 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Hoc Merging is Not Enough: Many-Shot Model Merging with Loss-Gap Balancing
Jun 15, 2026Model merging has become a practical post-training strategy for building a single multi-task large language model (LLM) by combining multiple task-specialized models. However, most existing approaches rely on post-hoc merging, in which task-specific models are merged only once after training. This one-shot aggregation often suffers from task interference, leading to information erasure across individual tasks. In this work, we show that replacing post-hoc merging with an iterative many-shot merging protocol is effective in improving multi-task performance. Building on this insight, we propose METIS, Mitigating Erasure from Task Interference for Stable many-shot merging. METIS is a loss-aware many-shot merging method that addresses information erasure in post-hoc merging through task-wise loss-gap weighting and consensus-based masking. Notably, METIS exhibits significant performance improvement on the worst-performing task, effectively mitigating information erasure. (Project page: https://imkyungjin.github.io/METIS/)
Multi$^2$: Hierarchical Multi-Agent Decision-Making with LLM-Based Agents in Interactive Environments
Jun 02, 2026A central goal of large language model (LLM) research is to build agentic systems that can plan, act, and adapt through sustained interaction with dynamic environments. While recent LLM-based agents exhibit impressive contextual reasoning, their long-horizon decision-making remains fragile, often suffering from objective drift, where goals and plans drift over extended interactions. We introduce Multi$^2$, a hierarchical multi-agent decision-making framework that explicitly decomposes agent behavior into complementary roles. A high-level agent (System 1) focuses on context-aware sub-goal generation using supervised fine-tuning (SFT), while a low-level agent (System 2) executes atomic actions through offline-to-online reinforcement learning (RL) in interactive environments. This separation enables stable long-horizon control, mitigates objective drift, and allows efficient adaptation. Across diverse interactive environments, Multi$^2$ consistently outperforms strong agentic baselines, demonstrating improved robustness and coordination in multi-turn interaction. Beyond performance, we introduce and release three hierarchical benchmark datasets, filling a long-standing gap in training and evaluating hierarchical decision-making for LLM-based agents.
Fed-ADE: Adaptive Learning Rate for Federated Post-adaptation under Distribution Shift
Mar 01, 2026Federated learning (FL) in post-deployment settings must adapt to non-stationary data streams across heterogeneous clients without access to ground-truth labels. A major challenge is learning rate selection under client-specific, time-varying distribution shifts, where fixed learning rates often lead to underfitting or divergence. We propose Fed-ADE (Federated Adaptation with Distribution Shift Estimation), an unsupervised federated adaptation framework that leverages lightweight estimators of distribution dynamics. Specifically, Fed-ADE employs uncertainty dynamics estimation to capture changes in predictive uncertainty and representation dynamics estimation to detect covariate-level feature drift, combining them into a per-client, per-timestep adaptive learning rate. We provide theoretical analyses showing that our dynamics estimation approximates the underlying distribution shift and yields dynamic regret and convergence guarantees. Experiments on image and text benchmarks under diverse distribution shifts (label and covariate) demonstrate consistent improvements over strong baselines. These results highlight that distribution shift-aware adaptation enables effective and robust federated post-adaptation under real-world non-stationarity.
Temporal Distance-aware Transition Augmentation for Offline Model-based Reinforcement Learning
May 19, 2025The goal of offline reinforcement learning (RL) is to extract a high-performance policy from the fixed datasets, minimizing performance degradation due to out-of-distribution (OOD) samples. Offline model-based RL (MBRL) is a promising approach that ameliorates OOD issues by enriching state-action transitions with augmentations synthesized via a learned dynamics model. Unfortunately, seminal offline MBRL methods often struggle in sparse-reward, long-horizon tasks. In this work, we introduce a novel MBRL framework, dubbed Temporal Distance-Aware Transition Augmentation (TempDATA), that generates augmented transitions in a temporally structured latent space rather than in raw state space. To model long-horizon behavior, TempDATA learns a latent abstraction that captures a temporal distance from both trajectory and transition levels of state space. Our experiments confirm that TempDATA outperforms previous offline MBRL methods and achieves matching or surpassing the performance of diffusion-based trajectory augmentation and goal-conditioned RL on the D4RL AntMaze, FrankaKitchen, CALVIN, and pixel-based FrankaKitchen.
Episodic Future Thinking Mechanism for Multi-agent Reinforcement Learning
Oct 22, 2024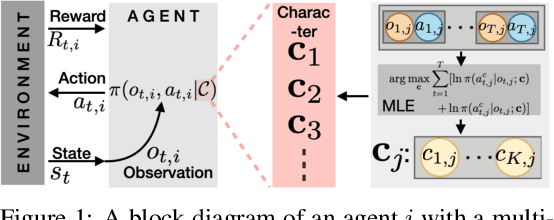
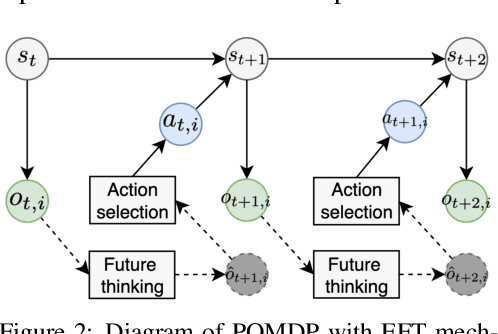
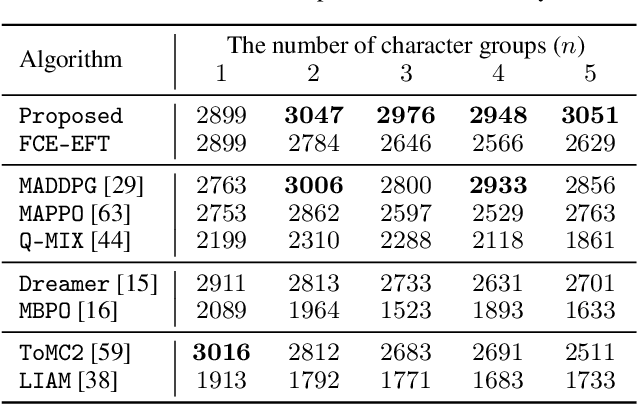
Understanding cognitive processes in multi-agent interactions is a primary goal in cognitive science. It can guide the direction of artificial intelligence (AI) research toward social decision-making in multi-agent systems, which includes uncertainty from character heterogeneity. In this paper, we introduce an episodic future thinking (EFT) mechanism for a reinforcement learning (RL) agent, inspired by cognitive processes observed in animals. To enable future thinking functionality, we first develop a multi-character policy that captures diverse characters with an ensemble of heterogeneous policies. Here, the character of an agent is defined as a different weight combination on reward components, representing distinct behavioral preferences. The future thinking agent collects observation-action trajectories of the target agents and uses the pre-trained multi-character policy to infer their characters. Once the character is inferred, the agent predicts the upcoming actions of target agents and simulates the potential future scenario. This capability allows the agent to adaptively select the optimal action, considering the predicted future scenario in multi-agent interactions. To evaluate the proposed mechanism, we consider the multi-agent autonomous driving scenario with diverse driving traits and multiple particle environments. Simulation results demonstrate that the EFT mechanism with accurate character inference leads to a higher reward than existing multi-agent solutions. We also confirm that the effect of reward improvement remains valid across societies with different levels of character diversity.
AD4RL: Autonomous Driving Benchmarks for Offline Reinforcement Learning with Value-based Dataset
Apr 03, 2024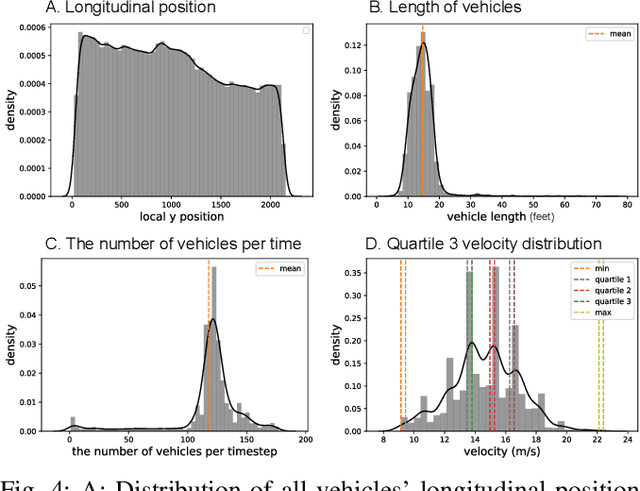
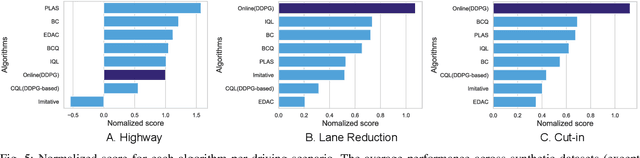
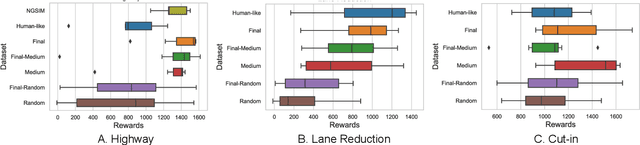
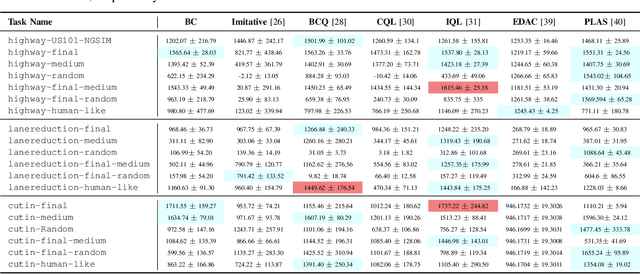
Offline reinforcement learning has emerged as a promising technology by enhancing its practicality through the use of pre-collected large datasets. Despite its practical benefits, most algorithm development research in offline reinforcement learning still relies on game tasks with synthetic datasets. To address such limitations, this paper provides autonomous driving datasets and benchmarks for offline reinforcement learning research. We provide 19 datasets, including real-world human driver's datasets, and seven popular offline reinforcement learning algorithms in three realistic driving scenarios. We also provide a unified decision-making process model that can operate effectively across different scenarios, serving as a reference framework in algorithm design. Our research lays the groundwork for further collaborations in the community to explore practical aspects of existing reinforcement learning methods. Dataset and codes can be found in https://sites.google.com/view/ad4rl.
Inverse Rational Control with Partially Observable Continuous Nonlinear Dynamics
Sep 26, 2020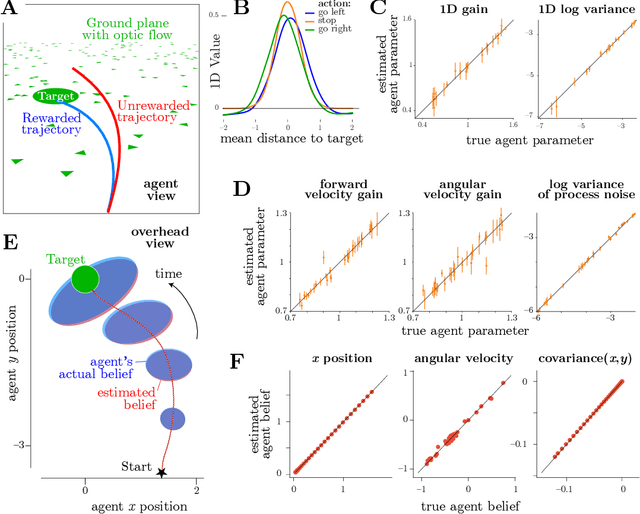
A fundamental question in neuroscience is how the brain creates an internal model of the world to guide actions using sequences of ambiguous sensory information. This is naturally formulated as a reinforcement learning problem under partial observations, where an agent must estimate relevant latent variables in the world from its evidence, anticipate possible future states, and choose actions that optimize total expected reward. This problem can be solved by control theory, which allows us to find the optimal actions for a given system dynamics and objective function. However, animals often appear to behave suboptimally. Why? We hypothesize that animals have their own flawed internal model of the world, and choose actions with the highest expected subjective reward according to that flawed model. We describe this behavior as rational but not optimal. The problem of Inverse Rational Control (IRC) aims to identify which internal model would best explain an agent's actions. Our contribution here generalizes past work on Inverse Rational Control which solved this problem for discrete control in partially observable Markov decision processes. Here we accommodate continuous nonlinear dynamics and continuous actions, and impute sensory observations corrupted by unknown noise that is private to the animal. We first build an optimal Bayesian agent that learns an optimal policy generalized over the entire model space of dynamics and subjective rewards using deep reinforcement learning. Crucially, this allows us to compute a likelihood over models for experimentally observable action trajectories acquired from a suboptimal agent. We then find the model parameters that maximize the likelihood using gradient ascent.
Learning to Activate Relay Nodes: Deep Reinforcement Learning Approach
Nov 24, 2018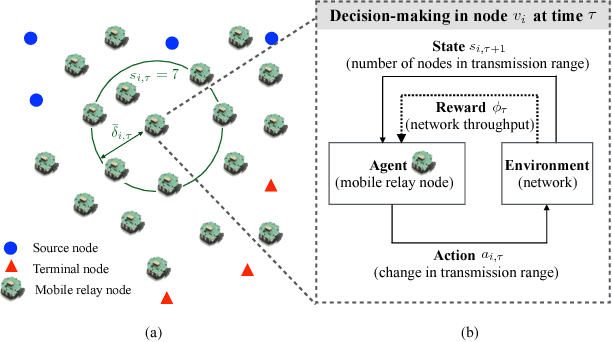
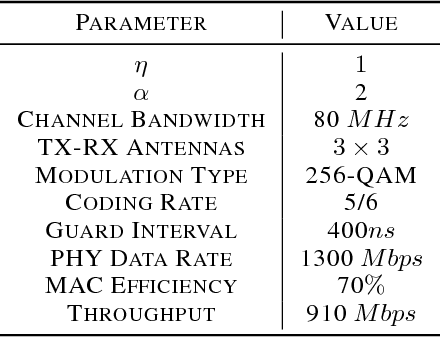
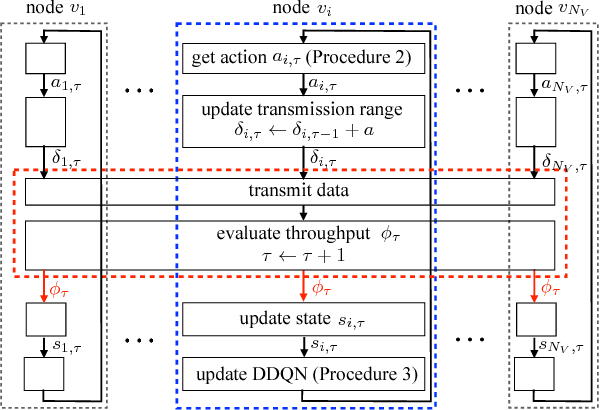
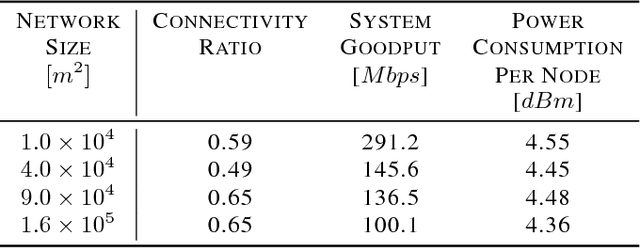
In this paper, we propose a distributed solution to design a multi-hop ad hoc network where mobile relay nodes strategically determine their wireless transmission ranges based on a deep reinforcement learning approach. We consider scenarios where only a limited networking infrastructure is available but a large number of wireless mobile relay nodes are deployed in building a multi-hop ad hoc network to deliver source data to the destination. A mobile relay node is considered as a decision-making agent that strategically determines its transmission range in a way that maximizes network throughput while minimizing the corresponding transmission power consumption. Each relay node collects information from its partial observations and learns its environment through a sequence of experiences. Hence, the proposed solution requires only a minimal amount of information from the system. We show that the actions that the relay nodes take from its policy are determined as to activate or inactivate its transmission, i.e., only necessary relay nodes are activated with the maximum transmit power, and nonessential nodes are deactivated to minimize power consumption. Using extensive experiments, we confirm that the proposed solution builds a network with higher network performance than current state-of-the-art solutions in terms of system goodput and connectivity ratio.
Network Coding Based Evolutionary Network Formation for Dynamic Wireless Networks
Aug 16, 2018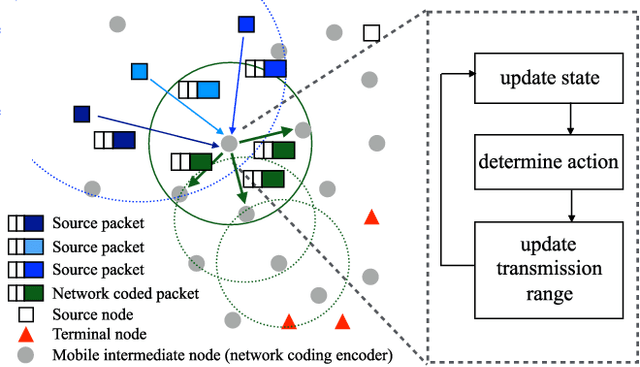

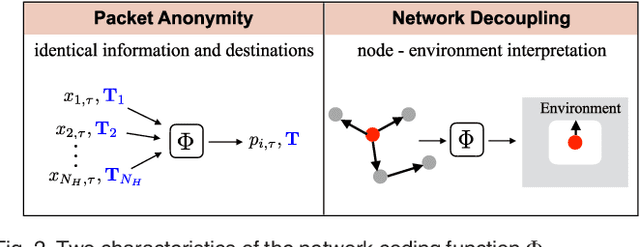

In this paper, we aim to find a robust network formation strategy that can adaptively evolve the network topology against network dynamics in a distributed manner. We consider a network coding deployed wireless ad hoc network where source nodes are connected to terminal nodes with the help of intermediate nodes. We show that mixing operations in network coding can induce packet anonymity that allows the inter-connections in a network to be decoupled. This enables each intermediate node to consider complex network inter-connections as a node-environment interaction such that the Markov decision process (MDP) can be employed at each intermediate node. The optimal policy that can be obtained by solving the MDP provides each node with optimal amount of changes in transmission range given network dynamics (e.g., the number of nodes in the range and channel condition). Hence, the network can be adaptively and optimally evolved by responding to the network dynamics. The proposed strategy is used to maximize long-term utility, which is achieved by considering both current network conditions and future network dynamics. We define the utility of an action to include network throughput gain and the cost of transmission power. We show that the resulting network of the proposed strategy eventually converges to stationary networks, which maintain the states of the nodes. Moreover, we propose to determine initial transmission ranges and initial network topology that can expedite the convergence of the proposed algorithm. Our simulation results confirm that the proposed strategy builds a network which adaptively changes its topology in the presence of network dynamics. Moreover, the proposed strategy outperforms existing strategies in terms of system goodput and successful connectivity ratio.