 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Representation
May 17, 2025Invariant representations are core to representation learning, yet a central challenge remains: uncovering invariants that are stable and transferable without suppressing task-relevant signals. This raises fundamental questions, requiring further inquiry, about the appropriate level of abstraction at which such invariants should be defined, and which aspects of a system they should characterize. Interpretation of the environment relies on abstract knowledge structures to make sense of the current state, which leads to interactions, essential drivers of learning and knowledge acquisition. We posit that interpretation operates at the level of higher-order relational knowledge; hence, invariant structures must be where knowledge resides, specifically, as partitions defined by the closure of relational paths within an abstract knowledge space. These partitions serve as the core invariant representations, forming the structural substrate where knowledge is stored and learning occurs. On the other hand, inter-partition connectors enable the deployment of these knowledge partitions encoding task-relevant transitions. Thus, invariant partitions provide the foundational primitives of structured representation. We formalize the computational foundations for structured representation of the invariant partitions based on closed semiring, a relational algebraic structure.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Control when confidence is costly
Jun 20, 2024



We develop a version of stochastic control that accounts for computational costs of inference. Past studies identified efficient coding without control, or efficient control that neglects the cost of synthesizing information. Here we combine these concepts into a framework where agents rationally approximate inference for efficient control. Specifically, we study Linear Quadratic Gaussian (LQG) control with an added internal cost on the relative precision of the posterior probability over the world state. This creates a trade-off: an agent can obtain more utility overall by sacrificing some task performance, if doing so saves enough bits during inference. We discover that the rational strategy that solves the joint inference and control problem goes through phase transitions depending on the task demands, switching from a costly but optimal inference to a family of suboptimal inferences related by rotation transformations, each misestimate the stability of the world. In all cases, the agent moves more to think less. This work provides a foundation for a new type of rational computations that could be used by both brains and machines for efficient but computationally constrained control.
KIX: A Metacognitive Generalization Framework
Feb 08, 2024Humans and other animals aptly exhibit general intelligence behaviors in solving a variety of tasks with flexibility and ability to adapt to novel situations by reusing and applying high level knowledge acquired over time. But artificial agents are more of a specialist, lacking such generalist behaviors. Artificial agents will require understanding and exploiting critical structured knowledge representations. We present a metacognitive generalization framework, Knowledge-Interaction-eXecution (KIX), and argue that interactions with objects leveraging type space facilitate the learning of transferable interaction concepts and generalization. It is a natural way of integrating knowledge into reinforcement learning and promising to act as an enabler for autonomous and generalist behaviors in artificial intelligence systems.
Linking Theories and Methods in Cognitive Sciences via Joint Embedding of the Scientific Literature: The Example of Cognitive Control
Mar 16, 2022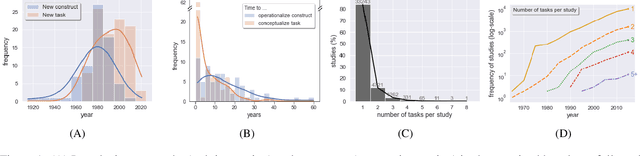
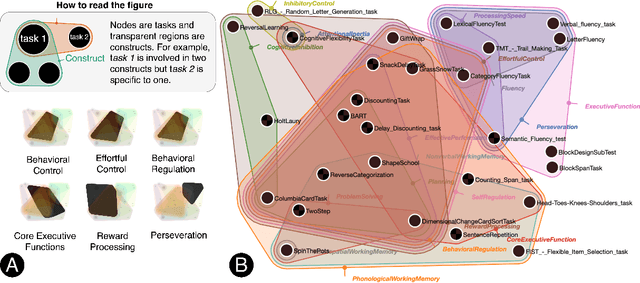
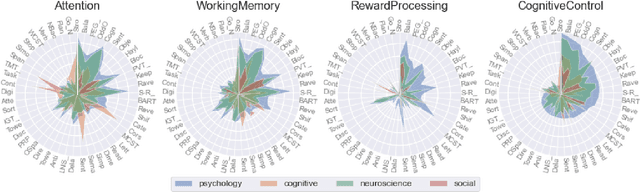
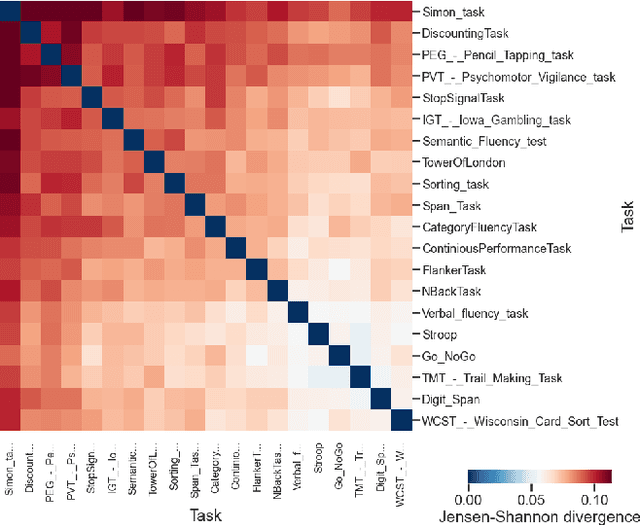
Traditionally, theory and practice of Cognitive Control are linked via literature reviews by human domain experts. This approach, however, is inadequate to track the ever-growing literature. It may also be biased, and yield redundancies and confusion. Here we present an alternative approach. We performed automated text analyses on a large body of scientific texts to create a joint representation of tasks and constructs. More specifically, 531,748 scientific abstracts were first mapped into an embedding space using a transformers-based language model. Document embeddings were then used to identify a task-construct graph embedding that grounds constructs on tasks and supports nuanced meaning of the constructs by taking advantage of constrained random walks in the graph. This joint task-construct graph embedding, can be queried to generate task batteries targeting specific constructs, may reveal knowledge gaps in the literature, and inspire new tasks and novel hypotheses.
Knowledge Sheaves: A Sheaf-Theoretic Framework for Knowledge Graph Embedding
Oct 07, 2021
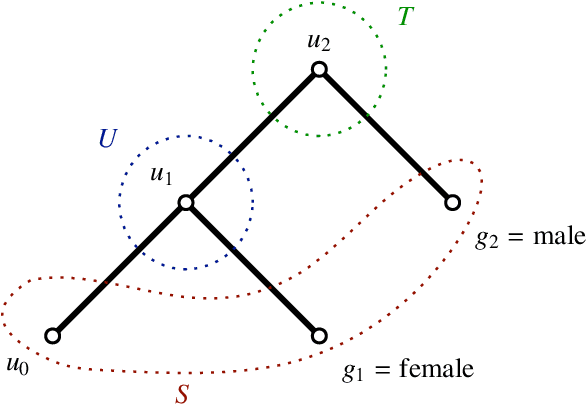


Knowledge graph embedding involves learning representations of entities -- the vertices of the graph -- and relations -- the edges of the graph -- such that the resulting representations encode the known factual information represented by the knowledge graph are internally consistent and can be used in the inference of new relations. We show that knowledge graph embedding is naturally expressed in the topological and categorical language of \textit{cellular sheaves}: learning a knowledge graph embedding corresponds to learning a \textit{knowledge sheaf} over the graph, subject to certain constraints. In addition to providing a generalized framework for reasoning about knowledge graph embedding models, this sheaf-theoretic perspective admits the expression of a broad class of prior constraints on embeddings and offers novel inferential capabilities. We leverage the recently developed spectral theory of sheaf Laplacians to understand the local and global consistency of embeddings and develop new methods for reasoning over composite relations through harmonic extension with respect to the sheaf Laplacian. We then implement these ideas to highlight the benefits of the extensions inspired by this new perspective.
A Unified Paths Perspective for Pruning at Initialization
Jan 26, 2021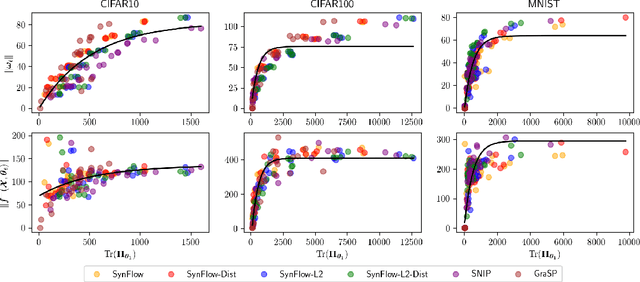

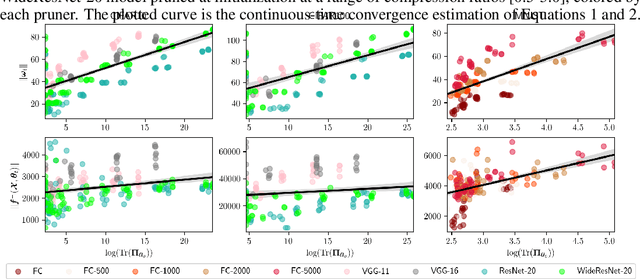

A number of recent approaches have been proposed for pruning neural network parameters at initialization with the goal of reducing the size and computational burden of models while minimally affecting their training dynamics and generalization performance. While each of these approaches have some amount of well-founded motivation, a rigorous analysis of the effect of these pruning methods on network training dynamics and their formal relationship to each other has thus far received little attention. Leveraging recent theoretical approximations provided by the Neural Tangent Kernel, we unify a number of popular approaches for pruning at initialization under a single path-centric framework. We introduce the Path Kernel as the data-independent factor in a decomposition of the Neural Tangent Kernel and show the global structure of the Path Kernel can be computed efficiently. This Path Kernel decomposition separates the architectural effects from the data-dependent effects within the Neural Tangent Kernel, providing a means to predict the convergence dynamics of a network from its architecture alone. We analyze the use of this structure in approximating training and generalization performance of networks in the absence of data across a number of initialization pruning approaches. Observing the relationship between input data and paths and the relationship between the Path Kernel and its natural norm, we additionally propose two augmentations of the SynFlow algorithm for pruning at initialization.
Inverse Rational Control with Partially Observable Continuous Nonlinear Dynamics
Sep 26, 2020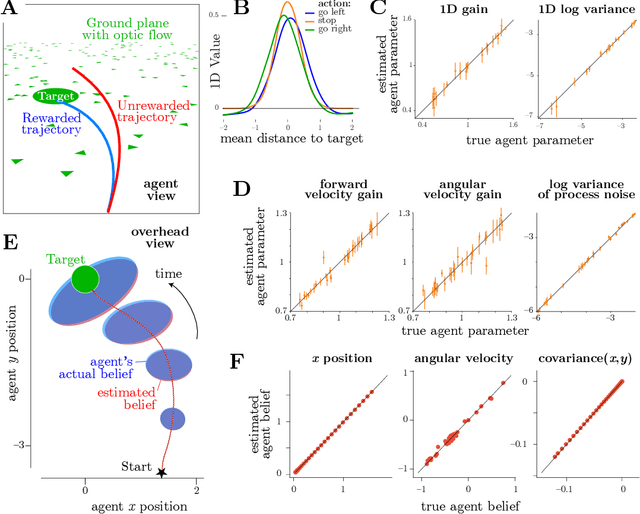
A fundamental question in neuroscience is how the brain creates an internal model of the world to guide actions using sequences of ambiguous sensory information. This is naturally formulated as a reinforcement learning problem under partial observations, where an agent must estimate relevant latent variables in the world from its evidence, anticipate possible future states, and choose actions that optimize total expected reward. This problem can be solved by control theory, which allows us to find the optimal actions for a given system dynamics and objective function. However, animals often appear to behave suboptimally. Why? We hypothesize that animals have their own flawed internal model of the world, and choose actions with the highest expected subjective reward according to that flawed model. We describe this behavior as rational but not optimal. The problem of Inverse Rational Control (IRC) aims to identify which internal model would best explain an agent's actions. Our contribution here generalizes past work on Inverse Rational Control which solved this problem for discrete control in partially observable Markov decision processes. Here we accommodate continuous nonlinear dynamics and continuous actions, and impute sensory observations corrupted by unknown noise that is private to the animal. We first build an optimal Bayesian agent that learns an optimal policy generalized over the entire model space of dynamics and subjective rewards using deep reinforcement learning. Crucially, this allows us to compute a likelihood over models for experimentally observable action trajectories acquired from a suboptimal agent. We then find the model parameters that maximize the likelihood using gradient ascent.
Belief dynamics extraction
Feb 02, 2019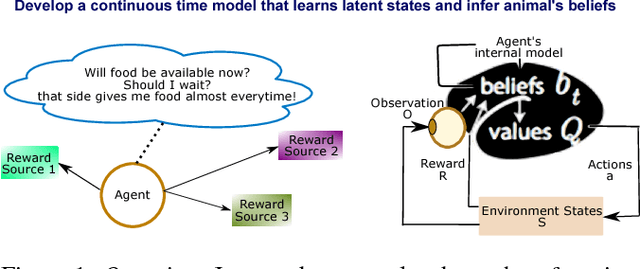
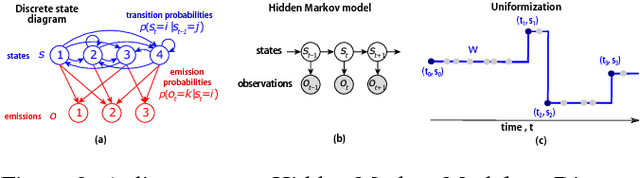
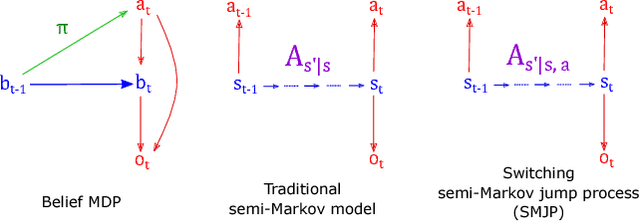

Animal behavior is not driven simply by its current observations, but is strongly influenced by internal states. Estimating the structure of these internal states is crucial for understanding the neural basis of behavior. In principle, internal states can be estimated by inverting behavior models, as in inverse model-based Reinforcement Learning. However, this requires careful parameterization and risks model-mismatch to the animal. Here we take a data-driven approach to infer latent states directly from observations of behavior, using a partially observable switching semi-Markov process. This process has two elements critical for capturing animal behavior: it captures non-exponential distribution of times between observations, and transitions between latent states depend on the animal's actions, features that require more complex non-markovian models to represent. To demonstrate the utility of our approach, we apply it to the observations of a simulated optimal agent performing a foraging task, and find that latent dynamics extracted by the model has correspondences with the belief dynamics of the agent. Finally, we apply our model to identify latent states in the behaviors of monkey performing a foraging task, and find clusters of latent states that identify periods of time consistent with expectant waiting. This data-driven behavioral model will be valuable for inferring latent cognitive states, and thereby for measuring neural representations of those states.