 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Speaker Recognition System Using Timbre Properties
Paper and Code
Oct 13, 2020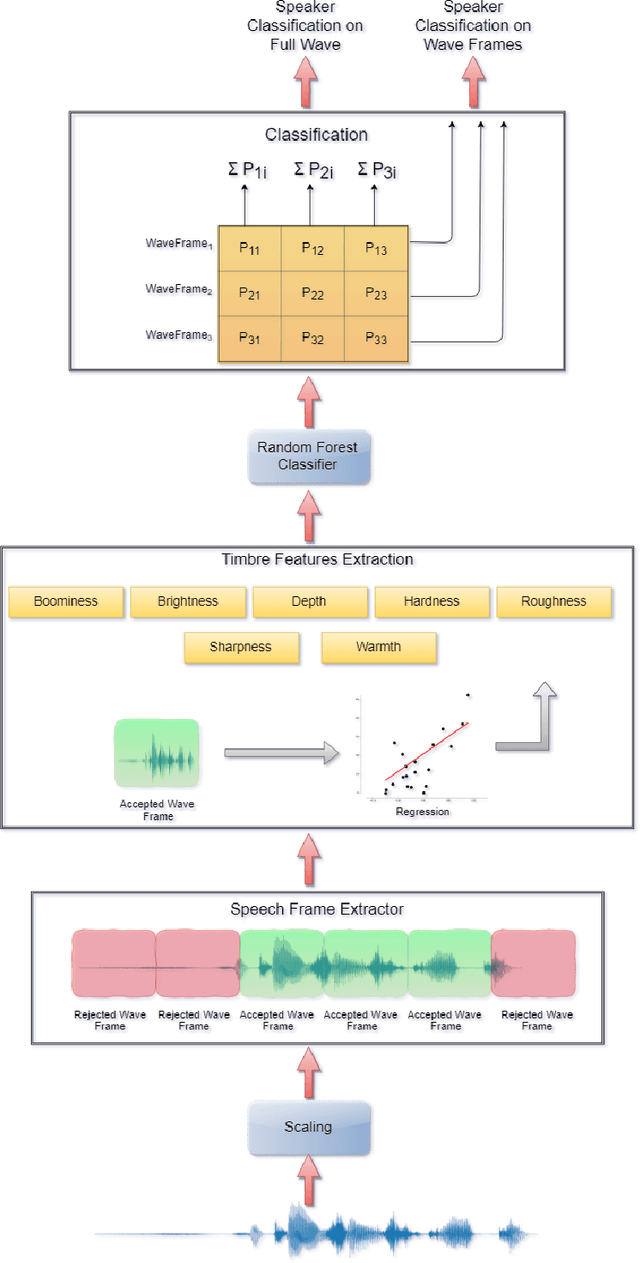
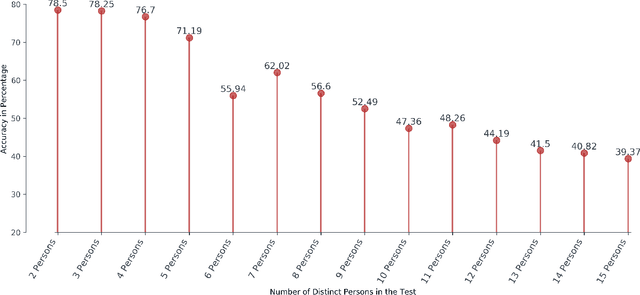
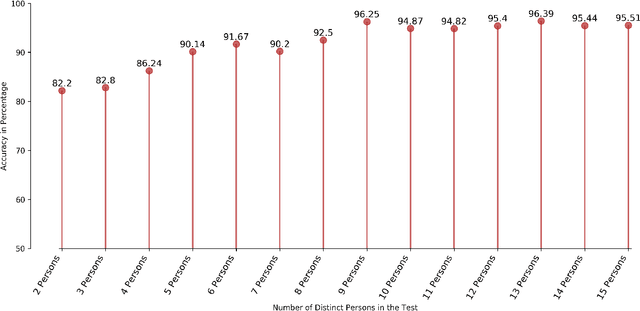
Speaker recognition is an active research area that contains notable usage in biometric security and authentication system. Currently, there exist many well-performing models in the speaker recognition domain. However, most of the advanced models implement deep learning that requires GPU support for real-time speech recognition, and it is not suitable for low-end devices. In this paper, we propose a lightweight text-independent speaker recognition model based on random forest classifier. It also introduces new features that are used for both speaker verification and identification tasks. The proposed model uses human speech based timbral properties as features that are classified using random forest. Timbre refers to the very basic properties of sound that allow listeners to discriminate among them. The prototype uses seven most actively searched timbre properties, boominess, brightness, depth, hardness, roughness, sharpness, and warmth as features of our speaker recognition model. The experiment is carried out on speaker verification and speaker identification tasks and shows the achievements and drawbacks of the proposed model. In the speaker identification phase, it achieves a maximum accuracy of 78%. On the contrary, in the speaker verification phase, the model maintains an accuracy of 80% having an equal error rate (ERR) of 0.24.