 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Culturally Aligned LLMs through Ontology-Guided Multi-Agent Reasoning
Jan 29, 2026Large Language Models (LLMs) increasingly support culturally sensitive decision making, yet often exhibit misalignment due to skewed pretraining data and the absence of structured value representations. Existing methods can steer outputs, but often lack demographic grounding and treat values as independent, unstructured signals, reducing consistency and interpretability. We propose OG-MAR, an Ontology-Guided Multi-Agent Reasoning framework. OG-MAR summarizes respondent-specific values from the World Values Survey (WVS) and constructs a global cultural ontology by eliciting relations over a fixed taxonomy via competency questions. At inference time, it retrieves ontology-consistent relations and demographically similar profiles to instantiate multiple value-persona agents, whose outputs are synthesized by a judgment agent that enforces ontology consistency and demographic proximity. Experiments on regional social-survey benchmarks across four LLM backbones show that OG-MAR improves cultural alignment and robustness over competitive baselines, while producing more transparent reasoning traces.
Wavelet-Driven Masked Multiscale Reconstruction for PPG Foundation Models
Jan 18, 2026Wearable foundation models have the potential to transform digital health by learning transferable representations from large-scale biosignals collected in everyday settings. While recent progress has been made in large-scale pretraining, most approaches overlook the spectral structure of photoplethysmography (PPG) signals, wherein physiological rhythms unfold across multiple frequency bands. Motivated by the insight that many downstream health-related tasks depend on multi-resolution features spanning fine-grained waveform morphology to global rhythmic dynamics, we introduce Masked Multiscale Reconstruction (MMR) for PPG representation learning - a self-supervised pretraining framework that explicitly learns from hierarchical time-frequency scales of PPG data. The pretraining task is designed to reconstruct randomly masked out coefficients obtained from a wavelet-based multiresolution decomposition of PPG signals, forcing the transformer encoder to integrate information across temporal and spectral scales. We pretrain our model with MMR using ~17 million unlabeled 10-second PPG segments from ~32,000 smartwatch users. On 17 of 19 diverse health-related tasks, MMR trained on large-scale wearable PPG data improves over or matches state-of-the-art open-source PPG foundation models, time-series foundation models, and other self-supervised baselines. Extensive analysis of our learned embeddings and systematic ablations underscores the value of wavelet-based representations, showing that they capture robust and physiologically-grounded features. Together, these results highlight the potential of MMR as a step toward generalizable PPG foundation models.
SPIO: Ensemble and Selective Strategies via LLM-Based Multi-Agent Planning in Automated Data Science
Mar 30, 2025



Large Language Models (LLMs) have revolutionized automated data analytics and machine learning by enabling dynamic reasoning and adaptability. While recent approaches have advanced multi-stage pipelines through multi-agent systems, they typically rely on rigid, single-path workflows that limit the exploration and integration of diverse strategies, often resulting in suboptimal predictions. To address these challenges, we propose SPIO (Sequential Plan Integration and Optimization), a novel framework that leverages LLM-driven decision-making to orchestrate multi-agent planning across four key modules: data preprocessing, feature engineering, modeling, and hyperparameter tuning. In each module, dedicated planning agents independently generate candidate strategies that cascade into subsequent stages, fostering comprehensive exploration. A plan optimization agent refines these strategies by suggesting several optimized plans. We further introduce two variants: SPIO-S, which selects a single best solution path as determined by the LLM, and SPIO-E, which selects the top k candidate plans and ensembles them to maximize predictive performance. Extensive experiments on Kaggle and OpenML datasets demonstrate that SPIO significantly outperforms state-of-the-art methods, providing a robust and scalable solution for automated data science task.
Learning to Activate Relay Nodes: Deep Reinforcement Learning Approach
Nov 24, 2018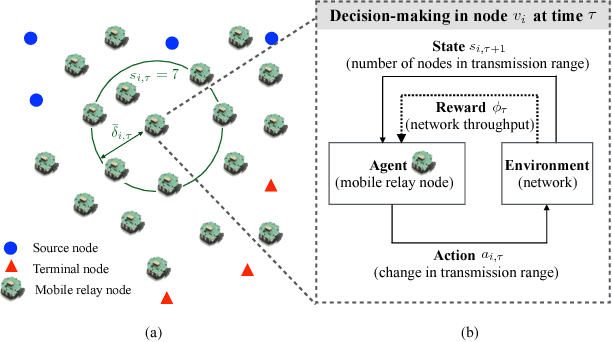
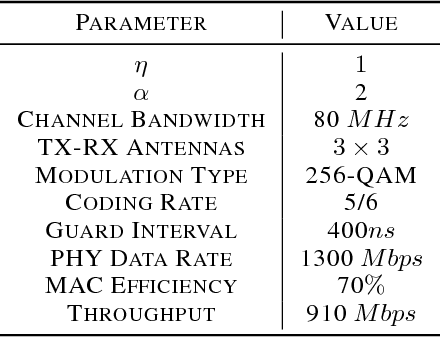
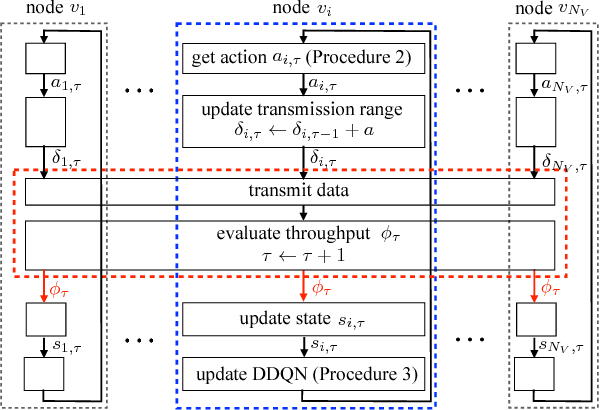
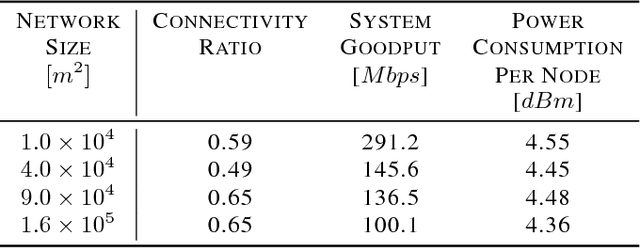
In this paper, we propose a distributed solution to design a multi-hop ad hoc network where mobile relay nodes strategically determine their wireless transmission ranges based on a deep reinforcement learning approach. We consider scenarios where only a limited networking infrastructure is available but a large number of wireless mobile relay nodes are deployed in building a multi-hop ad hoc network to deliver source data to the destination. A mobile relay node is considered as a decision-making agent that strategically determines its transmission range in a way that maximizes network throughput while minimizing the corresponding transmission power consumption. Each relay node collects information from its partial observations and learns its environment through a sequence of experiences. Hence, the proposed solution requires only a minimal amount of information from the system. We show that the actions that the relay nodes take from its policy are determined as to activate or inactivate its transmission, i.e., only necessary relay nodes are activated with the maximum transmit power, and nonessential nodes are deactivated to minimize power consumption. Using extensive experiments, we confirm that the proposed solution builds a network with higher network performance than current state-of-the-art solutions in terms of system goodput and connectivity ratio.