 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-vectors: Generating clusterable speaker embedding from unlabeled data
Feb 07, 2021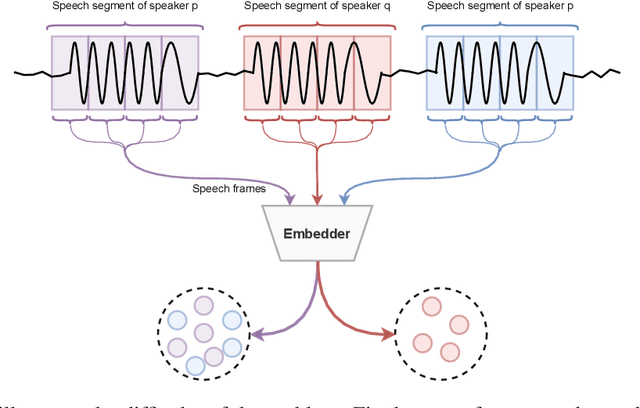

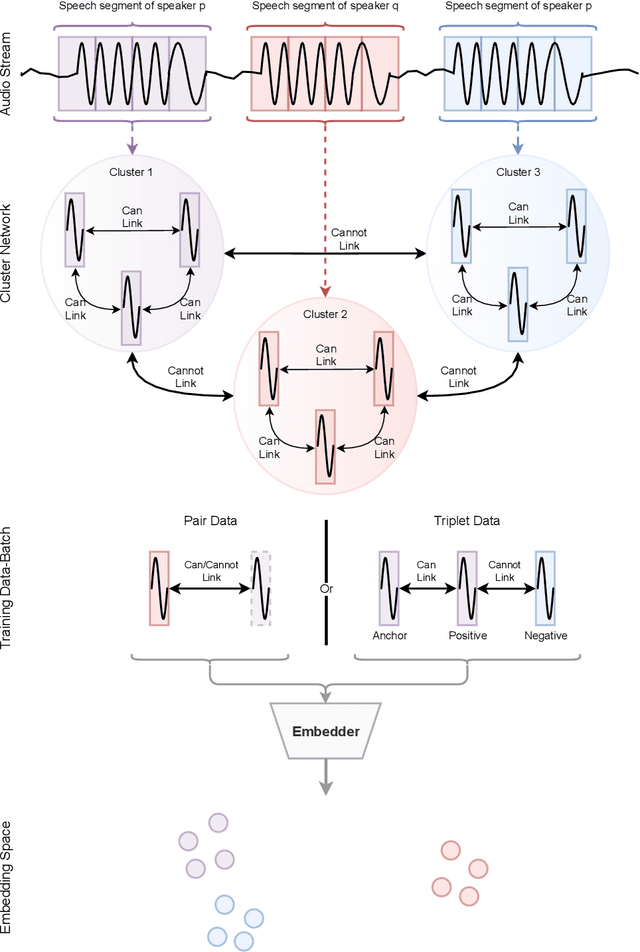
Speaker recognition deals with recognizing speakers by their speech. Strategies related to speaker recognition may explore speech timbre properties, accent, speech patterns and so on. Supervised speaker recognition has been dramatically investigated. However, through rigorous excavation, we have found that unsupervised speaker recognition systems mostly depend on domain adaptation policy. This paper introduces a speaker recognition strategy dealing with unlabeled data, which generates clusterable embedding vectors from small fixed-size speech frames. The unsupervised training strategy involves an assumption that a small speech segment should include a single speaker. Depending on such a belief, we construct pairwise constraints to train twin deep learning architectures with noise augmentation policies, that generate speaker embeddings. Without relying on domain adaption policy, the process unsupervisely produces clusterable speaker embeddings, and we name it unsupervised vectors (u-vectors). The evaluation is concluded in two popular speaker recognition datasets for English language, TIMIT, and LibriSpeech. Also, we include a Bengali dataset, Bengali ASR, to illustrate the diversity of the domain shifts for speaker recognition systems. Finally, we conclude that the proposed approach achieves remarkable performance using pairwise architectures.
BanglaWriting: A multi-purpose offline Bangla handwriting dataset
Dec 08, 2020


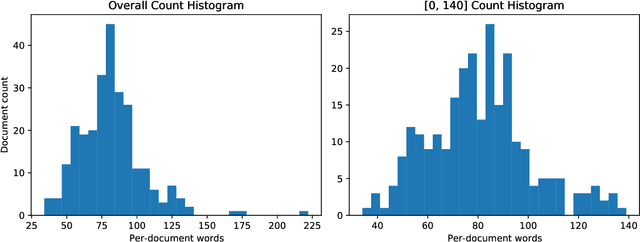
This article presents a Bangla handwriting dataset named BanglaWriting that contains single-page handwritings of 260 individuals of different personalities and ages. Each page includes bounding-boxes that bounds each word, along with the unicode representation of the writing. This dataset contains 21,234 words and 32,787 characters in total. Moreover, this dataset includes 5,470 unique words of Bangla vocabulary. Apart from the usual words, the dataset comprises 261 comprehensible overwriting and 450 handwritten strikes and mistakes. All of the bounding-boxes and word labels are manually-generated. The dataset can be used for complex optical character/word recognition, writer identification, handwritten word segmentation, and word generation. Furthermore, this dataset is suitable for extracting age-based and gender-based variation of handwriting.