 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Recipe for Stable Offline Multi-agent Reinforcement Learning
Mar 09, 2026Despite remarkable achievements in single-agent offline reinforcement learning (RL), multi-agent RL (MARL) has struggled to adopt this paradigm, largely persisting with on-policy training and self-play from scratch. One reason for this gap comes from the instability of non-linear value decomposition, leading prior works to avoid complex mixing networks in favor of linear value decomposition (e.g., VDN) with value regularization used in single-agent setups. In this work, we analyze the source of instability in non-linear value decomposition within the offline MARL setting. Our observations confirm that they induce value-scale amplification and unstable optimization. To alleviate this, we propose a simple technique, scale-invariant value normalization (SVN), that stabilizes actor-critic training without altering the Bellman fixed point. Empirically, we examine the interaction among key components of offline MARL (e.g., value decomposition, value learning, and policy extraction) and derive a practical recipe that unlocks its full potential.
Multi-agent Coordination via Flow Matching
Nov 07, 2025This work presents MAC-Flow, a simple yet expressive framework for multi-agent coordination. We argue that requirements of effective coordination are twofold: (i) a rich representation of the diverse joint behaviors present in offline data and (ii) the ability to act efficiently in real time. However, prior approaches often sacrifice one for the other, i.e., denoising diffusion-based solutions capture complex coordination but are computationally slow, while Gaussian policy-based solutions are fast but brittle in handling multi-agent interaction. MAC-Flow addresses this trade-off by first learning a flow-based representation of joint behaviors, and then distilling it into decentralized one-step policies that preserve coordination while enabling fast execution. Across four different benchmarks, including $12$ environments and $34$ datasets, MAC-Flow alleviates the trade-off between performance and computational cost, specifically achieving about $\boldsymbol{\times14.5}$ faster inference compared to diffusion-based MARL methods, while maintaining good performance. At the same time, its inference speed is similar to that of prior Gaussian policy-based offline multi-agent reinforcement learning (MARL) methods.
Temporal Distance-aware Transition Augmentation for Offline Model-based Reinforcement Learning
May 19, 2025The goal of offline reinforcement learning (RL) is to extract a high-performance policy from the fixed datasets, minimizing performance degradation due to out-of-distribution (OOD) samples. Offline model-based RL (MBRL) is a promising approach that ameliorates OOD issues by enriching state-action transitions with augmentations synthesized via a learned dynamics model. Unfortunately, seminal offline MBRL methods often struggle in sparse-reward, long-horizon tasks. In this work, we introduce a novel MBRL framework, dubbed Temporal Distance-Aware Transition Augmentation (TempDATA), that generates augmented transitions in a temporally structured latent space rather than in raw state space. To model long-horizon behavior, TempDATA learns a latent abstraction that captures a temporal distance from both trajectory and transition levels of state space. Our experiments confirm that TempDATA outperforms previous offline MBRL methods and achieves matching or surpassing the performance of diffusion-based trajectory augmentation and goal-conditioned RL on the D4RL AntMaze, FrankaKitchen, CALVIN, and pixel-based FrankaKitchen.
Episodic Future Thinking Mechanism for Multi-agent Reinforcement Learning
Oct 22, 2024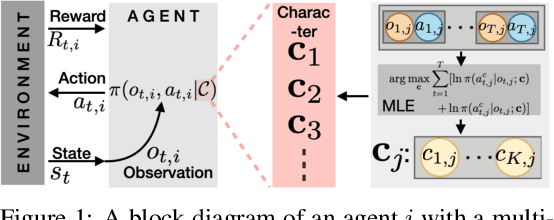
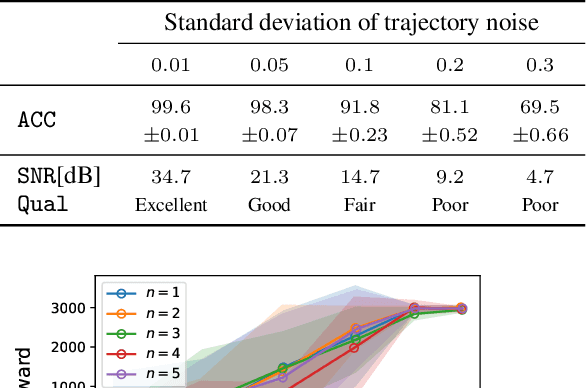
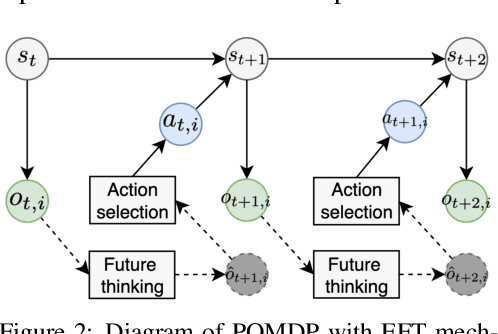
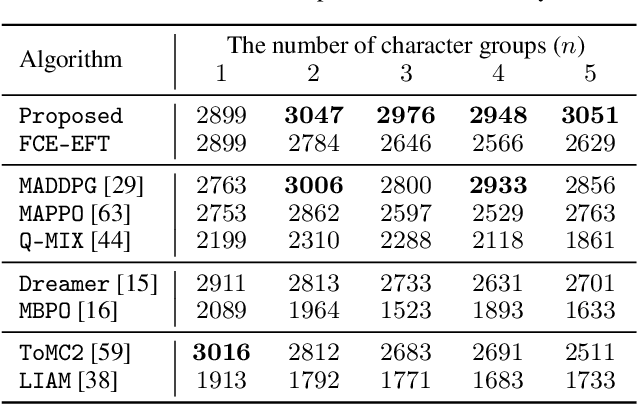
Understanding cognitive processes in multi-agent interactions is a primary goal in cognitive science. It can guide the direction of artificial intelligence (AI) research toward social decision-making in multi-agent systems, which includes uncertainty from character heterogeneity. In this paper, we introduce an episodic future thinking (EFT) mechanism for a reinforcement learning (RL) agent, inspired by cognitive processes observed in animals. To enable future thinking functionality, we first develop a multi-character policy that captures diverse characters with an ensemble of heterogeneous policies. Here, the character of an agent is defined as a different weight combination on reward components, representing distinct behavioral preferences. The future thinking agent collects observation-action trajectories of the target agents and uses the pre-trained multi-character policy to infer their characters. Once the character is inferred, the agent predicts the upcoming actions of target agents and simulates the potential future scenario. This capability allows the agent to adaptively select the optimal action, considering the predicted future scenario in multi-agent interactions. To evaluate the proposed mechanism, we consider the multi-agent autonomous driving scenario with diverse driving traits and multiple particle environments. Simulation results demonstrate that the EFT mechanism with accurate character inference leads to a higher reward than existing multi-agent solutions. We also confirm that the effect of reward improvement remains valid across societies with different levels of character diversity.
AD4RL: Autonomous Driving Benchmarks for Offline Reinforcement Learning with Value-based Dataset
Apr 03, 2024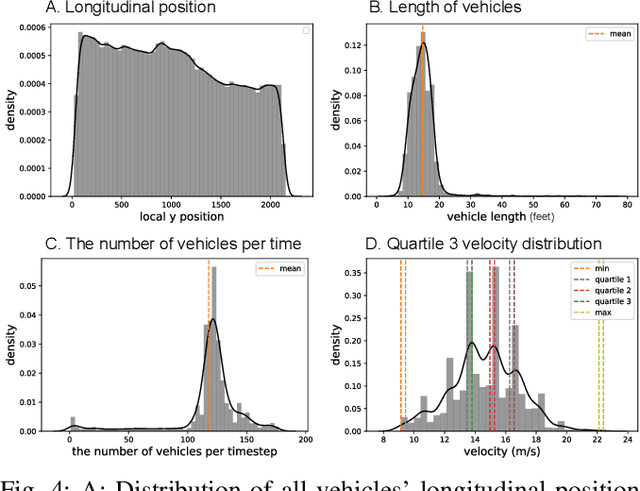
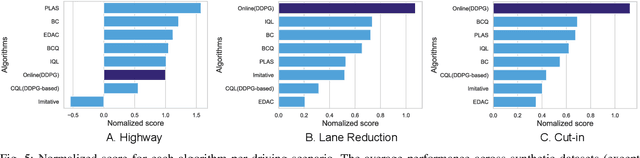
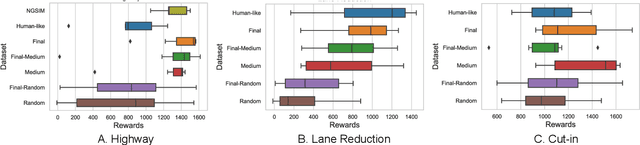
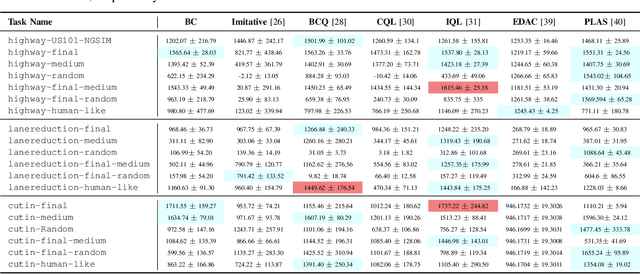
Offline reinforcement learning has emerged as a promising technology by enhancing its practicality through the use of pre-collected large datasets. Despite its practical benefits, most algorithm development research in offline reinforcement learning still relies on game tasks with synthetic datasets. To address such limitations, this paper provides autonomous driving datasets and benchmarks for offline reinforcement learning research. We provide 19 datasets, including real-world human driver's datasets, and seven popular offline reinforcement learning algorithms in three realistic driving scenarios. We also provide a unified decision-making process model that can operate effectively across different scenarios, serving as a reference framework in algorithm design. Our research lays the groundwork for further collaborations in the community to explore practical aspects of existing reinforcement learning methods. Dataset and codes can be found in https://sites.google.com/view/ad4rl.
A Lightweight Speaker Recognition System Using Timbre Properties
Oct 13, 2020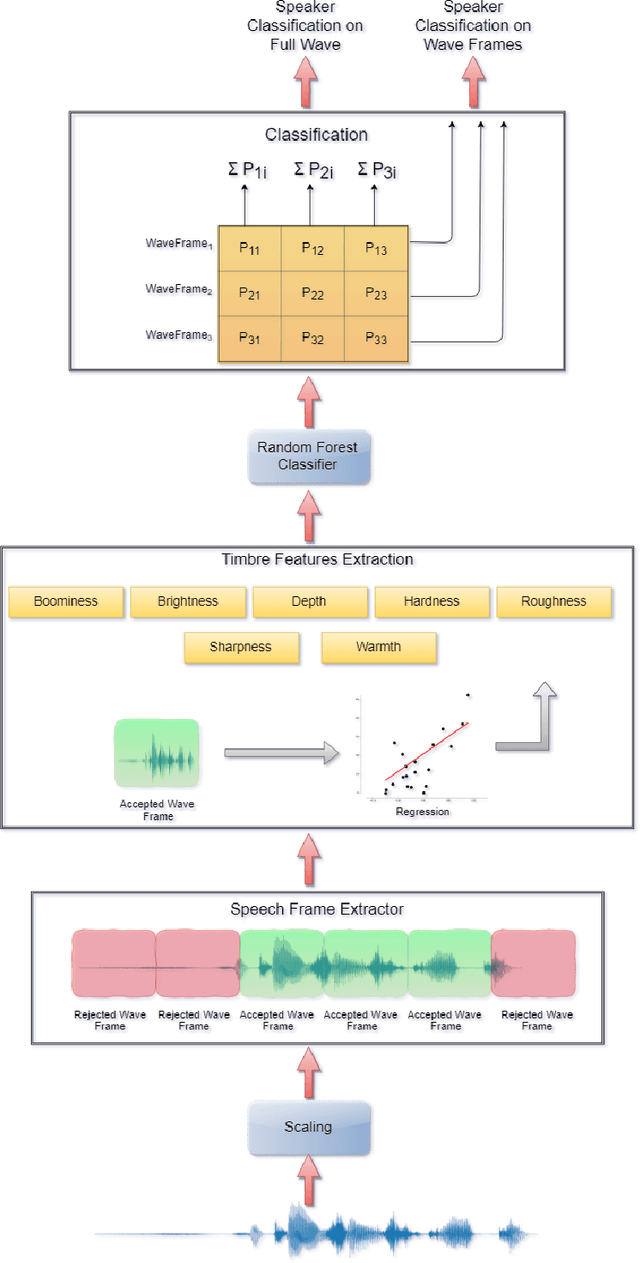
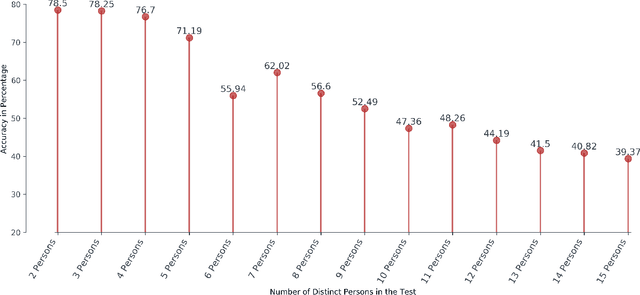
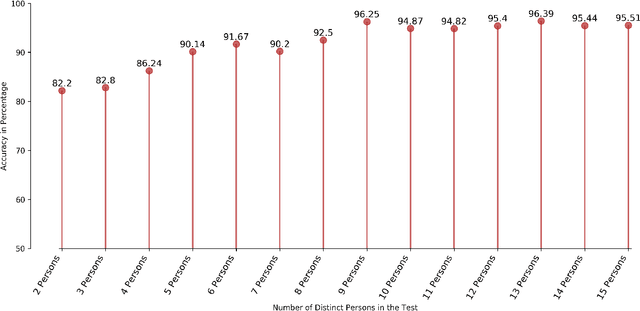
Speaker recognition is an active research area that contains notable usage in biometric security and authentication system. Currently, there exist many well-performing models in the speaker recognition domain. However, most of the advanced models implement deep learning that requires GPU support for real-time speech recognition, and it is not suitable for low-end devices. In this paper, we propose a lightweight text-independent speaker recognition model based on random forest classifier. It also introduces new features that are used for both speaker verification and identification tasks. The proposed model uses human speech based timbral properties as features that are classified using random forest. Timbre refers to the very basic properties of sound that allow listeners to discriminate among them. The prototype uses seven most actively searched timbre properties, boominess, brightness, depth, hardness, roughness, sharpness, and warmth as features of our speaker recognition model. The experiment is carried out on speaker verification and speaker identification tasks and shows the achievements and drawbacks of the proposed model. In the speaker identification phase, it achieves a maximum accuracy of 78%. On the contrary, in the speaker verification phase, the model maintains an accuracy of 80% having an equal error rate (ERR) of 0.24.
* Accepted in Journal of Contents Computing