 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and Opportunities of Speech Recognition for Bengali Language
Sep 27, 2021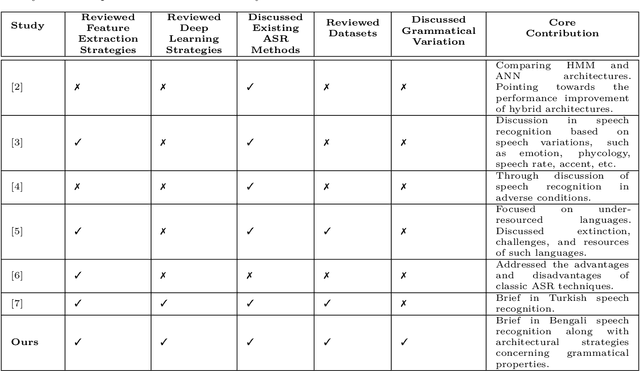

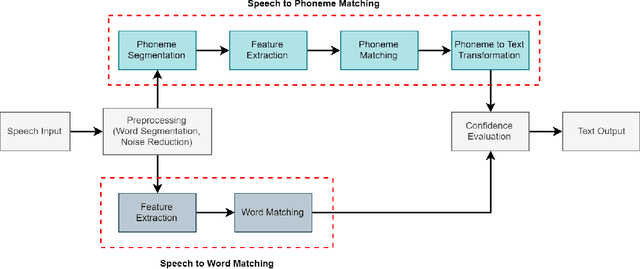
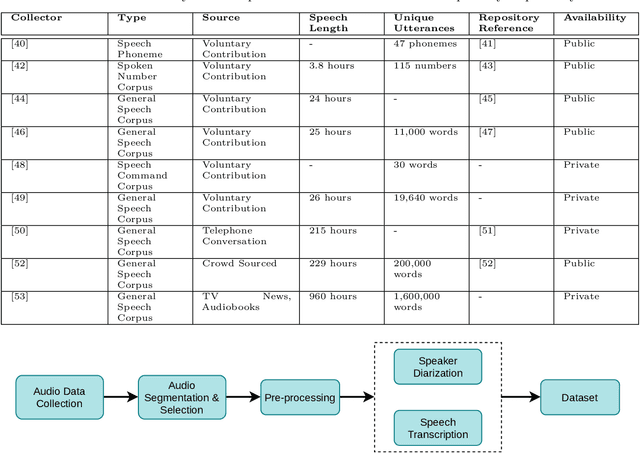
Speech recognition is a fascinating process that offers the opportunity to interact and command the machine in the field of human-computer interactions. Speech recognition is a language-dependent system constructed directly based on the linguistic and textual properties of any language. Automatic Speech Recognition (ASR) systems are currently being used to translate speech to text flawlessly. Although ASR systems are being strongly executed in international languages, ASR systems' implementation in the Bengali language has not reached an acceptable state. In this research work, we sedulously disclose the current status of the Bengali ASR system's research endeavors. In what follows, we acquaint the challenges that are mostly encountered while constructing a Bengali ASR system. We split the challenges into language-dependent and language-independent challenges and guide how the particular complications may be overhauled. Following a rigorous investigation and highlighting the challenges, we conclude that Bengali ASR systems require specific construction of ASR architectures based on the Bengali language's grammatical and phonetic structure.
End-to-End Optical Character Recognition for Bengali Handwritten Words
May 09, 2021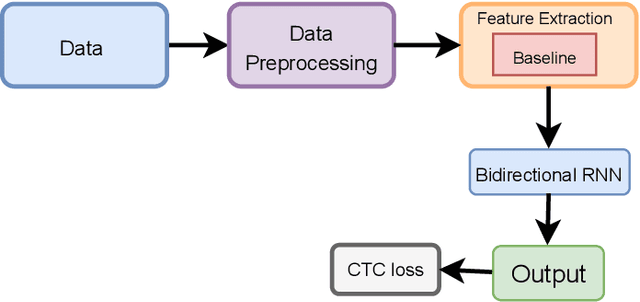

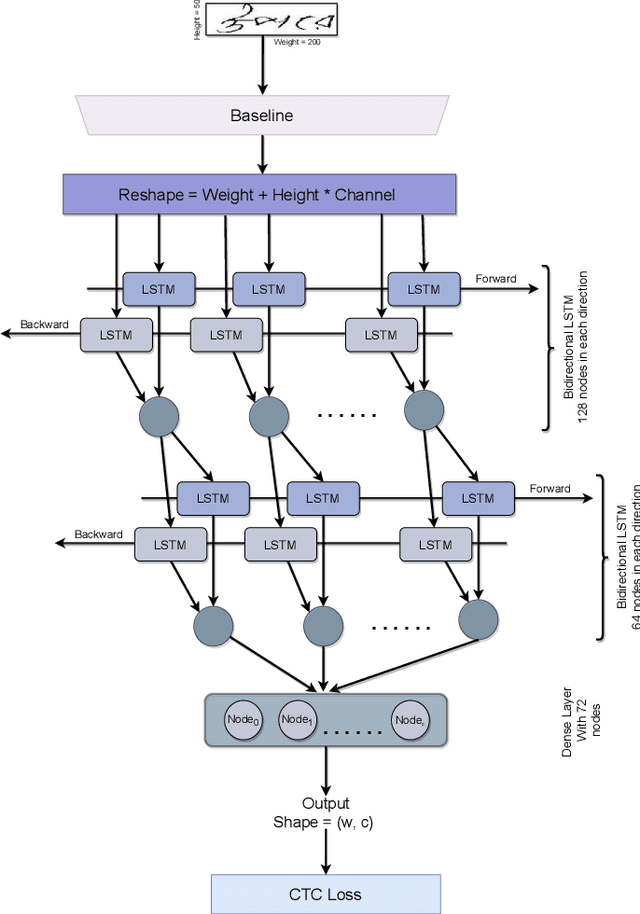
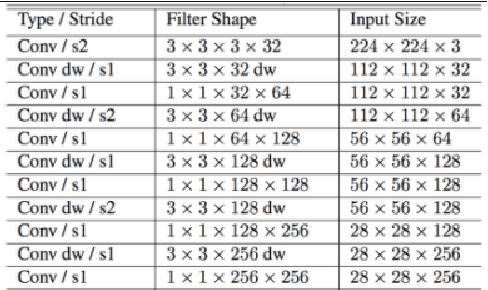
Optical character recognition (OCR) is a process of converting analogue documents into digital using document images. Currently, many commercial and non-commercial OCR systems exist for both handwritten and printed copies for different languages. Despite this, very few works are available in case of recognising Bengali words. Among them, most of the works focused on OCR of printed Bengali characters. This paper introduces an end-to-end OCR system for Bengali language. The proposed architecture implements an end to end strategy that recognises handwritten Bengali words from handwritten word images. We experiment with popular convolutional neural network (CNN) architectures, including DenseNet, Xception, NASNet, and MobileNet to build the OCR architecture. Further, we experiment with two different recurrent neural networks (RNN) methods, LSTM and GRU. We evaluate the proposed architecture using BanglaWritting dataset, which is a peer-reviewed Bengali handwritten image dataset. The proposed method achieves 0.091 character error rate and 0.273 word error rate performed using DenseNet121 model with GRU recurrent layer.
U-vectors: Generating clusterable speaker embedding from unlabeled data
Feb 07, 2021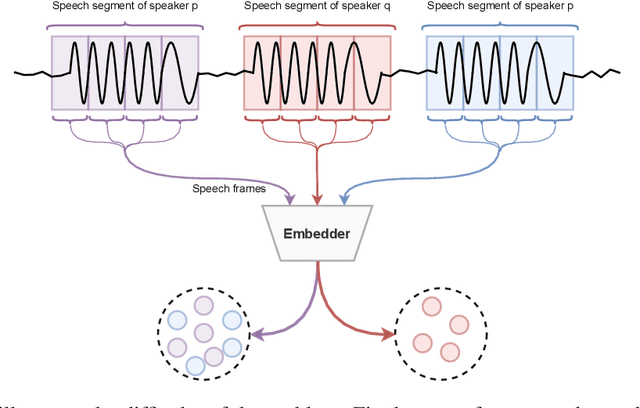

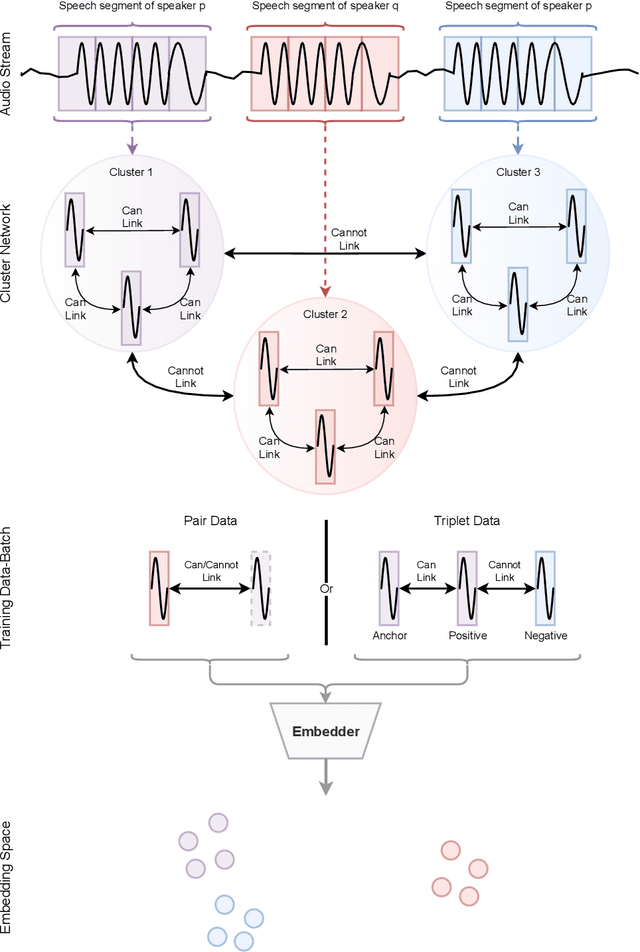
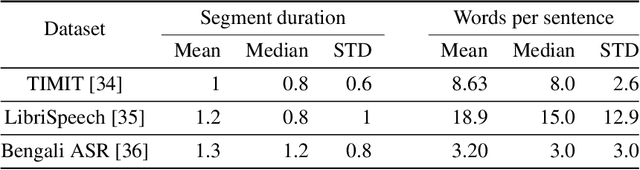
Speaker recognition deals with recognizing speakers by their speech. Strategies related to speaker recognition may explore speech timbre properties, accent, speech patterns and so on. Supervised speaker recognition has been dramatically investigated. However, through rigorous excavation, we have found that unsupervised speaker recognition systems mostly depend on domain adaptation policy. This paper introduces a speaker recognition strategy dealing with unlabeled data, which generates clusterable embedding vectors from small fixed-size speech frames. The unsupervised training strategy involves an assumption that a small speech segment should include a single speaker. Depending on such a belief, we construct pairwise constraints to train twin deep learning architectures with noise augmentation policies, that generate speaker embeddings. Without relying on domain adaption policy, the process unsupervisely produces clusterable speaker embeddings, and we name it unsupervised vectors (u-vectors). The evaluation is concluded in two popular speaker recognition datasets for English language, TIMIT, and LibriSpeech. Also, we include a Bengali dataset, Bengali ASR, to illustrate the diversity of the domain shifts for speaker recognition systems. Finally, we conclude that the proposed approach achieves remarkable performance using pairwise architectures.
FabricNet: A Fiber Recognition Architecture Using Ensemble ConvNets
Jan 14, 2021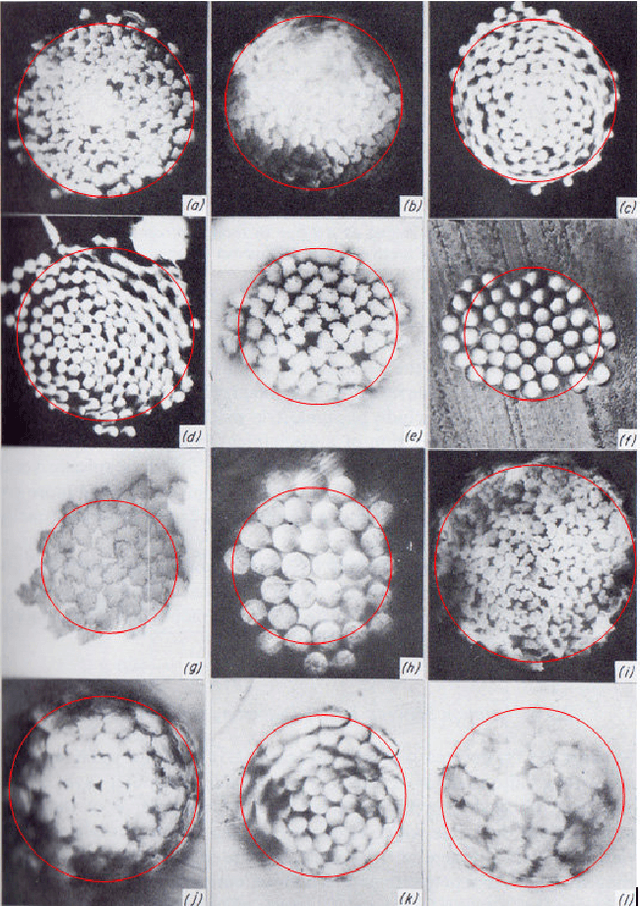


Fabric is a planar material composed of textile fibers. Textile fibers are generated from many natural sources; including plants, animals, minerals, and even, it can be synthetic. A particular fabric may contain different types of fibers that pass through a complex production process. Fiber identification is usually carried out through chemical tests and microscopic tests. However, these testing processes are complicated as well as time-consuming. We propose FabricNet, a pioneering approach for the image-based textile fiber recognition system, which may have a revolutionary impact from individual to the industrial fiber recognition process. The FabricNet can recognize a large scale of fibers by only utilizing a surface image of fabric. The recognition system is constructed using a distinct category of class-based ensemble convolutional neural network (CNN) architecture. The experiment is conducted on recognizing 50 different types of textile fibers. This experiment includes a significantly large number of unique textile fibers than previous research endeavors to the best of our knowledge. We experiment with popular CNN architectures that include Inception, ResNet, VGG, MobileNet, DenseNet, and Xception. Finally, the experimental results demonstrate that FabricNet outperforms the state-of-the-art popular CNN architectures by reaching an accuracy of 84% and F1-score of 90%.
A Lightweight Speaker Recognition System Using Timbre Properties
Oct 13, 2020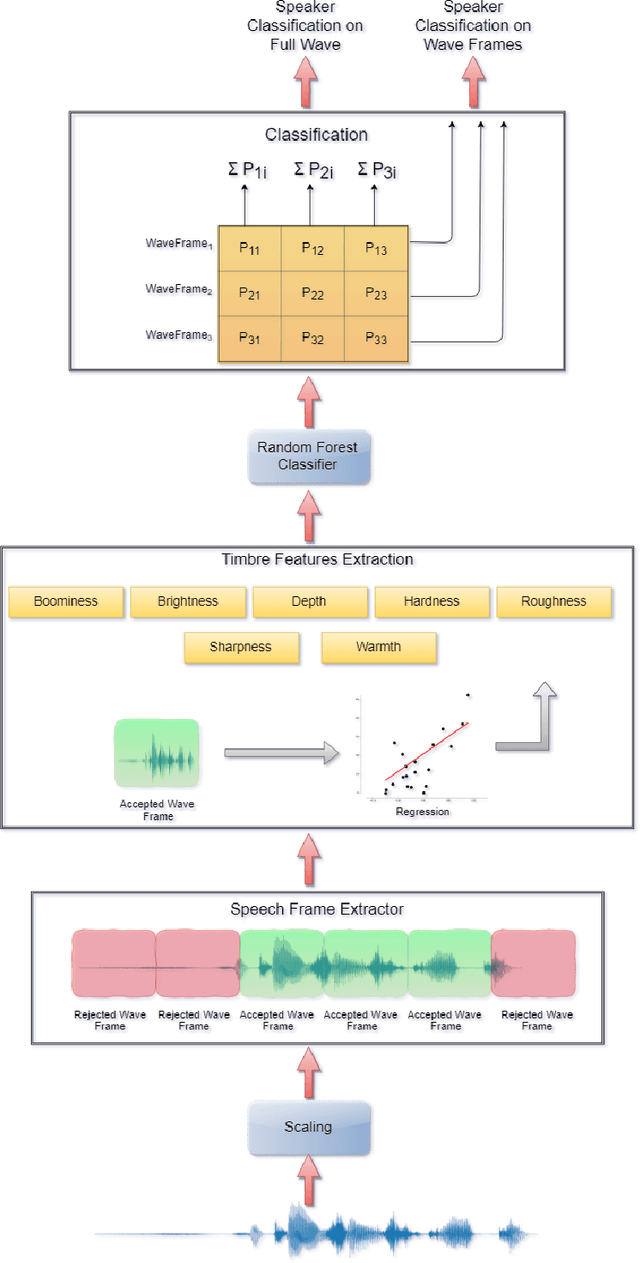
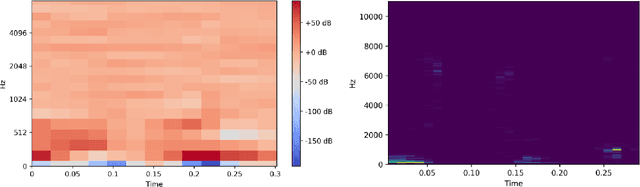
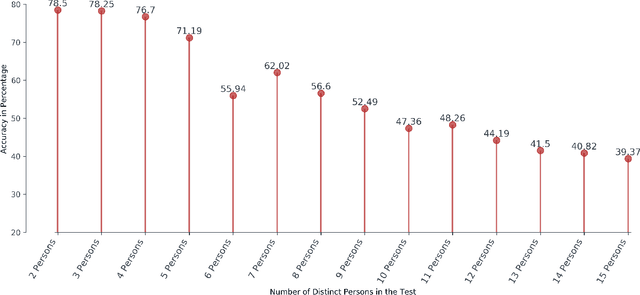
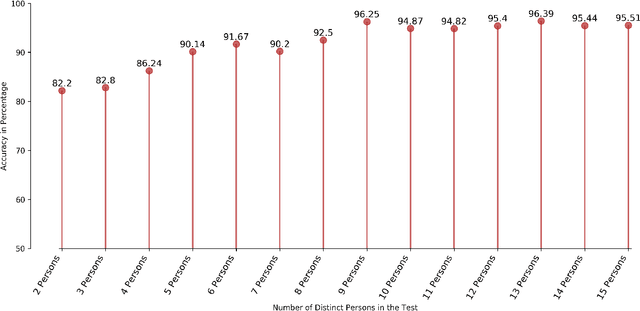
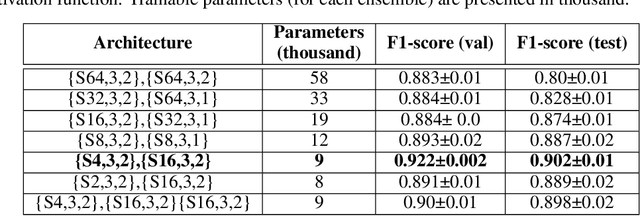
Speaker recognition is an active research area that contains notable usage in biometric security and authentication system. Currently, there exist many well-performing models in the speaker recognition domain. However, most of the advanced models implement deep learning that requires GPU support for real-time speech recognition, and it is not suitable for low-end devices. In this paper, we propose a lightweight text-independent speaker recognition model based on random forest classifier. It also introduces new features that are used for both speaker verification and identification tasks. The proposed model uses human speech based timbral properties as features that are classified using random forest. Timbre refers to the very basic properties of sound that allow listeners to discriminate among them. The prototype uses seven most actively searched timbre properties, boominess, brightness, depth, hardness, roughness, sharpness, and warmth as features of our speaker recognition model. The experiment is carried out on speaker verification and speaker identification tasks and shows the achievements and drawbacks of the proposed model. In the speaker identification phase, it achieves a maximum accuracy of 78%. On the contrary, in the speaker verification phase, the model maintains an accuracy of 80% having an equal error rate (ERR) of 0.24.
* Accepted in Journal of Contents Computing
AutoEmbedder: A semi-supervised DNN embedding system for clustering
Jul 11, 2020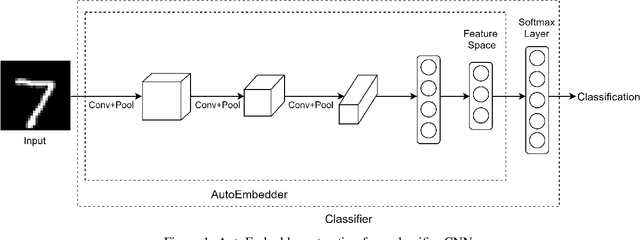

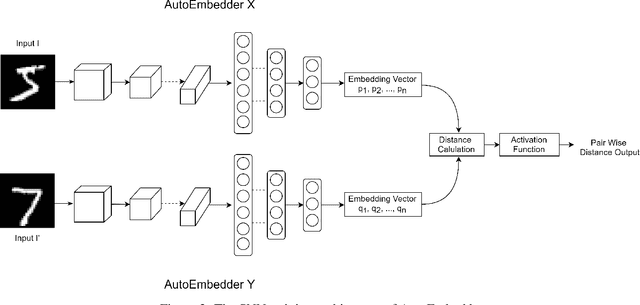

Clustering is widely used in unsupervised learning method that deals with unlabeled data. Deep clustering has become a popular study area that relates clustering with Deep Neural Network (DNN) architecture. Deep clustering method downsamples high dimensional data, which may also relate clustering loss. Deep clustering is also introduced in semi-supervised learning (SSL). Most SSL methods depend on pairwise constraint information, which is a matrix containing knowledge if data pairs can be in the same cluster or not. This paper introduces a novel embedding system named AutoEmbedder, that downsamples higher dimensional data to clusterable embedding points. To the best of our knowledge, this is the first research endeavor that relates to traditional classifier DNN architecture with a pairwise loss reduction technique. The training process is semi-supervised and uses Siamese network architecture to compute pairwise constraint loss in the feature learning phase. The AutoEmbedder outperforms most of the existing DNN based semi-supervised methods tested on famous datasets.
* The manuscript is accepted and published in Knowledge-Based System