 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Information Bottleneck Denoised Multimedia Recommendation
Jan 21, 2025Empowered by semantic-rich content information, multimedia recommendation has emerged as a potent personalized technique. Current endeavors center around harnessing multimedia content to refine item representation or uncovering latent item-item structures based on modality similarity. Despite the effectiveness, we posit that these methods are usually suboptimal due to the introduction of irrelevant multimedia features into recommendation tasks. This stems from the fact that generic multimedia feature extractors, while well-designed for domain-specific tasks, can inadvertently introduce task-irrelevant features, leading to potential misguidance of recommenders. In this work, we propose a denoised multimedia recommendation paradigm via the Information Bottleneck principle (IB). Specifically, we propose a novel Information Bottleneck denoised Multimedia Recommendation (IBMRec) model to tackle the irrelevant feature issue. IBMRec removes task-irrelevant features from both feature and item-item structure perspectives, which are implemented by two-level IB learning modules: feature-level (FIB) and graph-level (GIB). In particular, FIB focuses on learning the minimal yet sufficient multimedia features. This is achieved by maximizing the mutual information between multimedia representation and recommendation tasks, while concurrently minimizing it between multimedia representation and pre-trained multimedia features. Furthermore, GIB is designed to learn the robust item-item graph structure, it refines the item-item graph based on preference affinity, then minimizes the mutual information between the original graph and the refined one. Extensive experiments across three benchmarks validate the effectiveness of our proposed model, showcasing high performance, and applicability to various multimedia recommenders.
Graph Disentangle Causal Model: Enhancing Causal Inference in Networked Observational Data
Dec 05, 2024



Estimating individual treatment effects (ITE) from observational data is a critical task across various domains. However, many existing works on ITE estimation overlook the influence of hidden confounders, which remain unobserved at the individual unit level. To address this limitation, researchers have utilized graph neural networks to aggregate neighbors' features to capture the hidden confounders and mitigate confounding bias by minimizing the discrepancy of confounder representations between the treated and control groups. Despite the success of these approaches, practical scenarios often treat all features as confounders and involve substantial differences in feature distributions between the treated and control groups. Confusing the adjustment and confounder and enforcing strict balance on the confounder representations could potentially undermine the effectiveness of outcome prediction. To mitigate this issue, we propose a novel framework called the \textit{Graph Disentangle Causal model} (GDC) to conduct ITE estimation in the network setting. GDC utilizes a causal disentangle module to separate unit features into adjustment and confounder representations. Then we design a graph aggregation module consisting of three distinct graph aggregators to obtain adjustment, confounder, and counterfactual confounder representations. Finally, a causal constraint module is employed to enforce the disentangled representations as true causal factors. The effectiveness of our proposed method is demonstrated by conducting comprehensive experiments on two networked datasets.
Long-tail Augmented Graph Contrastive Learning for Recommendation
Sep 20, 2023Graph Convolutional Networks (GCNs) has demonstrated promising results for recommender systems, as they can effectively leverage high-order relationship. However, these methods usually encounter data sparsity issue in real-world scenarios. To address this issue, GCN-based recommendation methods employ contrastive learning to introduce self-supervised signals. Despite their effectiveness, these methods lack consideration of the significant degree disparity between head and tail nodes. This can lead to non-uniform representation distribution, which is a crucial factor for the performance of contrastive learning methods. To tackle the above issue, we propose a novel Long-tail Augmented Graph Contrastive Learning (LAGCL) method for recommendation. Specifically, we introduce a learnable long-tail augmentation approach to enhance tail nodes by supplementing predicted neighbor information, and generate contrastive views based on the resulting augmented graph. To make the data augmentation schema learnable, we design an auto drop module to generate pseudo-tail nodes from head nodes and a knowledge transfer module to reconstruct the head nodes from pseudo-tail nodes. Additionally, we employ generative adversarial networks to ensure that the distribution of the generated tail/head nodes matches that of the original tail/head nodes. Extensive experiments conducted on three benchmark datasets demonstrate the significant improvement in performance of our model over the state-of-the-arts. Further analyses demonstrate the uniformity of learned representations and the superiority of LAGCL on long-tail performance. Code is publicly available at https://github.com/im0qianqian/LAGCL
Generative Contrastive Graph Learning for Recommendation
Jul 11, 2023



By treating users' interactions as a user-item graph, graph learning models have been widely deployed in Collaborative Filtering(CF) based recommendation. Recently, researchers have introduced Graph Contrastive Learning(GCL) techniques into CF to alleviate the sparse supervision issue, which first constructs contrastive views by data augmentations and then provides self-supervised signals by maximizing the mutual information between contrastive views. Despite the effectiveness, we argue that current GCL-based recommendation models are still limited as current data augmentation techniques, either structure augmentation or feature augmentation. First, structure augmentation randomly dropout nodes or edges, which is easy to destroy the intrinsic nature of the user-item graph. Second, feature augmentation imposes the same scale noise augmentation on each node, which neglects the unique characteristics of nodes on the graph. To tackle the above limitations, we propose a novel Variational Graph Generative-Contrastive Learning(VGCL) framework for recommendation. Specifically, we leverage variational graph reconstruction to estimate a Gaussian distribution of each node, then generate multiple contrastive views through multiple samplings from the estimated distributions, which builds a bridge between generative and contrastive learning. Besides, the estimated variances are tailored to each node, which regulates the scale of contrastive loss for each node on optimization. Considering the similarity of the estimated distributions, we propose a cluster-aware twofold contrastive learning, a node-level to encourage consistency of a node's contrastive views and a cluster-level to encourage consistency of nodes in a cluster. Finally, extensive experimental results on three public datasets clearly demonstrate the effectiveness of the proposed model.
Bandit Samplers for Training Graph Neural Networks
Jun 11, 2020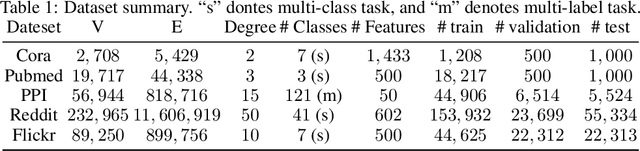
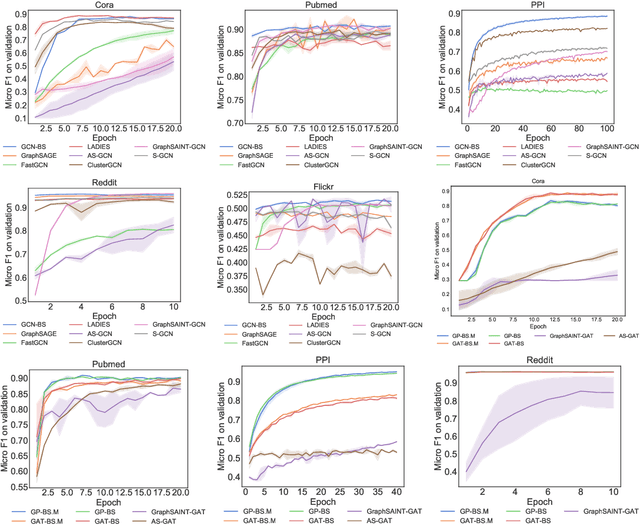
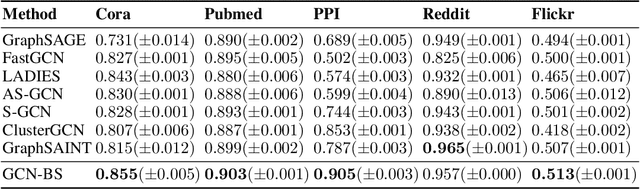
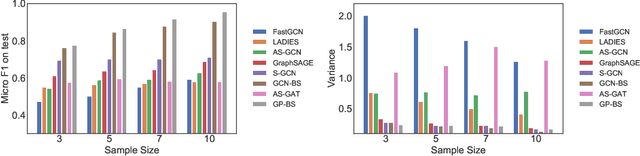
Several sampling algorithms with variance reduction have been proposed for accelerating the training of Graph Convolution Networks (GCNs). However, due to the intractable computation of optimal sampling distribution, these sampling algorithms are suboptimal for GCNs and are not applicable to more general graph neural networks (GNNs) where the message aggregator contains learned weights rather than fixed weights, such as Graph Attention Networks (GAT). The fundamental reason is that the embeddings of the neighbors or learned weights involved in the optimal sampling distribution are changing during the training and not known a priori, but only partially observed when sampled, thus making the derivation of an optimal variance reduced samplers non-trivial. In this paper, we formulate the optimization of the sampling variance as an adversary bandit problem, where the rewards are related to the node embeddings and learned weights, and can vary constantly. Thus a good sampler needs to acquire variance information about more neighbors (exploration) while at the same time optimizing the immediate sampling variance (exploit). We theoretically show that our algorithm asymptotically approaches the optimal variance within a factor of 3. We show the efficiency and effectiveness of our approach on multiple datasets.
Belief dynamics extraction
Feb 02, 2019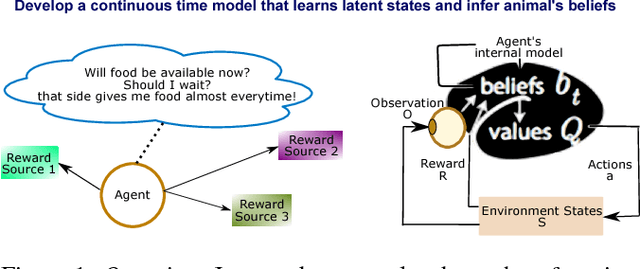
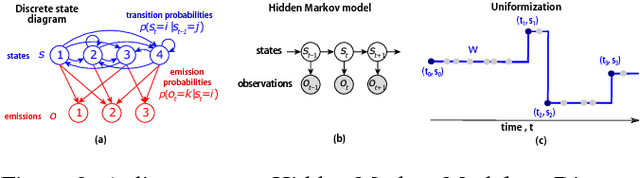
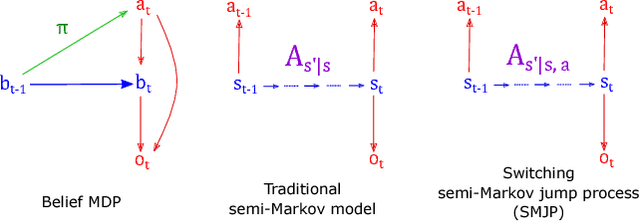

Animal behavior is not driven simply by its current observations, but is strongly influenced by internal states. Estimating the structure of these internal states is crucial for understanding the neural basis of behavior. In principle, internal states can be estimated by inverting behavior models, as in inverse model-based Reinforcement Learning. However, this requires careful parameterization and risks model-mismatch to the animal. Here we take a data-driven approach to infer latent states directly from observations of behavior, using a partially observable switching semi-Markov process. This process has two elements critical for capturing animal behavior: it captures non-exponential distribution of times between observations, and transitions between latent states depend on the animal's actions, features that require more complex non-markovian models to represent. To demonstrate the utility of our approach, we apply it to the observations of a simulated optimal agent performing a foraging task, and find that latent dynamics extracted by the model has correspondences with the belief dynamics of the agent. Finally, we apply our model to identify latent states in the behaviors of monkey performing a foraging task, and find clusters of latent states that identify periods of time consistent with expectant waiting. This data-driven behavioral model will be valuable for inferring latent cognitive states, and thereby for measuring neural representations of those states.
Inverse POMDP: Inferring What You Think from What You Do
Oct 07, 2018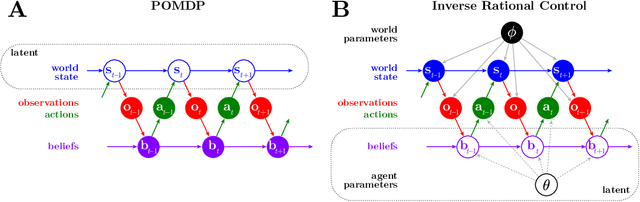
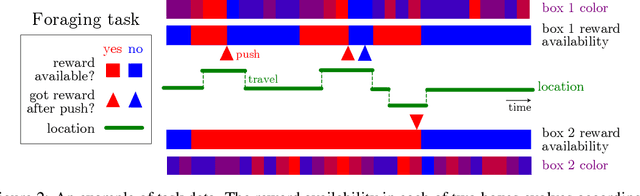
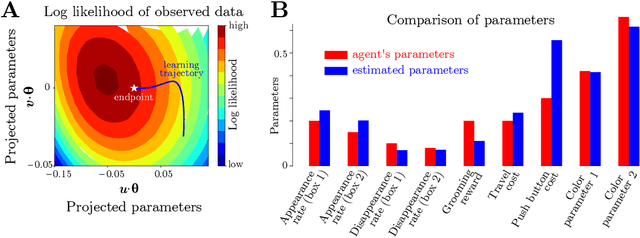
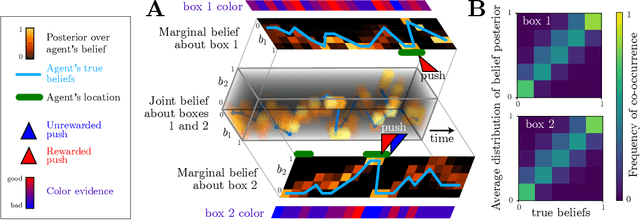
Complex behaviors are often driven by an internal model, which integrates sensory information over time and facilitates long-term planning. Inferring the internal model is a crucial ingredient for interpreting neural activities of agents and is beneficial for imitation learning. Here we describe a method to infer an agent's internal model and dynamic beliefs, and apply it to a simulated agent performing a foraging task. We assume the agent behaves rationally according to their understanding of the task and the relevant causal variables that cannot be fully observed. We model this rational solution as a Partially Observable Markov Decision Process (POMDP). However, we allow that the agent may have wrong assumptions about the task, and our method learns these assumptions from the agent's actions. Given the agent's sensory observations and actions, we learn its internal model by maximum likelihood estimation over a set of task-relevant parameters. The Markov property of the POMDP enables us to characterize the transition probabilities between internal states and iteratively estimate the agent's policy using a constrained Expectation-Maximization(EM) algorithm. We validate our method on simulated agents performing suboptimally on a foraging task, and successfully recover the agent's actual model.
Store Location Selection via Mining Search Query Logs of Baidu Maps
Jun 12, 2016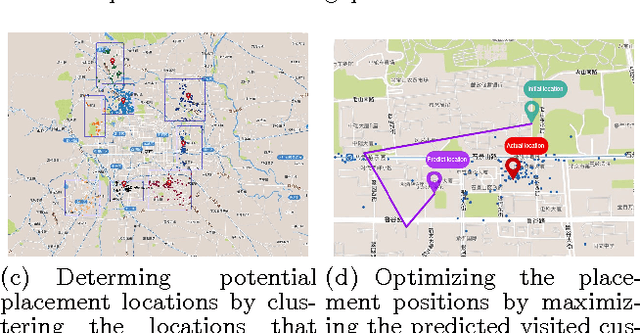
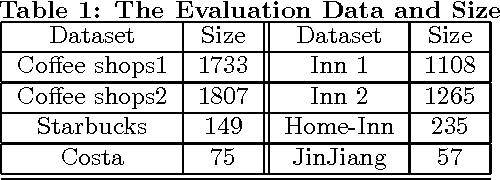
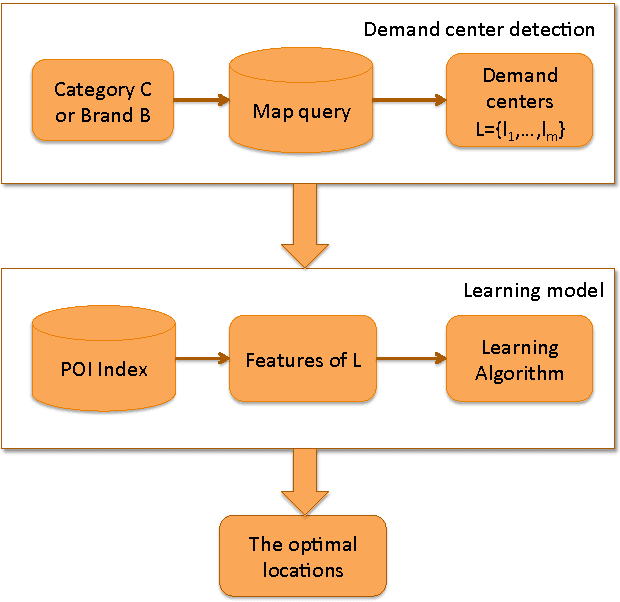
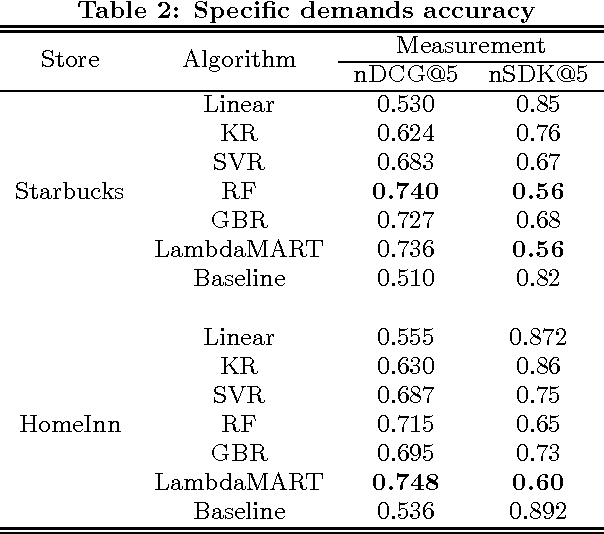
Choosing a good location when opening a new store is crucial for the future success of a business. Traditional methods include offline manual survey, which is very time consuming, and analytic models based on census data, which are un- able to adapt to the dynamic market. The rapid increase of the availability of big data from various types of mobile devices, such as online query data and offline positioning data, provides us with the possibility to develop automatic and accurate data-driven prediction models for business store placement. In this paper, we propose a Demand Distribution Driven Store Placement (D3SP) framework for business store placement by mining search query data from Baidu Maps. D3SP first detects the spatial-temporal distributions of customer demands on different business services via query data from Baidu Maps, the largest online map search engine in China, and detects the gaps between demand and sup- ply. Then we determine candidate locations via clustering such gaps. In the final stage, we solve the location optimization problem by predicting and ranking the number of customers. We not only deploy supervised regression models to predict the number of customers, but also learn to rank models to directly rank the locations. We evaluate our framework on various types of businesses in real-world cases, and the experiments results demonstrate the effectiveness of our methods. D3SP as the core function for store placement has already been implemented as a core component of our business analytics platform and could be potentially used by chain store merchants on Baidu Nuomi.