 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Optical Character Recognition for Bengali Handwritten Words
Paper and Code
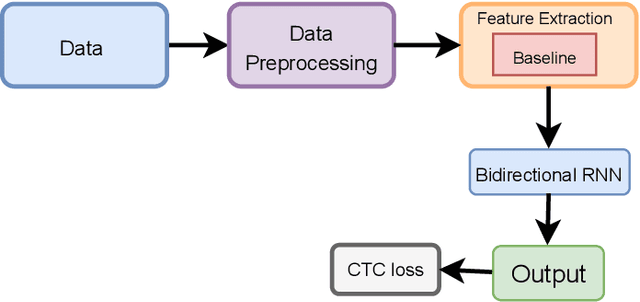

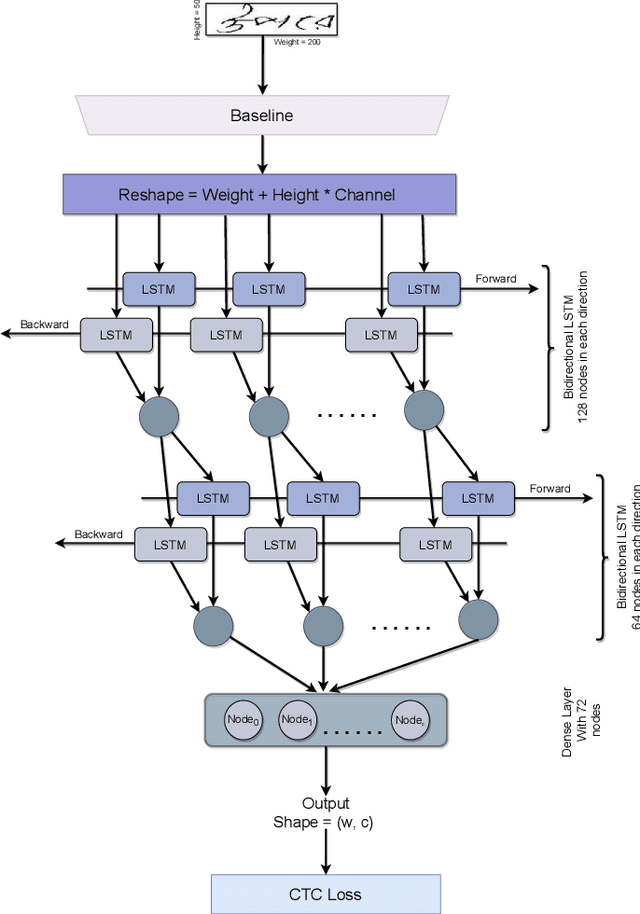
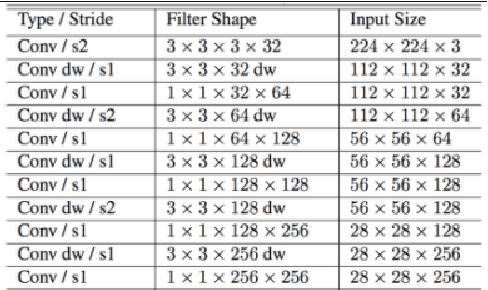
Optical character recognition (OCR) is a process of converting analogue documents into digital using document images. Currently, many commercial and non-commercial OCR systems exist for both handwritten and printed copies for different languages. Despite this, very few works are available in case of recognising Bengali words. Among them, most of the works focused on OCR of printed Bengali characters. This paper introduces an end-to-end OCR system for Bengali language. The proposed architecture implements an end to end strategy that recognises handwritten Bengali words from handwritten word images. We experiment with popular convolutional neural network (CNN) architectures, including DenseNet, Xception, NASNet, and MobileNet to build the OCR architecture. Further, we experiment with two different recurrent neural networks (RNN) methods, LSTM and GRU. We evaluate the proposed architecture using BanglaWritting dataset, which is a peer-reviewed Bengali handwritten image dataset. The proposed method achieves 0.091 character error rate and 0.273 word error rate performed using DenseNet121 model with GRU recurrent layer.