces.
MARIC: Multi-Agent Reasoning for Image Classification
Sep 18, 2025Image classification has traditionally relied on parameter-intensive model training, requiring large-scale annotated datasets and extensive fine tuning to achieve competitive performance. While recent vision language models (VLMs) alleviate some of these constraints, they remain limited by their reliance on single pass representations, often failing to capture complementary aspects of visual content. In this paper, we introduce Multi Agent based Reasoning for Image Classification (MARIC), a multi agent framework that reformulates image classification as a collaborative reasoning process. MARIC first utilizes an Outliner Agent to analyze the global theme of the image and generate targeted prompts. Based on these prompts, three Aspect Agents extract fine grained descriptions along distinct visual dimensions. Finally, a Reasoning Agent synthesizes these complementary outputs through integrated reflection step, producing a unified representation for classification. By explicitly decomposing the task into multiple perspectives and encouraging reflective synthesis, MARIC mitigates the shortcomings of both parameter-heavy training and monolithic VLM reasoning. Experiments on 4 diverse image classification benchmark datasets demonstrate that MARIC significantly outperforms baselines, highlighting the effectiveness of multi-agent visual reasoning for robust and interpretable image classification.
Knowledge Assembly: Semi-Supervised Multi-Task Learning from Multiple Datasets with Disjoint Labels
Jun 15, 2023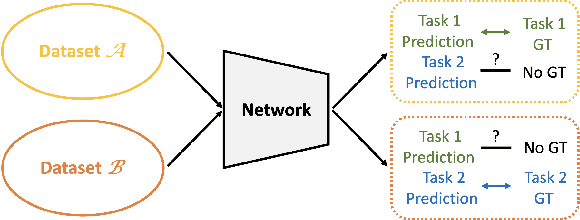



In real-world scenarios we often need to perform multiple tasks simultaneously. Multi-Task Learning (MTL) is an adequate method to do so, but usually requires datasets labeled for all tasks. We propose a method that can leverage datasets labeled for only some of the tasks in the MTL framework. Our work, Knowledge Assembly (KA), learns multiple tasks from disjoint datasets by leveraging the unlabeled data in a semi-supervised manner, using model augmentation for pseudo-supervision. Whilst KA can be implemented on any existing MTL networks, we test our method on jointly learning person re-identification (reID) and pedestrian attribute recognition (PAR). We surpass the single task fully-supervised performance by $4.2\%$ points for reID and $0.9\%$ points for PAR.