 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Optical Character Recognition for Bengali Handwritten Words
May 09, 2021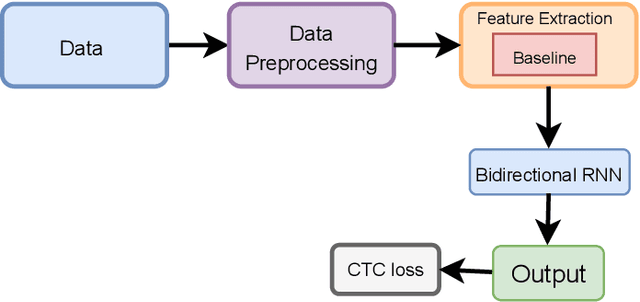

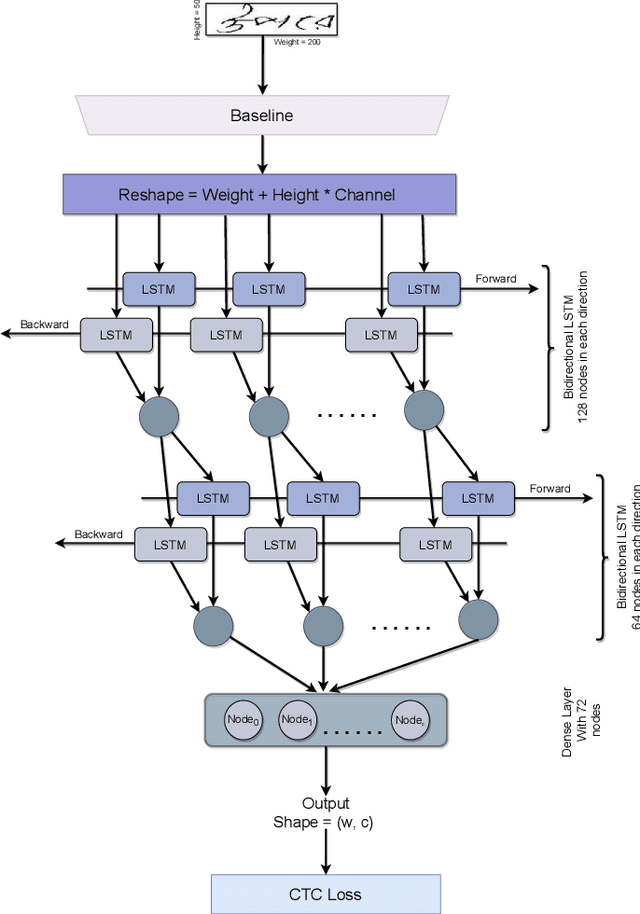
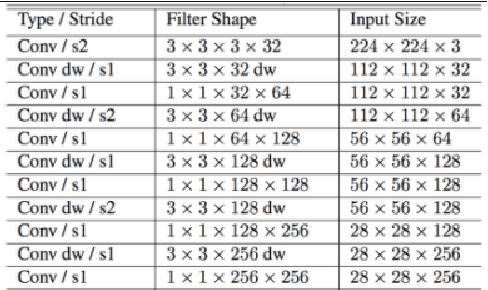
Optical character recognition (OCR) is a process of converting analogue documents into digital using document images. Currently, many commercial and non-commercial OCR systems exist for both handwritten and printed copies for different languages. Despite this, very few works are available in case of recognising Bengali words. Among them, most of the works focused on OCR of printed Bengali characters. This paper introduces an end-to-end OCR system for Bengali language. The proposed architecture implements an end to end strategy that recognises handwritten Bengali words from handwritten word images. We experiment with popular convolutional neural network (CNN) architectures, including DenseNet, Xception, NASNet, and MobileNet to build the OCR architecture. Further, we experiment with two different recurrent neural networks (RNN) methods, LSTM and GRU. We evaluate the proposed architecture using BanglaWritting dataset, which is a peer-reviewed Bengali handwritten image dataset. The proposed method achieves 0.091 character error rate and 0.273 word error rate performed using DenseNet121 model with GRU recurrent layer.
AutoEmbedder: A semi-supervised DNN embedding system for clustering
Jul 11, 2020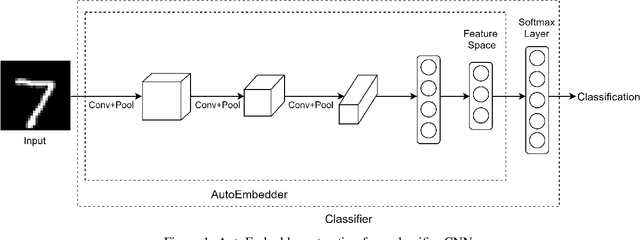

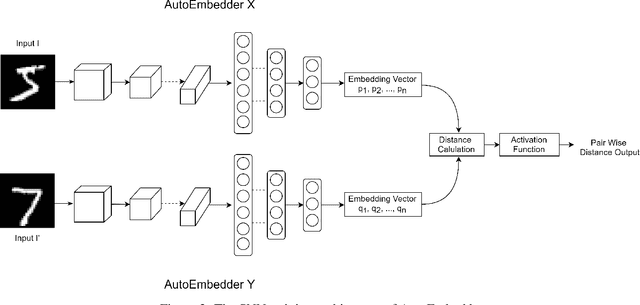

Clustering is widely used in unsupervised learning method that deals with unlabeled data. Deep clustering has become a popular study area that relates clustering with Deep Neural Network (DNN) architecture. Deep clustering method downsamples high dimensional data, which may also relate clustering loss. Deep clustering is also introduced in semi-supervised learning (SSL). Most SSL methods depend on pairwise constraint information, which is a matrix containing knowledge if data pairs can be in the same cluster or not. This paper introduces a novel embedding system named AutoEmbedder, that downsamples higher dimensional data to clusterable embedding points. To the best of our knowledge, this is the first research endeavor that relates to traditional classifier DNN architecture with a pairwise loss reduction technique. The training process is semi-supervised and uses Siamese network architecture to compute pairwise constraint loss in the feature learning phase. The AutoEmbedder outperforms most of the existing DNN based semi-supervised methods tested on famous datasets.
* The manuscript is accepted and published in Knowledge-Based System